V našem předchozím tutoriálu Hadoop , studovali jsme Hadoop Partitioner podrobně. Nyní budeme diskutovat o InputSplit v Hadoop MapReduce.
Zde pokryjeme, co je Hadoop InputSplit, potřeba InputSplit v MapReduce. Velmi podrobně také probereme, jak jsou tyto InputSplits vytvářeny v Hadoop MapReduce.
Úvod do InputSplit v Hadoop
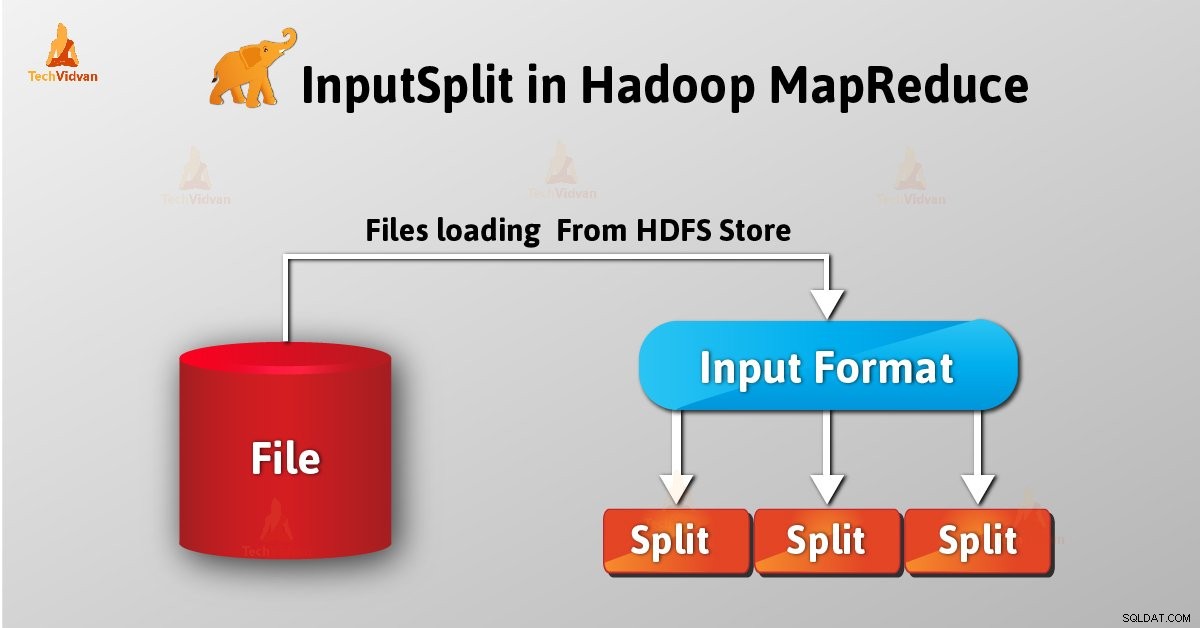
InputSplit je logická reprezentace dat v Hadoop MapReduce. Představuje data, která jednotlivec mapuje procesy. Počet mapových úloh se tedy rovná počtu InputSplits. Framework rozděluje na záznamy, které mapovač zpracovává.
Délka MapReduce InputSplit byla měřena v bajtech. Každý InputSplit má úložná místa (řetězce názvu hostitele). Systém MapReduce umísťuje mapové úlohy co nejblíže k datům rozdělení pomocí umístění úložiště.
Rámcové procesy Mapujte úlohy v pořadí podle velikosti rozdělení tak, aby byl jako první zpracován ten největší (algoritmus chamtivé aproximace). Tím se minimalizuje doba běhu úlohy.
Hlavní věc, na kterou je třeba se zaměřit, je, že Inputsplit neobsahuje vstupní data; je to jen odkaz na data.
Jak se v Hadoop MapReduce vytvářejí InputSplits?
Jako uživatel se nezabýváme InputSplit v Hadoop přímo, jako InputFormat (protože InputFormat je zodpovědný za vytvoření Inputsplit a rozdělení na záznamy) jej vytvoří. FileInputFormat rozdělí soubor na 128MB bloky.
Také nastavením mapred .min .rozdělit .velikost parametr v mapred-site .xml uživatel může změnit hodnotu podle potřeby. Také tím můžeme přepsat parametr v objektu Job, který se používá k odeslání konkrétní úlohy MapReduce.
Napsáním vlastního InputFormat můžeme také řídit, jak je soubor rozdělen na části.
InputSplit je definován uživatelem. Uživatel může také ovládat velikost rozdělení na základě velikosti dat v programu MapReduce. Počet mapových úloh při provádění úlohy MapReduce se tedy rovná počtu InputSplits.
Zavoláním ‘getSplit()‘ , klient vypočítá rozdělení na zakázku. Poté se odeslal hlavnímu serveru aplikace, který pomocí jejich umístění úložiště naplánuje úlohy mapy, které je zpracují v clusteru.
Po této úloze mapy předá rozdělení do createRecordReader() metoda. Z toho získá RecordReader pro rozdělení. Poté RecordReader vygeneruje záznam (pár klíč-hodnota) , kterou předá funkci mapy.
Závěr
Závěrem lze říci, že InputSplit představuje data, která jednotlivý mapovač zpracovává. Pro každý split je vytvořen jeden mapový úkol. InputFormat tedy vytvoří InputSplit.
Máte-li jakýkoli dotaz ohledně InputSplit v MapReduce, zanechte prosím komentář v sekci níže.