Toto je část 2 této blogové série. Část 1 si můžete přečíst zde: Digitální transformace je cesta dat od okraje k nahlédnutí
Tato série blogů sleduje údaje o výrobě, provozu a prodeji pro propojeného výrobce vozidel, jak data procházejí fázemi a transformacemi, které se obvykle vyskytují ve velké výrobní společnosti na špičce současné technologie. První blog představil falešnou společnost vyrábějící připojená vozidla, The Electric Car Company (ECC), aby ilustroval cestu výrobních dat v průběhu životního cyklu dat. K dosažení tohoto cíle využívá ECC Cloudera Data Platform (CDP) k předpovídání událostí a k zobrazení výrobního procesu vozu v jeho továrnách po celém světě shora dolů.
Po dokončení kroku Shromažďování dat v předchozím blogu je dalším krokem ECC v životním cyklu dat Obohacování dat. ECC obohatí shromážděná data a zpřístupní je pro použití při analýze a vytváření modelů později v životním cyklu dat. Níže je uvedena celá sada kroků v životním cyklu dat a každý krok v životním cyklu bude podpořen vyhrazeným příspěvkem na blogu (viz obr. 1):
- Shromažďování dat – příjem a monitorování dat na okraji (ať už jde o průmyslové senzory nebo osoby v autosalonu)
- Obohacení dat – zpracování, agregace a správa datového kanálu pro přípravu dat pro další analýzu
- Hlášení – poskytování obchodních vhledů (analýza a prognózování prodeje, rozpočtování jako příklady)
- Poskytování – řízení a řízení základních obchodních operací (obchodní operace, sledování výroby)
- Predictive Analytics – prediktivní analytika založená na AI a strojovém učení (prediktivní údržba, optimalizace zásob na základě poptávky jako příklady)
- Zabezpečení a správa – integrovaná sada technologií zabezpečení, správy a správy v průběhu celého životního cyklu dat

Obr. 1 Životní cyklus podnikových dat
Výzva k obohacování dat
ECC potřebuje komplexní pohled a důkladné pochopení všech dat souvisejících s výrobou, obchodními operacemi a přepravou jejich vozidel. Budou také muset rychle identifikovat problémy s daty, jako jsou provozní senzory, které oddělují data, která mohou zahrnovat falešné teplotní špičky způsobené neplánovanými zastaveními stroje nebo náhlým spouštěním. Údaje, které nemají nic společného s procesem, kdy pracovníci údržby například při provádění rutinních kontrol vyjmou senzor z nádrže s kyselinou, by při analýze neměla být brána v úvahu.
ECC navíc čelí následujícím problémům s daty, které je třeba vyřešit, aby se výroba motorů úspěšně posunula dodavatelským řetězcem. Tyto problémy s daty zahrnují následující:
- Načítání dat v různých formátech z různých zdrojů: Datové inženýrské kanály vyžadují, aby byla data přiváděna z různých zdrojů a v mnoha různých formátech. Ať už jsou data získávána ze senzorů umístěných na výrobní lince, které podporují výrobní operace, nebo z dat ERP řídících dodavatelský řetězec, je třeba je všechny spojit pro další analýzu.
- Odfiltrování nadbytečných nebo irelevantních dat: Odstranění duplicitních nebo neplatných dat a zajištění přesnosti zbývajících dat je klíčovým krokem při přípravě dat pro další použití v pokročilé prediktivní analýze.
- Schopnost identifikovat neefektivní procesy: ECC vyžaduje schopnost vidět, jaké datové procesy zabírají nejvíce času a zdrojů, což usnadňuje zacílení na nevýkonné části kanálu, aby se celý proces urychlil.
- Schopnost monitorovat všechny procesy z jednoho panelu: ECC vyžaduje centralizovaný systém, který jim umožňuje sledovat všechny probíhající datové procesy a také cestu k rozšíření jejich stávající infrastruktury při zachování transparentnosti.
Spravované a kvalitní datové sady jsou páteří každé pokročilé analytické iniciativy. Aby toho bylo dosaženo, musí být použit rámec datového inženýrství, který umožní vybudování všech potrubí a potrubí potřebných k přesunu, manipulaci a správě dat různých dílů vozidla v životním cyklu dat.
