Vyhodnocení, který architektonický vzor streamování nejlépe odpovídá vašemu případu použití, je předpokladem úspěšného produkčního nasazení.
Ekosystém Apache Hadoop se stal preferovanou platformou pro podniky, které chtějí zpracovávat a porozumět rozsáhlým datům v reálném čase. Technologie jako Apache Kafka, Apache Flume, Apache Spark, Apache Storm a Apache Samza stále více posouvají hranice toho, co je možné. Často je lákavé dát dohromady případy použití streamování ve velkém měřítku, ale ve skutečnosti mají tendenci se rozpadat do několika různých architektonických vzorů s různými složkami ekosystému, které se lépe hodí pro různé problémy.
V tomto příspěvku nastíním čtyři hlavní vzory streamování, se kterými jsme se setkali u zákazníků provozujících podniková datová centra v produkci, a vysvětlím, jak tyto vzory architektonicky implementovat na Hadoop.
Vzory streamování
Čtyři základní vzory streamování (často používané v tandemu) jsou:
- Zpracování streamu: Zahrnuje přetrvávání událostí s nízkou latencí do HDFS, Apache HBase a Apache Solr.
- Zpracování událostí v téměř reálném čase (NRT) s externím kontextem: Provádí akce, jako je upozornění, označení, transformace a filtrování událostí, jakmile přijdou. Opatření mohou být přijata na základě sofistikovaných kritérií, jako jsou modely detekce anomálií. Běžné případy použití, jako je detekce podvodů NRT a doporučení, často vyžadují nízké latence pod 100 milisekund.
- NRT Event Partitioned Processing: Podobné jako u zpracování událostí NRT, ale výhody plynoucí z rozdělení dat – jako ukládání relevantnějších externích informací do paměti. Tento vzor také vyžaduje zpoždění zpracování menší než 100 milisekund.
- Komplexní topologie pro agregace nebo ML: Svatý grál zpracování datových proudů:získává odpovědi z dat v reálném čase pomocí komplexní a flexibilní sady operací. Protože výsledky často závisí na výpočtech v okně a vyžadují aktivnější data, zaměření se přesouvá z ultra nízké latence na funkčnost a přesnost.
V následujících částech se podíváme na doporučené způsoby implementace takových vzorů otestovaným, ověřeným a udržitelným způsobem.
Streamování
Tradičně byl Flume doporučeným systémem pro streamování příjmu potravy. Jeho velká knihovna zdrojů a jímek pokrývá všechny základy toho, co konzumovat a kam psát. (Podrobnosti o tom, jak nakonfigurovat a spravovat Flume, Používání Flume , kniha O’Reilly Media od softwarového inženýra Cloudera/člena Flume PMC Hariho Shreedharana, je skvělým zdrojem.)
Během posledního roku se Kafka stala populární také díky výkonným funkcím, jako je přehrávání a replikace. Kvůli překrývání mezi Flumeovými a Kafkovými cíli je jejich vztah často matoucí. Jak se k sobě hodí? Odpověď je jednoduchá:Kafka je dýmka podobná abstrakci Flume’s Channel, i když lepší dýmka, protože podporuje výše uvedené funkce. Jedním z běžných přístupů je použití Flume pro zdroj a jímku a Kafka pro potrubí mezi nimi.
Níže uvedený diagram ukazuje, jak může Kafka sloužit jako Upstreamový zdroj dat pro Flume, downstreamový cíl Flume nebo kanál Flume.
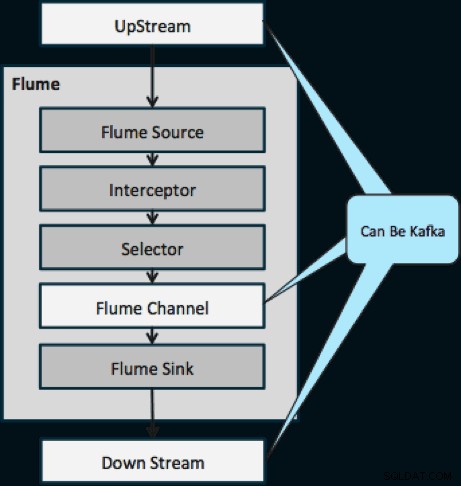
Návrh znázorněný níže je masivně škálovatelný, odolný proti bitvě, centrálně monitorovaný pomocí Cloudera Manager, odolný proti chybám a podporuje přehrávání.
