Prozkoumejte architekturu Hadoop, což je nejrozšířenější rámec pro ukládání a zpracování masivních dat.
V tomto článku budeme studovat architekturu Hadoop. Článek vysvětluje architekturu Hadoop a komponenty architektury Hadoop, kterými jsou HDFS, MapReduce a YARN. V článku podrobně prozkoumáme architekturu Hadoop spolu s diagramem architektury Hadoop.
Začněme nyní s architekturou Hadoop.
Architektura Hadoop
Cílem navrhování Hadoop je vyvinout levný, spolehlivý a škálovatelný rámec, který ukládá a analyzuje rostoucí velká data.
Apache Hadoop je softwarový framework navržený Apache Software Foundation pro ukládání a zpracování velkých datových sad různých velikostí a formátů.
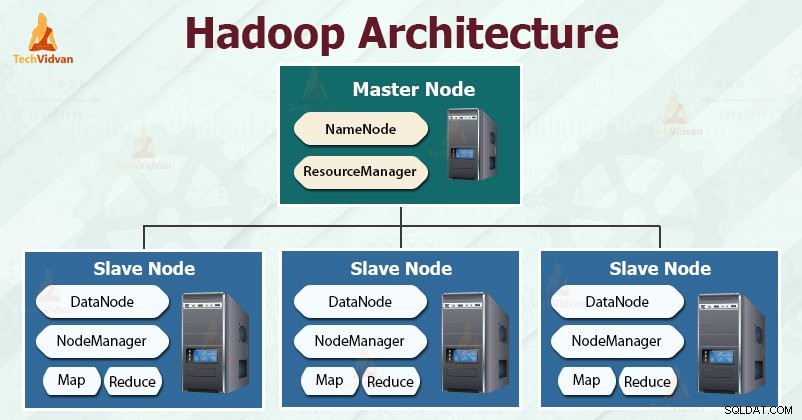
Hadoop následuje master-slave architektura pro efektivní ukládání a zpracování obrovského množství dat. Hlavní uzly přidělují úkoly podřízeným uzlům.
Podřízené uzly jsou odpovědné za ukládání skutečných dat a provádění skutečných výpočtů/zpracování. Hlavní uzly jsou odpovědné za ukládání metadat a správu zdrojů v rámci clusteru.
Slave uzly ukládají skutečná obchodní data, zatímco master ukládá metadata.
Architektura Hadoop se skládá ze tří vrstev. Jsou to:
- Vrstva úložiště (HDFS)
- Vrstva správy zdrojů (YARN)
- Vrstva pro zpracování (MapReduce)
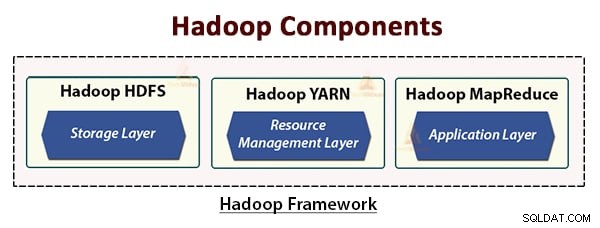
HDFS, YARN a MapReduce jsou základní komponenty Hadoop Framework.
Pojďme si nyní tyto tři základní komponenty podrobně prostudovat.
1. HDFS
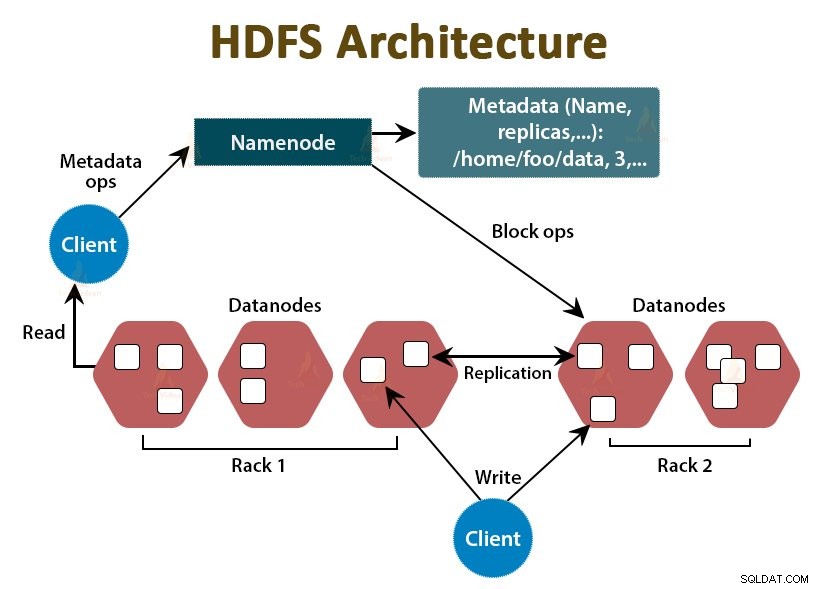
HDFS je Distribuovaný systém souborů Hadoop , který běží na levném komoditním hardwaru. Je to úložná vrstva pro Hadoop. Soubory v HDFS jsou rozděleny do bloků o velikosti bloků nazývaných datové bloky.
