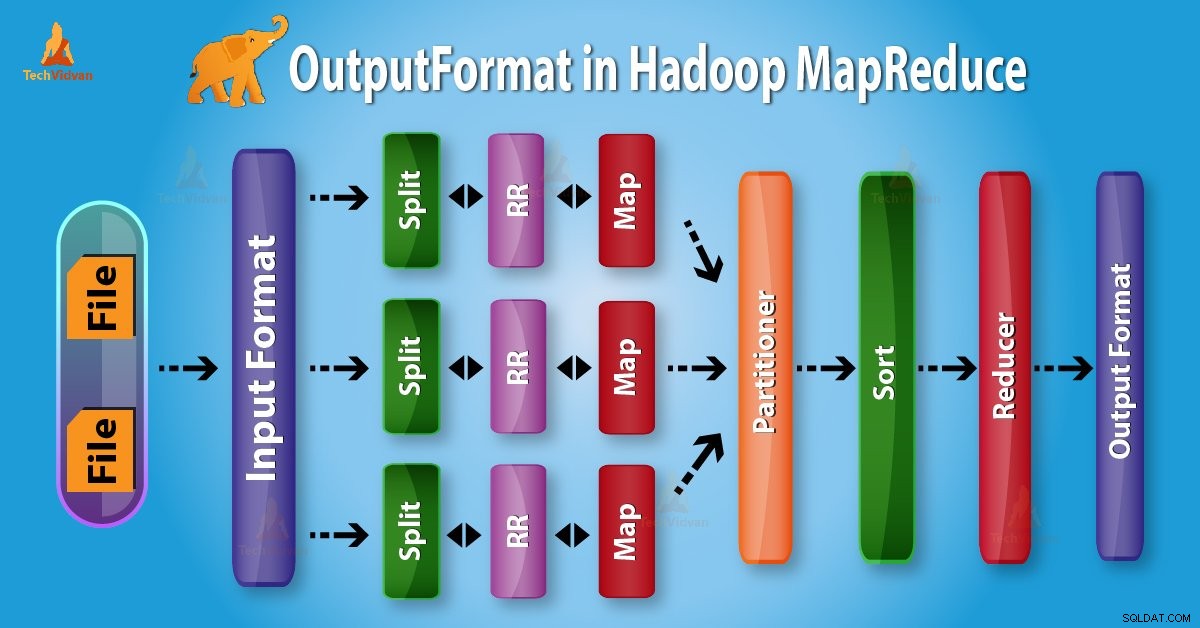
V našem předchozím Hadoop tutu o rial , poskytli jsme vám podrobný popis InputFormat. Nyní se v tomto blogu budeme zabývat výstupním formátem Hadoop.
Budeme diskutovat o tom, co je OutputFormat v Hadoop, Co je RecordWritter v MapReduce OutputFormat. Pokryjeme také typy OutputFormat v MapReduce.
Úvod do Hadoop OutputFormat
OutputFormat zkontrolujte výstupní specifikaci pro provedení úlohy Map-Reduce. Popisuje, jak se implementace RecordWriter používá k zápisu výstupu do výstupních souborů.
Než začneme s OutputFormat, nejprve se naučíme, co je RecordWriter a jaká je práce RecordWriter v MapReduce?
1. RecordWriter v Hadoop MapReduce
Jak víme, reduktor trvá Mappers mezivýstup jako vstup. Potom na nich spustí funkci redukce, aby generoval výstup, který je opět nula nebo více párů klíč–hodnota.
RecordWriter při provádění úlohy MapReduce tedy zapisuje tyto výstupní páry klíč-hodnota z fáze Reducer do výstupních souborů.
2. Výstupní formát Hadoop
Shora je zřejmé, že RecordWriter přebírá výstupní data z Reduceru. Poté tato data zapíše do výstupních souborů. OutputFormat určuje způsob, jakým jsou tyto výstupní páry klíč–hodnota zapsány do výstupních souborů pomocí RecordWriter.
Funkce OutputFormat a InputFormat jsou podobné. Instance OutputFormat se používají k zápisu do souborů na místním disku nebo v HDFS. V MapReduce provádění úlohy na základě výstupní specifikace;
- Úloha Hadoop MapReduce kontroluje, zda výstupní adresář již neexistuje.
- OutputFormat v úloze MapReduce poskytuje implementaci RecordWriter, kterou lze použít k zápisu výstupních souborů úlohy. Poté jsou výstupní soubory uloženy v systému souborů.
Rámec používá FileOutputFormat.setOutputPath() způsob nastavení výstupního adresáře.
Typy výstupního formátu v MapReduce
Existují různé typy OutputFormat, které jsou následující:
1. TextOutputFormat
Výchozí výstupní formát je TextOutputFormat. Na jednotlivé řádky textových souborů zapisuje dvojice (klíč, hodnota). Jeho klíče a hodnoty mohou být libovolného typu. Důvodem je to, že TextOutputFormat je převede na řetězec voláním toString() na nich.
Odděluje pár klíč–hodnota znakem tabulátoru. Pomocí MapReduce.output.textoutputformat.separator vlastnost můžeme také změnit.
KeyValueTextOutputFormat se také používá pro čtení těchto výstupních textových souborů.
2. SequenceFileOutputFormat
Tento OutputFormat zapisuje soubory sekvencí pro svůj výstup. SequenceFileInputFormat je také meziformát používaný mezi úlohami MapReduce. Serializuje libovolné datové typy do souboru.
A odpovídající SequenceFileInputFormat deserializuje soubor na stejné typy. Prezentuje data dalšímumapovači stejným způsobem, jako byl emitován předchozím reduktorem. Statické metody také řídí kompresi.
3. SequenceFileAsBinaryOutputFormat
Je to další varianta SequenceFileInputFormat. Také zapisuje klíče a hodnoty do sekvenčního souboru v binárním formátu.
4. MapFileOutputFormat
Je to další forma FileOutputFormat. Výstup také zapisuje jako mapové soubory. Rámec přidává klíč do MapFile v pořadí. Musíme tedy zajistit, aby reduktor vysílal klíče v seřazeném pořadí.
5. MultipleOutputs
Tento formát umožňuje zápis dat do souborů, jejichž názvy jsou odvozeny z výstupních klíčů a hodnot.
6. LazyOutputFormat
Při provádění úlohy MapReduce FileOutputFormat někdy vytváří výstupní soubory, i když jsou prázdné. LazyOutputFormat je také obalový formát OutputFormat.
7. DBOutputFormat
Je to OutputFormat pro zápis do relačních databází a HBase. Tento formát také odesílá výstup snížení do tabulky SQL. Přijímá také páry klíč–hodnota. V tomto má klíč typ rozšiřující DBwritable.
Závěr
Proto se podle potřeby používají různé výstupní formáty. Doufám, že vám tento blog bude užitečný. Pokud máte jakýkoli dotaz ohledně Hadoop OutputFormat, zanechte prosím komentář v poli pro komentáře. Rádi je vyřešíme.