V tomto blogu vám poskytneme úplné představení Hadoop Mapper . Já
V tomto blogu odpovíme, co je Mapper v Hadoop MapReduce, jak funguje hadoop mapper, jaký je proces mapperu v Mapreduce, jak Hadoop generuje pár klíč-hodnota v MapReduce.
Úvod do Hadoop Mapper
Hadoop Mapper zpracovává vstupní záznam vytvořený RecordReader a generuje mezilehlé páry klíč–hodnota. Meziprodukt výstup je zcela odlišné od vstupního páru.
Výstupem mapovače je plná Kolekce dvojic klíč-hodnota. Před zápisem výstupu pro každou úlohu mapovače proběhne rozdělení výstupu na základě klíče. Proto rozdělení rozepisuje, že všechny hodnoty pro každý klíč, jsou seskupeny dohromady.
Hadoop MapReduce generuje jednu mapu úkol pro každou InputSplit.
Hadoop MapReduce rozumí pouze párům klíč-hodnota dat. Před odesláním dat do mapovače by tedy měl framework Hadoop skrýt data do páru klíč-hodnota.
Jak se v Hadoopu generuje pár klíč–hodnota?
Protože jsme pochopili, co je mapovač v hadoopu, nyní probereme, jak Hadoop generuje pár klíč-hodnota?
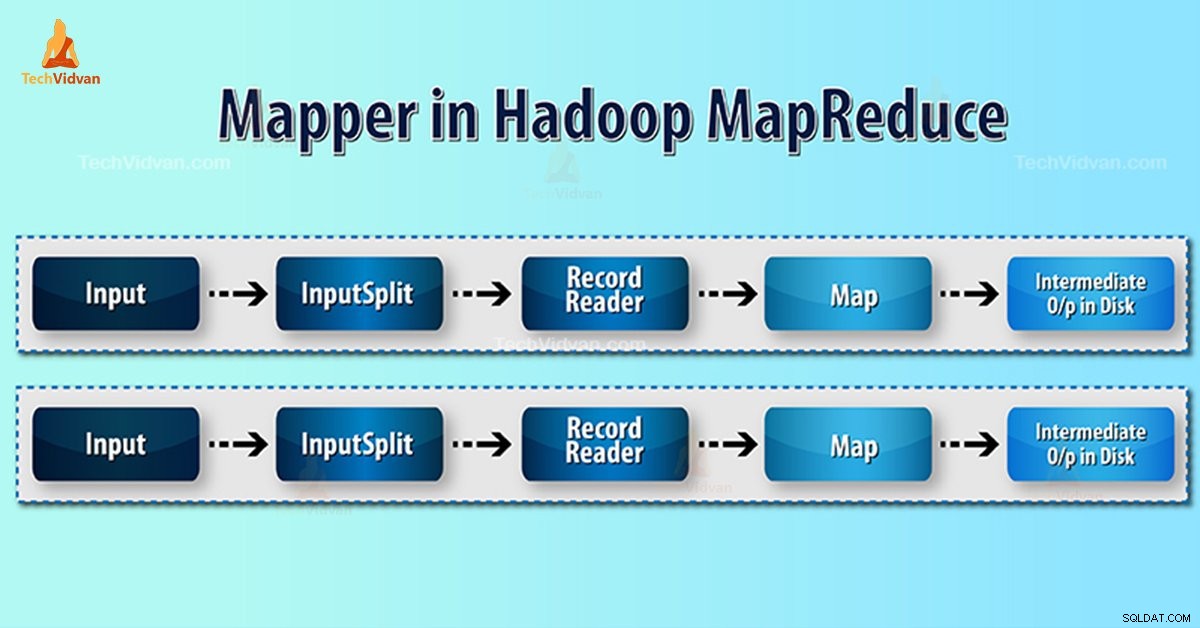
- InputSplit – Je logické znázornění dat generovaných InputFormat. V programu MapReduce popisuje jednotku práce, která obsahuje jeden mapový úkol.
- RecordReader- Komunikuje s inputSplit. A pak převádí data do dvojic klíč-hodnota vhodných pro čtení z mapovače. RecordReader ve výchozím nastavení používá TextInputFormat k převodu dat na pár klíč–hodnota.
Proces mapování v Hadoop MapReduce
InputSplit převede fyzickou reprezentaci bloků do logické, že Mapper. Například pro čtení souboru 100MB, to bude vyžadovat 2 InputSplit. Pro každý blok framework vytvoří jeden InputSplit. Každý InputSplit vytvoří jeden mapovač.
MapReduce InputSplit ne vždy záleží na počtu datových bloků . Číslo rozdělení můžeme změnit nastavením vlastnosti mapred.max.split.size během provádění úlohy.
MapReduce RecordReader je zodpovědný za čtení/převod dat na páry klíč-hodnota až do konce souboru. RecordReader přiřazuje byte offset pro každý řádek v souboru.
Poté Mapper přijme tento pár klíčů. Mapper vytváří přechodný výstup (páry klíč-hodnota, které lze pochopitelně snížit).
Kolik mapových úkolů v Hadoopu?
Počet mapových úloh závisí na celkovém počtu bloků vstupních souborů. V MapReduce mapě správná úroveň paralelismu se zdá být kolem 10 až 100 míst / node. Existuje však 300 map pro úlohy s mapováním CPU-light.
Máme například velikost bloku 128 MB. A očekáváme 10 TB vstupních dat. Vyrábí tak 82 000 map. Počet map tedy závisí na InputFormat.
mapovače =(celková velikost dat) / (vstup vel)
Příklad – velikost dat je 1 TB. Velikost vstupního rozdělení je 100 MB.
Mapovač =(1000*1000)/100 =10 000
Závěr
Mapper v Hadoopu tedy vezme sadu dat a převede je na jinou sadu dat. Jednotlivé prvky tedy rozděluje na n-tice (páry klíč/hodnota).
Doufám, že se vám tento blok líbí, pokud máte jakýkoli dotaz na mapovač Hadoop, zanechte prosím komentář v sekci níže. Rádi je vyřešíme.