Budování potrubí pomocí datového inženýrství Cloudera
Než budou data obohacena a diskutována v prvním blogu, budou datové toky IT a OT shromážděné z továrny vyčištěny, zpracovány a upraveny. Tovární ID, ID stroje, časové razítko, číslo dílu a sériové číslo lze zachytit z QR kódu vytištěného na elektromotoru. Při montáži motoru do připojeného vozidla se zaznamenávají údaje, jako je typ modelu, VIN a cena základního vozidla.
Po prodeji vozidla se samostatně zaznamenávají prodejní informace, jako je jméno zákazníka, kontaktní informace, konečná prodejní cena a poloha zákazníka. Tyto údaje budou klíčové pro kontaktování zákazníka za účelem případného stažení nebo cílené preventivní údržby. Ukládají se také geolokační údaje, které pomohou zmapovat polohu zákazníků na zeměpisné šířky a délky, aby bylo možné lépe porozumět, kde se tyto motory po prodeji ve vozidle nacházejí.
ECC použije Cloudera Data Engineering (CDE) k řešení výše uvedených datových problémů (viz obr. 2). CDE pak data zpřístupní Cloudera Data Warehouse (CDW), kde budou zpřístupněna pro pokročilé analýzy a reporty business intelligence. Kroky CDE jsou popsány níže.
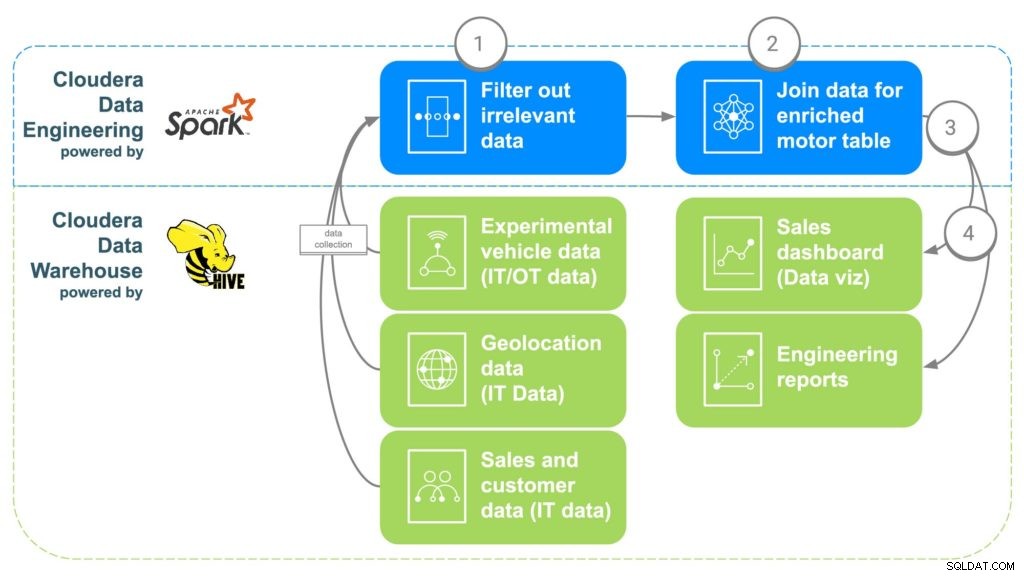
Obr. 2 Potrubí obohacování dat ECC
KROK 1:Filtrujte a oddělte data
Prvním krokem při používání CDE je vytvoření úlohy PySpark, která přináší data z těchto různých „surových“ zdrojů z kroku 1. Toto je příležitost k filtrování jakýchkoli irelevantních dat, jako jsou například zákazníci mladší 16 let, protože je obvykle minimální věk pro řízení. Duplicitní data a další nepodstatná data lze také filtrovat nebo oddělit.