Tyto bloky jsou pak uloženy na podřízených uzlech v clusteru. Velikost bloku je ve výchozím nastavení 128 MB, kterou můžeme nakonfigurovat podle našich požadavků.
Stejně jako Hadoop se i HDFS řídí architekturou master-slave. Skládá se ze dvou démonů – NameNode a DataNode. NameNode je hlavní démon, který běží na hlavním uzlu. DataNodes jsou slave démon, který běží na slave uzlech.
NameNode
NameNode ukládá metadata souborového systému, tj. názvy souborů, informace o blocích souboru, umístění bloků, oprávnění atd. Spravuje Datanodes.
Datový uzel
DataNodes jsou podřízené uzly, které ukládají skutečná obchodní data. Slouží klientovi požadavky na čtení/zápis na základě instrukcí NameNode.
DataNodes ukládá bloky souborů a NameNode ukládá metadata, jako jsou umístění bloků, oprávnění atd.
2. MapReduce
Je to vrstva zpracování dat Hadoopu. Jedná se o softwarový rámec pro psaní aplikací, které zpracovávají obrovské množství dat (terabajty až petabajty v rozsahu) paralelně na clusteru komoditního hardwaru.
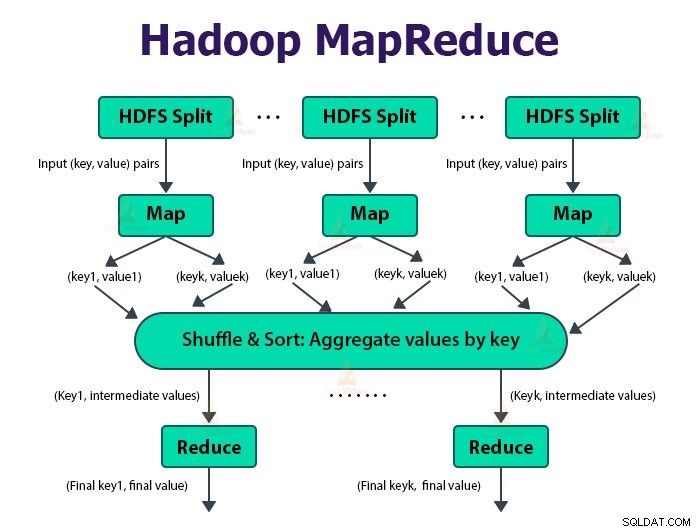
Rámec MapReduce funguje na párech
Úloha MapReduce je jednotka práce, kterou chce klient provést. Úloha MapReduce se skládá hlavně ze vstupních dat, programu MapReduce a konfiguračních informací. Hadoop spouští úlohy MapReduce tak, že je rozděluje do dvou typů úloh, které jsou úlohy map a omezení úkolů . Hadoop YARN naplánoval tyto úlohy a jsou spuštěny na uzlech v clusteru.
Kvůli některým nepříznivým podmínkám, pokud úkoly selžou, budou automaticky přeplánovány na jiný uzel.
Uživatel definuje funkci mapy a funkce snížení pro provedení úlohy MapReduce.
Vstupem do mapovací funkce a výstupem z funkce snížení je pár klíč, hodnota.
Funkcí mapových úloh je načítat, analyzovat, filtrovat a transformovat data. Výstupem úlohy mapy je vstup do úlohy snížení. Úloha Reduce pak provede seskupení a agregaci na výstupu úlohy mapy.