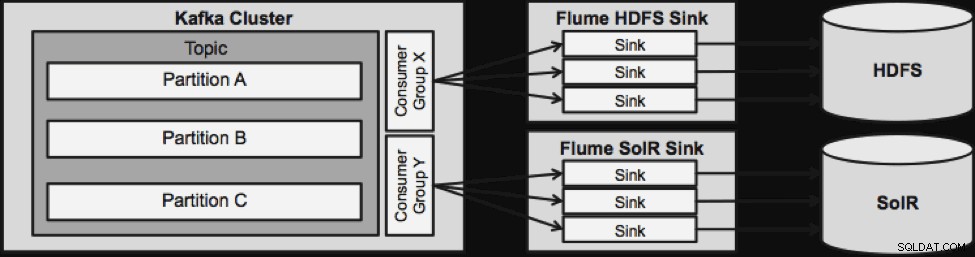
Jedna věc, kterou je třeba poznamenat, než přejdeme k další architektuře streamování, je to, jak tento návrh elegantně zvládá selhání. Flume Sinks pochází od skupiny spotřebitelů Kafka. Skupina spotřebitelů sleduje offset tématu s pomocí Apache ZooKeeper. Pokud dojde ke ztrátě žlabu, spotřebitel Kafka přerozdělí zátěž do zbývajících dřezů. Když se žlab vrátí nahoru, skupina spotřebitelů bude znovu distribuovat.
Zpracování událostí NRT s externím kontextem
Abychom to zopakovali, běžným případem použití tohoto vzoru je podívat se na události, které proudí dovnitř, a učinit okamžitá rozhodnutí, buď transformovat data, nebo podniknout nějaký druh externí akce. Logika rozhodování často závisí na externích profilech nebo metadatech. Snadný a škálovatelný způsob implementace tohoto přístupu je přidat do vaší architektury Kafka/Flume zachycovač Source nebo Sink Flume. Se skromným laděním není obtížné dosáhnout latence v nízkých milisekundách.
Flume Interceptory přijímají události nebo dávky událostí a umožňují uživatelskému kódu modifikovat nebo provádět akce na jejich základě. Uživatelský kód může interagovat s místní pamětí nebo externím úložným systémem, jako je HBase, aby získal informace o profilu potřebné pro rozhodování. HBase nám obvykle může poskytnout naše informace přibližně za 4–25 milisekund v závislosti na síti, návrhu schématu a konfiguraci. HBase můžete také nastavit tak, aby nikdy nedocházelo k výpadku nebo přerušení, a to ani v případě selhání.
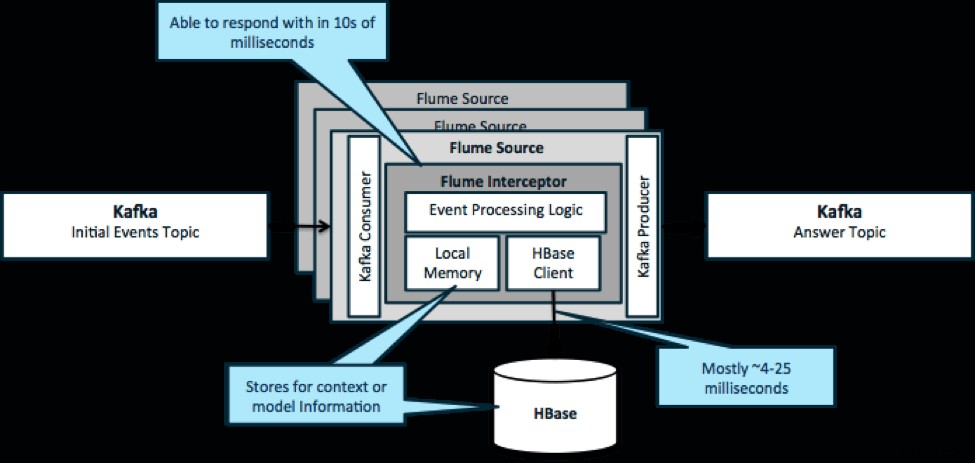
Implementace nevyžaduje téměř žádné kódování nad rámec aplikačně specifické logiky v interceptoru. Cloudera Manager nabízí intuitivní uživatelské rozhraní pro nasazení této logiky prostřednictvím pozemků a také připojení, konfiguraci a monitorování služeb.
Zpracování rozdělených událostí NRT s externím kontextem
V architektuře znázorněné níže (nerozdělené řešení) byste museli často volat na HBase, protože externí kontext relevantní pro konkrétní události se nevejde do místní paměti na interceptorech Flume.