KROK 2:Sloučení dat
Aby bylo možné zkombinovat všechna data, bude CDE korelovat společné odkazy dohromady. Nejprve budou data o prodeji vozu spojena se zákazníkem, který si vůz zakoupil, aby bylo možné získat metadata zákazníka, jako jsou kontaktní údaje, věk, mzda atd. Geolokační data budou poté použita k získání přesnějších informací o poloze zákazníka. , což později pomůže při mapování motorů. Údaje o instalaci dílu budou použity k identifikaci sériových čísel pro každý motor, který byl nainstalován v autě zákazníka. Nakonec budou tovární data zarovnána tak, aby odpovídala sériovému číslu motoru, které bude identifikovat továrnu, stroj a kdy byl každý konkrétní motor vytvořen.
KROK 3:Odeslání dat do Cloudera Data Warehouse
Jakmile jsou všechna data shromážděna v obohacené tabulce, jednoduchý příkaz Apache Spark zapíše data do nové tabulky v rámci Cloudera Data Warehouse. To zpřístupní data všem datovým vědcům, kteří k nim mohou chtít získat přístup k provedení nějaké další analýzy.
KROK 4:Vygenerujte řídicí panely a sestavy vizualizace dat
Díky všem datům na jednom místě lze nyní vytvářet sestavy, které zaměstnancům umožní přijímat informovanější rozhodnutí a otevírat možnosti, které neexistovaly. Teplotní mapy mohou být vytvořeny pro sledování polohy motoru a korelaci jakýchkoli problémů s potenciálními geografickými polohami, jako je selhání kvůli extrémnímu chladu nebo horku. Tato data by také mohla být použita k přesnému sledování toho, na co zákazníci mohou mít vliv, pokud by se v určité továrně v určitém časovém období vyskytl problém, což usnadňuje sledování zákazníků, kteří mohou potřebovat stažení nebo nějakou preventivní údržbu.
Závěr
Cloudera Data Engineering umožňuje ECC vybudovat potrubí, které dokáže korelovat výrobní údaje a údaje o součástech, typ použití zákazníkem, podmínky prostředí, informace o prodeji a další za účelem zlepšení spokojenosti zákazníků a spolehlivosti vozidla. Společnost ECC dosáhla svých cílů a vyřešila své výzvy sledováním údajů souvisejících s výrobou svých motorů a těžila z nich následujícími způsoby:
- ECC urychlilo čas na hodnotu tím, že zorganizovalo a automatizovalo datové kanály, aby bylo možné bezpečně a transparentně poskytovat vybrané, kvalitní datové sady z různých zdrojů dat.
- ECC dokázalo identifikovat relevantní data a odfiltrovat všechna nadbytečná a duplicitní data.
- ECC bylo schopno dosáhnout monitorování datového kanálu z jednoho panelu, a přitom bylo v pozici, kdy bylo včas upozorněno na problémy pomocí vizuálního řešení problémů, aby bylo možné rychle vyřešit problémy dříve, než budou ovlivněny podnikání.
Podívejte se na další blog, který se ponoří do Reportingu a ukáže, jak inženýři ECC spouštějí ad-hoc dotazy v CDW na tato upravená data a jak spojují data s jinými relevantními zdroji v rámci podnikového datového skladu. CDW usnadňuje spojení všech dat a poskytuje vestavěný nástroj pro vizualizaci dat, který umožňuje přejít od dotazovaných výsledků k řídicím panelům. Zůstaňte naladěni na další!
Další zdroje shromažďování dat
Chcete-li toto vše vidět v akci, klikněte na související odkazy níže a získejte další informace o obohacení dat:
- Video – Pokud chcete vidět a slyšet, jak to bylo postaveno, podívejte se na video pod odkazem.
- Výukové programy – Pokud to chcete udělat svým vlastním tempem, prohlédněte si podrobný návod se snímky obrazovky a pokyny po řádcích, jak to nastavit a provést. li>
- Meetup – Pokud si chcete promluvit přímo s odborníky z Cloudera, připojte se prosím k virtuálnímu setkání a podívejte se na živý přenos prezentace. Na konci bude čas na přímé otázky a odpovědi.
- Uživatelé – Chcete-li zobrazit více technického obsahu specifického pro uživatele, klikněte na odkaz.