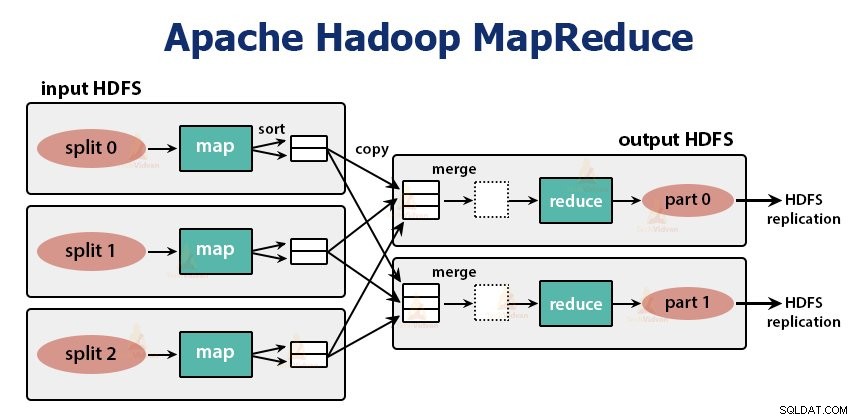
Úloha MapReduce se provádí ve dvou fázích-
1. Mapová fáze
a. RecordReader
Hadoop rozděluje vstupy do úlohy MapReduce na části s pevnou velikostí nazývané rozdělení vstupu nebo se rozdělí. RecordReader transformuje tato rozdělení na záznamy a analyzuje data do záznamů, ale neanalyzuje samotné záznamy. RecordReader poskytuje data funkci mapovače v párech klíč–hodnota.
b. Mapa
Ve fázi mapování vytvoří Hadoop jednu úlohu mapy, která spouští uživatelem definovanou funkci zvanou mapovací funkce pro každý záznam ve vstupním rozdělení. Generuje nula nebo více mezilehlých párů klíč-hodnota jako výstup mapovací úlohy.
Úloha mapy zapíše svůj výstup na místní disk. Tento mezivýstup je poté zpracován úlohami snížení, které spouštějí uživatelem definovanou funkci snížení, aby vytvořily konečný výstup. Jakmile je úloha dokončena, mapový výstup se vyprázdní.
c. Slučovača
Vstupem do jediné úlohy snížení je výstup všech mapovačů, který je výstupem všech mapových úloh. Hadoop umožňuje uživateli definovat funkci slučovače, která běží na mapovém výstupu.
Slučovač seskupuje data ve fázi mapy před jejich předáním Reduceru. Kombinuje výstup funkce mapy, který je pak předán jako vstup do funkce snížení.
d. Oddělovač
Pokud existuje více reduktorů, pak mapovací úlohy rozdělují svůj výstup, přičemž každá vytváří jeden oddíl pro každou úlohu redukce. V každém oddílu může být mnoho klíčů a jejich přidružených hodnot, ale záznamy pro každý daný klíč jsou všechny v jediném oddílu.
Hadoop umožňuje uživatelům ovládat dělení zadáním uživatelem definované funkce dělení. Obecně existuje výchozí Partitioner, který seskupuje klíče pomocí hashovací funkce.
2. Snížit fázi:
Různé fáze úlohy snížení jsou následující:
a. Seřadit a zamíchat:
Úloha Reduktor začíná krokem zamíchání a řazení. Hlavním účelem této fáze je shromáždit ekvivalentní klíče dohromady. Fáze Sort and Shuffle stáhne data, která zapíše rozdělovač do uzlu, kde běží Reducer.
Seřadí každou datovou část do velkého seznamu dat. Rámec MapReduce provádí toto řazení a míchání, takže jej můžeme snadno opakovat v úloze redukce.
Řazení a míchání jsou prováděny rámcem automaticky. Vývojář prostřednictvím objektu komparátoru může mít kontrolu nad tím, jak se klíče třídí a seskupují.
b. Snížit:
Reduktor, což je uživatelsky definovaná funkce snížení, se provádí jednou pro každé seskupení kláves. Reduktor filtruje, agreguje a kombinuje data několika různými způsoby. Jakmile je úkol snížení dokončen, poskytne výstupnímu formátu nula nebo více párů klíč–hodnota. Výstup úlohy snížení je uložen v Hadoop HDFS.
c. Výstupní formát
Vezme výstup redukce a zapíše jej do souboru HDFS pomocí RecordWriter. Ve výchozím nastavení odděluje klíč, hodnotu tabulátorem a každý záznam znakem nového řádku.
