Tento výukový program Hadoop je vše o MapReduce Shuffling and Sorting. Zde vám poskytneme podrobný popis fáze Hadoop Shuffling and Sorting.
Nejprve probereme, co je MapReduce Shuffling, dále s MapReduce Sorting a poté podrobně pokryjeme sekundární fázi třídění MapReduce.
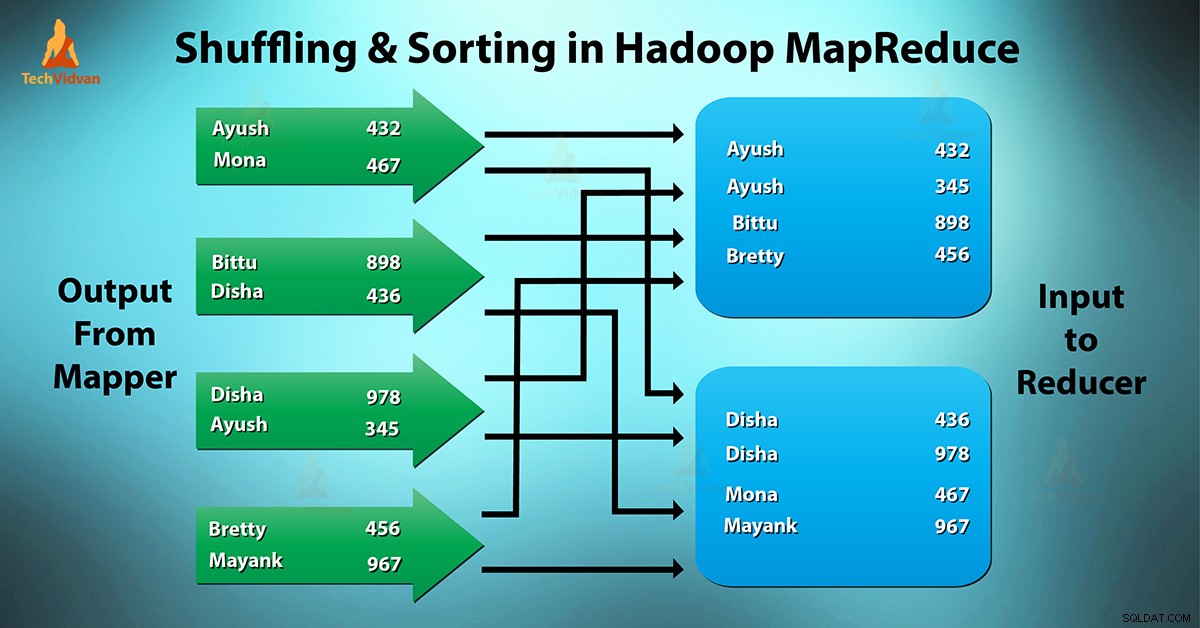
Co je MapReduce Shuffling and Sorting?
Náhodné přehrávání je proces, kterým přenášímapovače mezivýstup do reduktoru. Reduktor získá 1 nebo více klíčů a souvisejících hodnot na základě reduktorů.
Zprostředkovaný klíč – hodnota generovaná mapovačem se třídí automaticky podle klíče. Ve fázi Sort dochází ke slučování a třídění mapového výstupu.
K míchání a řazení v Hadoop dochází současně.
Náhodné přehrávání v MapReduce
Proces přenosu dat z mapovačů do reduktorů se promíchá. Je to také proces, kterým systém provádí třídění. Poté přenese mapový výstup do reduktoru jako vstup. To je důvod, proč je pro redukce nezbytná fáze míchání.
Jinak by neměli žádný vstup (nebo vstup od každého mapovače). Protože míchání může začít ještě před dokončením fáze mapy. Takže to ušetří čas a dokončí úkoly v kratším čase.
Řazení v MapReduce
MapReduce Framework automaticky třídí klíče generované mapovačem. Před spuštěním reduktoru se tedy všechny mezilehlé páry klíč-hodnota seřadí podle klíče a ne podle hodnoty. Netřídí hodnoty předané každému reduktoru. Mohou být v libovolném pořadí.
Řazení v úloze MapReduce pomáhá reduktoru snadno rozlišit, kdy by měla začít nová úloha redukce.
To šetří čas reduktoru. Reducer v MapReduce spustí novou úlohu redukce, když se další klíč v seřazených vstupních datech liší od předchozího. Každá úloha snížení bere páry klíč-hodnota jako vstup a generuje pár klíč-hodnota jako výstup.
Důležité je poznamenat, že míchání a třídění v Hadoop MapReduce se vůbec neprovede, pokud zadáte nulové redukce (setNumReduceTasks(0)).
Pokud je redukce nula, pak se úloha MapReduce zastaví ve fázi mapy. A fáze mapy nezahrnuje žádný druh řazení (dokonce i fáze mapy je rychlejší).
Sekundární řazení v MapReduce
Pokud chceme seřadit hodnoty reduktoru, pak použijeme techniku sekundárního třídění. Tato technika nám umožňuje třídit hodnoty (ve vzestupném nebo sestupném pořadí) předávané každému reduktoru.
Závěr
Na závěr, MapReduce Shuffling a Sorting probíhají současně, aby se shrnul mezivýstup Mapperu. Hadoop Shuffling-Sorting se neprovede, pokud zadáte nulové redukce (setNumReduceTasks (0)).
Framework třídí všechny mezilehlé páry klíč–hodnota podle klíče, nikoli podle hodnoty. Pro třídění podle hodnoty používá sekundární třídění. Pokud máte jakýkoli návrh nebo dotaz týkající se fáze míchání a třídění MapReduce, zanechte prosím komentář v poli komentáře.
Rádi je vyřešíme.