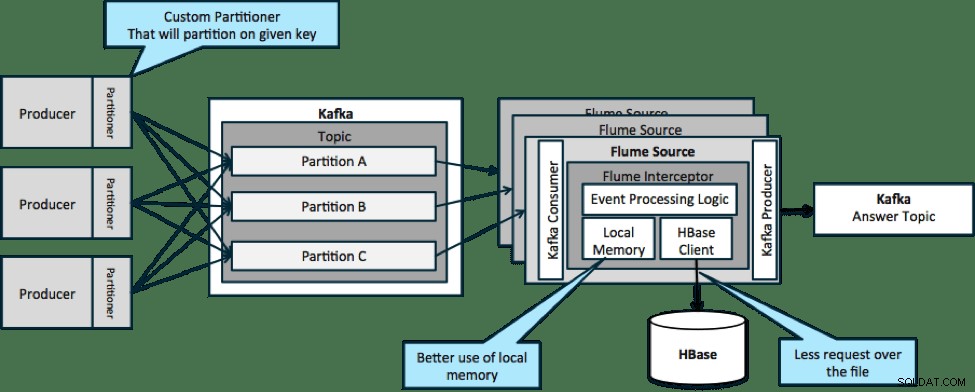
Pokud však definujete klíč pro rozdělení dat, můžete příchozí data porovnat s podmnožinou kontextových dat, která jsou pro ně relevantní. Pokud rozdělíte data 10krát, pak budete potřebovat pouze 1/10 profilů v paměti. HBase je rychlá, ale místní paměť je rychlejší. Kafka vám umožňuje definovat vlastní oddíl, který používá k rozdělení vašich dat.
Všimněte si, že Flume zde není nezbytně nutný; kořenové řešení zde pouze spotřebitel Kafka. Můžete tedy použít pouze spotřebitele v YARN nebo aplikaci MapReduce pouze pro Mapy.
Komplexní topologie pro agregace nebo ML
Do této chvíle jsme zkoumali operace na úrovni událostí. Někdy však potřebujete složitější operace, jako jsou počty, průměry, relace nebo vytváření modelu strojového učení, které pracují s dávkami dat. V tomto případě je Spark Streaming ideálním nástrojem z několika důvodů:
- V porovnání s jinými nástroji se snadno vyvíjí. Bohatá a stručná rozhraní API Sparku usnadňují vytváření složitých topologií.
- Podobný kód pro streamování a dávkové zpracování. S několika změnami lze kód pro malé dávky v reálném čase použít pro obrovské dávky offline. Kromě snížení velikosti kódu tento přístup zkracuje čas potřebný pro testování a integraci.
- Je potřeba znát jeden motor. Školení personálu o zvláštnostech a vnitřních součástech distribuovaných procesorů je spojeno s náklady. Standardizace na Sparku konsoliduje tyto náklady jak na streamování, tak na dávkové.
- Mikrodávkování vám pomůže spolehlivě škálovat. Potvrzení na úrovni dávky umožňuje větší propustnost a umožňuje řešení bez obav z dvojího odeslání. Micro-batching také pomáhá s odesíláním změn do HDFS nebo HBase z hlediska výkonu v měřítku.
- Integrace ekosystému Hadoop je zapečena. Spark má hlubokou integraci s HDFS, HBase a Kafka.
- Žádné riziko ztráty dat. Díky WAL a Kafka se Spark Streaming vyhýbá ztrátě dat v případě selhání.
- Je snadné ladit a spustit. Můžete ladit a krokovat svůj kód Spark Streaming v místním IDE bez clusteru. Kód navíc vypadá jako běžný funkční programovací kód, takže vývojářům v Javě nebo Scale nezabere mnoho času, aby provedl skok. (Python je také podporován.)
- Streamování je nativně stavové. Ve Spark Streaming je stát prvotřídní občan, což znamená, že je snadné psát stavové streamovací aplikace, které jsou odolné vůči selhání uzlů.
- Jako de facto standard, Spark získává dlouhodobé investice z celého ekosystému.
V době psaní tohoto článku bylo v Sparku jako celku za posledních 30 dní zaznamenáno přibližně 700 odevzdání – v porovnání s jinými streamovacími frameworky, jako je Storm, s 15 odevzdáními za stejnou dobu. - Máte přístup ke knihovnám ML.
MLlib společnosti Spark se stává velmi populární a její funkčnost se bude jen zvyšovat. - V případě potřeby můžete použít SQL.
Pomocí Spark SQL můžete do streamovací aplikace přidat logiku SQL a snížit tak složitost kódu.
Závěr
Streamování má velkou sílu a několik možných vzorů, ale jak jste se v tomto příspěvku dozvěděli, můžete dělat opravdu výkonné věci s minimálním kódováním, pokud víte, který vzor nejlépe odpovídá vašemu případu použití.
Ted Malaska je Solutions Architect ve společnosti Cloudera, přispěvatel do Spark, Flume a HBase a spoluautor knihy O’Reilly, Architektura aplikací Hadoop.