3. PŘÍZE
YARN znamená Et Another Resource Negotiator . Je to vrstva správy zdrojů Hadoopu. Byl představen v Hadoop 2.
YARN je navržen s myšlenkou rozdělit funkce plánování úloh a správy zdrojů do samostatných démonů. Základní myšlenkou je mít globálního správce zdrojů a správce aplikací pro každou aplikaci, kde aplikací může být jedna úloha nebo DAG úloh.
YARN se skládá z ResourceManager, NodeManager a ApplicationMaster pro jednotlivé aplikace.
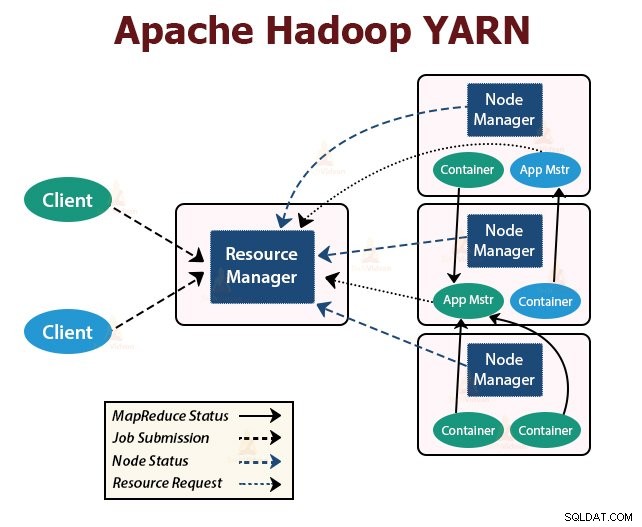
1. ResourceManager
Rozhoduje prostředky mezi všemi aplikacemi v clusteru.
Má dvě hlavní součásti, kterými jsou Scheduler a ApplicationManager.
a. plánovač
- Plánovač přiděluje prostředky různým aplikacím spuštěným v clusteru s ohledem na kapacitu, fronty atd.
- Je to čistý plánovač. Nesleduje ani nesleduje stav aplikace.
- Plánovač nezaručuje restartování neúspěšných úloh, které selhaly buď v důsledku selhání aplikace nebo hardwaru.
- Provádí plánování na základě požadavků aplikací na zdroje.
b. ApplicationManager
- Jsou odpovědní za přijímání zadaných úkolů.
- ApplicationManager vyjedná první kontejner pro spuštění ApplicationMaster pro konkrétní aplikaci.
- Poskytují službu pro restartování kontejneru ApplicationMaster při selhání.
- ApplicationMaster pro jednotlivé aplikace je zodpovědný za vyjednávání kontejnerů z Plánovače. Sleduje a monitoruje jejich stav a pokrok.
2. NodeManager:
NodeManager běží na podřízených uzlech. Zodpovídá za kontejnery, monitoruje využití prostředků stroje, což je CPU, paměť, disk, využití sítě, a hlásí totéž do ResourceManager nebo Plánovač.
3. ApplicationMaster:
ApplicationMaster pro jednotlivé aplikace je knihovna specifická pro daný rámec. Je zodpovědný za vyjednávání zdrojů z ResourceManager. Spolupracuje s NodeManager(y) pro provádění a monitorování úloh.
Shrnutí
V tomto článku jsme studovali architekturu Hadoop. Hadoop se řídí topologií master-slave. Hlavní uzly přidělují úkoly podřízeným uzlům. Architektura se skládá ze tří vrstev, kterými jsou HDFS, YARN a MapReduce.
HDFS je distribuovaný souborový systém v Hadoop pro ukládání velkých dat. MapReduce je zpracovatelský rámec pro zpracování rozsáhlých dat v clusteru Hadoop distribuovaným způsobem. YARN je zodpovědný za správu zdrojů mezi aplikacemi v clusteru.
Démon HDFS NameNode a démon YARN ResourceManager běží na hlavním uzlu v clusteru Hadoop. Démon HDFS DataNode a YARN NodeManager běží na podřízených uzlech.
HDFS a MapReduce framework běží na stejné sadě uzlů, což vede k velmi vysoké agregované šířce pásma napříč clusterem.
Pokračujte v učení!!