Protože používáte pružinu. Můžete použít MultipartFile získat soubor do ovladače a poté použít Binary z org.bson k uložení souboru do MongoDB , Pokud je velikost vašeho obrázku <16 MB (pokud velikost obrázku> 16 MB, můžete použít GridFs
).
Do svého projektu musíte přidat pouze jednu závislost - spring-data-mongoDB
Vezměme si příklad kolekce uživatelů, která vypadá takto:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Zde můžete vidět Binary image který představuje váš soubor obrázku.
Nyní vytvořte úložiště pro tuto kolekci uživatelů pomocí MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Vytvořte ovladač pro demo účely. Použijte @RequestParam MultipartFile file chcete-li získat soubor do ovladače, získejte bajty ze souboru a nastavte jej na objekt uživatele user.setImage(new Binary(file.getBytes())); úplný příklad je níže:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Spusťte server a dosáhněte koncového bodu, jak je znázorněno na níže uvedeném snímku obrazovky pošťáka
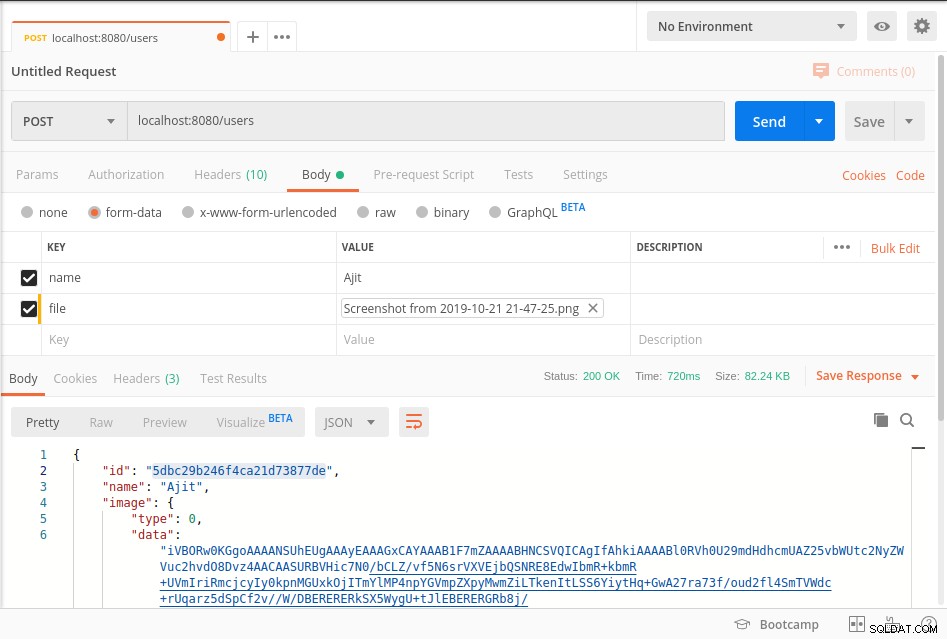
Vaše data jsou uložena v mongoDb v BinData formát a pro získání dat z databáze se prosím podívejte na getImage metoda výše uvedeného kódu.
UPRAVIT:
Tazatel používá tess4j knihovna pro extrahování textu z obrázku a doOCR je metoda v této knihovně. Podle těchto kroků jsem extrahoval text z obrázku ve své jarní spouštěcí aplikaci.
-
Nainstalujte
tesseract-ocrdo vašeho systému:sudo apt-get install tesseract-ocr -
Stáhněte si
eng.traineddatatréninková data z https://github.com/tesseract-ocr/tessdata a přesuňte jej do kořenové složky projektu. -
Přidejte do svého projektu níže uvedenou závislost:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Přidejte níže uvedený kód do stávajícího projektu:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}