V našem předchozímHadoop blogy jsme studovali každou součást Hadoop Podrobný proces MapReduce. V tomto budeme diskutovat o velmi zajímavém tématu, například o práci Map Only v Hadoop.
Nejprve si krátce představíme Mapu a Snížit fáze v Hadoop Mapreduce, poté si probereme, co je úloha pouze pro mapy v Hadoop MapReduce.
Nakonec také probereme výhody a nevýhody úlohy Hadoop Map Only v tomto tutoriálu.
Co je Hadoop Map Only Job?
Úloha pouze na mapě v Hadoopu je proces, ve kterém mapovač dělá všechny úkoly. reduktor neprovádí žádný úkol . Výstup Mapperu je konečným výstupem.
MapReduce je vrstva zpracování dat Hadoop. Zpracovává velká strukturovaná i nestrukturovaná data uložená v HDFS . MapReduce také paralelně zpracovává obrovské množství dat.
Dělá to rozdělením úkolu (předloženého úkolu) na sadu nezávislých úkolů (dílčího úkolu). V Hadoopu funguje MapReduce rozdělením zpracování do fází:Mapa a Snížit .
- Mapa: Je to první fáze zpracování, kde specifikujeme veškerý složitý logický kód. Vezme sadu dat a převede na jinou sadu dat. Rozdělí každý jednotlivý prvek na n-tice (páry klíč–hodnota ).
- Snížit: Je to druhá fáze zpracování. Zde specifikujeme odlehčené zpracování, jako je agregace/součet. Jako vstup bere výstup z mapy. Pak zkombinuje tyto n-tice na základě klíče.
Z tohoto příkladu počtu slov můžeme říci, že existují dvě sady paralelních procesů, mapovat a zmenšovat. V procesu mapování je první vstup rozdělen, aby se práce rozložila mezi všechny uzly mapy, jak je uvedeno výše.
Potom framework identifikuje každé slovo a namapuje je na číslo 1. Vytvoří tedy dvojice nazývané páry n-tic (klíč-hodnota).
V prvním uzlu mapovače míjí tři slova lev, tygr a řeka. Jako výstup uzlu tedy vytváří 3 páry klíč-hodnota. Tři různé klíče a hodnota nastavené na 1 a stejný proces se opakuje pro všechny uzly.
Poté tyto n-tice předá uzlům redukce. Partitioner provedezamíchání takže všechny n-tice se stejným klíčem jdou do stejného uzlu.
V procesu snižování se v zásadě děje agregace hodnot nebo spíše operace s hodnotami, které sdílejí stejný klíč.
Podívejme se nyní na scénář, ve kterém potřebujeme pouze provést operaci. Nepotřebujeme agregaci, v takovém případě upřednostníme ‚Práce pouze na mapě '.
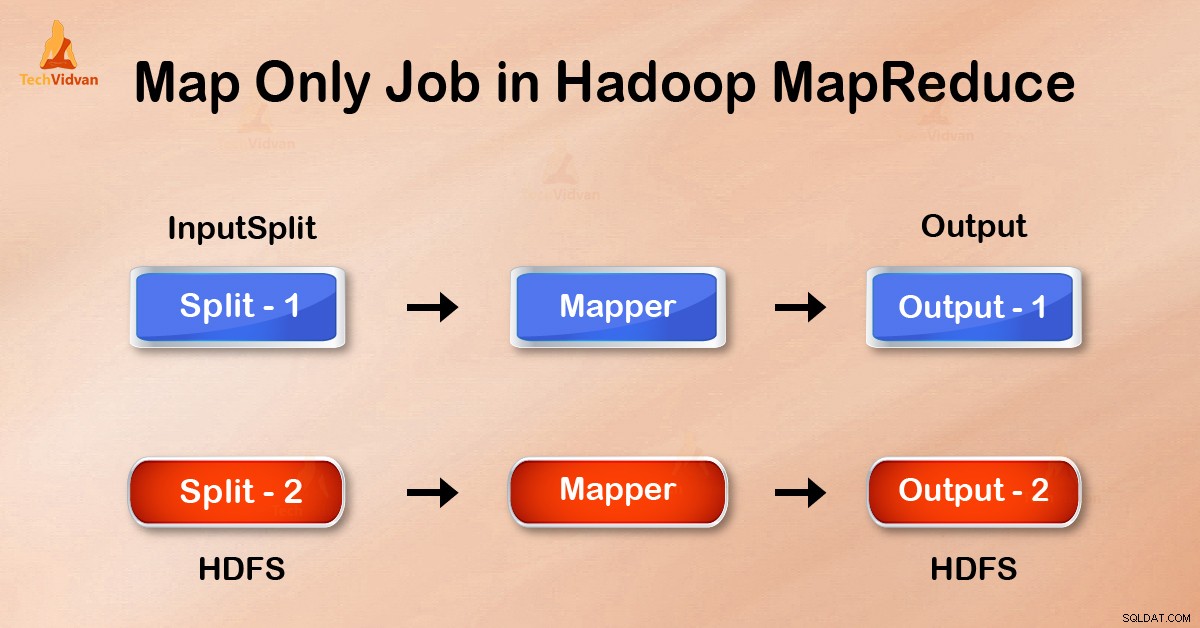
V úloze Pouze mapa provádí mapa všechny úkoly pomocí funkce InputSplit . Reduktor nefunguje. Výstup mapovače je konečným výstupem.
Jak se vyhnout Reduce Phase v MapReduce?
Nastavením job.setNumreduceTasks(0) v konfiguraci v ovladači se můžeme vyhnout redukci fáze. Tím se číslo sníží na 0 . Úplný úkol tedy provede jediný mapovač.
Výhody práce pouze na mapě v Hadoop
Při provádění úlohy MapReduce mezi fázemi mapování a redukování existuje fáze klíče, třídění a míchání. Náhodné řazení – řazení jsou zodpovědní za řazení klíčů ve vzestupném pořadí. Potom seskupení hodnot na základě stejných klíčů. Tato fáze je velmi nákladná.
Pokud redukční fáze není vyžadována, měli bychom se jí vyhnout. Vzhledem k tomu, že se vyhnete fázi redukce, odstraníte také fázi třídění a míchání. Proto to také ušetří přetížení sítě.
Důvodem je to, že při míchání se výstup mapovače přesune ke snížení. A když je velikost dat obrovská, velká data musí putovat do reduktoru.
Výstup mapovače se před odesláním za účelem zmenšení zapíše na místní disk. Ale v úloze pouze mapy je tento výstup zapsán přímo do HDFS. To dále šetří čas a snižuje náklady.
Závěr
Viděli jsme tedy, že úloha typu Map-only snižuje zahlcení sítě tím, že se vyhne náhodnému řazení, třídění a redukci fáze. Samotná mapa se stará o celkové zpracování a produkci výstupu. BY pomocí job.setNumreduceTasks(0) toho je dosaženo.
Doufám, že jste porozuměli úloze Pouze mapa Hadoop a její význam, protože jsme probrali vše o úloze Pouze mapy v Hadoopu. Ale pokud máte nějaký dotaz, můžete se s námi podělit v sekci komentářů.