Doposud jsme se zabývali úvodem Hadoop a Hadoop HDFS podrobně. V tomto tutoriálu vám poskytneme podrobný popis Hadoop Reducer.
Zde probereme, co je Reducer v MapReduce, jak Reducer funguje v Hadoop MapReduce, různé fáze Hadoop Reducer, jak můžeme změnit počet Reducerů v Hadoop MapReduce.
Co je Hadoop Reducer?
Redukce v Hadoop MapReduce redukuje sadu mezilehlých hodnot, které sdílejí klíč k menší sadě hodnot.
V procesu provádění úlohy MapReduce bere Reducer sadu mezilehlého páru klíč–hodnota produkoval mapovač jako vstup. Reducer pak agreguje, filtruje a kombinuje páry klíč–hodnota, což vyžaduje širokou škálu zpracování.
Při provádění úlohy MapReduce se mezi klávesami a reduktory odehrává jedno mapování. Probíhají paralelně, protože jsou na sobě nezávislé. O počtu redukcí v MapReduce rozhoduje uživatel.
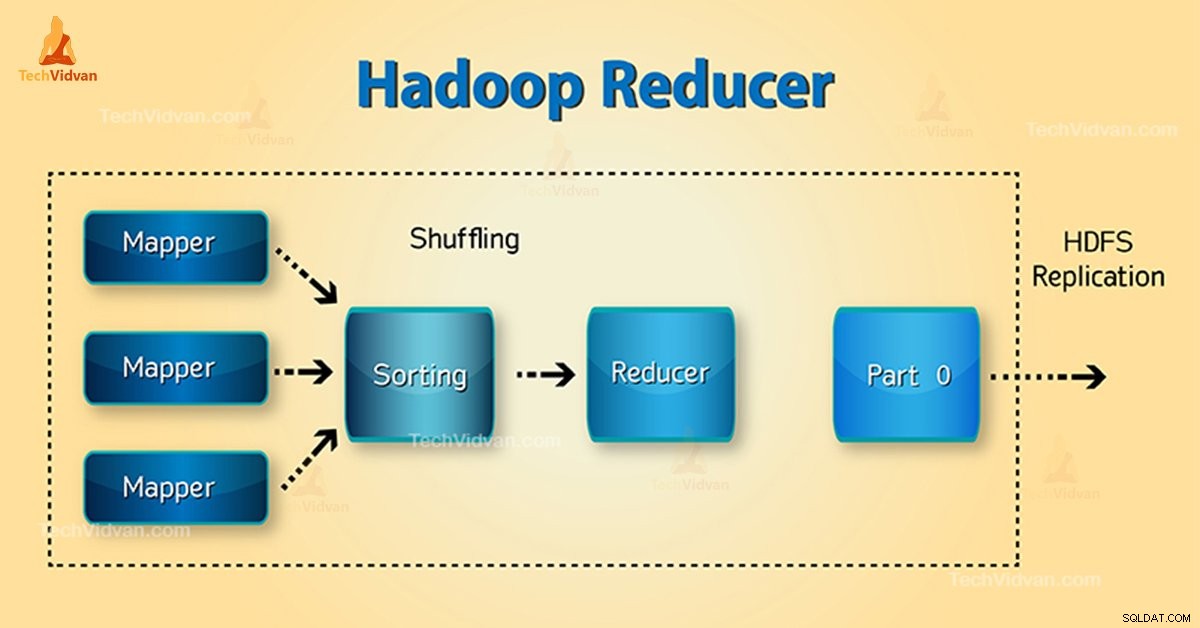
Fáze Hadoop Reducer
Tři fáze Reduceru jsou následující:
1. Fáze náhodného přehrávání
Toto je fáze, ve které je tříděný výstup z mapovače vstupem do reduktoru. Framework s pomocí HTTP načte příslušný oddíl výstupu všech mapovačů v této fázi. Fáze řazení
2. Fáze řazení
Toto je fáze, ve které je vstup z různých mapovačů opět tříděn na základě podobných klíčů v různých mapovačích.
Obě možnosti Shuffle a Sort se vyskytují současně.
3. Snížit fázi
Tato fáze nastává po zamíchání a třídění. Snížit úkol agreguje páry klíč–hodnota. Pomocí OutputCollector.collect() vlastnost, výstup úlohy snížení se zapíše do systému souborů. Výstup reduktoru není seřazený.
Počet reduktorů v Hadoop MapReduce
Uživatel nastaví počet reduktorů pomocí Job.setNumreduceTasks(int) vlastnictví. Tedy správný počet reduktorů podle vzorce:
0,95 nebo 1,75 násobeno (
Takže s 0,95 se okamžitě spustí všechny redukce. Po dokončení map začněte přenášet výstupy map.
Rychlejší uzel dokončí první kolo reduktorů s 1,75. Poté spustí druhou vlnu reduktoru, který dělá mnohem lepší práci při vyvažování zátěže.
Se zvýšením počtu reduktorů:
- Narůstá režie rámce.
- Vyrovnávání zátěže se zvyšuje.
- Náklady na selhání se snižují.
Závěr
Reducer tedy bere výstup mapovačů jako vstup. Poté zpracujte páry klíč–hodnota a vytvořte výstup. Výstup reduktoru je konečný výstup. Pokud se vám tento blog líbí nebo máte jakýkoli dotaz týkající se Hadoop Reducer, tak se s námi podělte zanecháním komentáře.
Doufáme, že vám pomůžeme.