Tento blogový příspěvek představí jednoduchý příklad typu „ahoj světe“, jak získat data uložená v S3 indexovaná a obsluhovaná službou Apache Solr hostovanou v clusteru Data Discovery and Exploration v CDP. Pro zvědavé:DDE je předem připravená možnost nasazení clusteru optimalizovaná pro Solr v CDP a nedávno vydaná v technickém náhledu . V tomto blogu se budeme zabývat pouze prostředími AWS a S3. Možnosti nasazení Azure a ADLS jsou k dispozici také v technickém náhledu, ale budou popsány v budoucím příspěvku na blogu.
Ukážeme vám nejjednodušší scénář, abyste mohli snadno začít. Samozřejmě existují pokročilejší nastavení datového kanálu a bohatší schémata, ale je to dobrý výchozí bod pro začátečníky.
Předpoklady:
- Už máte účet CDP a máte práva pokročilého uživatele nebo správce pro prostředí, ve kterém plánujete tuto službu spustit.
Pokud nemáte účet CDP AWS, kontaktujte svého oblíbeného zástupce Cloudera nebo se zde zaregistrujte ke zkušební verzi CDP. - Máte namapovaná a nakonfigurovaná prostředí a identity. Přesněji řečeno, vše, co potřebujete, je mít namapování uživatele CDP na roli AWS, která uděluje přístup ke konkrétnímu segmentu s3, ze kterého chcete číst (a zapisovat do něj).
- Už máte nastavené heslo pro pracovní zátěž (FreeIPA).
- Máte spuštěný cluster DDE. Zde také naleznete další informace o používání šablon v CDP Data Hub.
- Máte přístup CLI k tomuto clusteru.
- Port SSH je na AWS otevřený jako pro vaši IP adresu. Veřejnou IP adresu jednoho z uzlů Solr můžete získat v podrobnostech clusteru Datahub. Zde se dozvíte, jak SSH do clusteru AWS.
- V segmentu S3 máte soubor protokolu, který je přístupný pro vašeho uživatele (v tomto příkladu
/sample.log). Pokud žádný nemáte, zde je odkaz na ten, který jsme použili.
Pracovní postup
Následující části vás provedou kroky k indexování dat pomocí nástroje Crunch Indexer Tool, který je dodáván s DDE.

Vytvořte kolekci pro uložení vašeho indexu
V HUE je návrhář indexu; pokud je však DDE v Tech Preview, bude poněkud v rekonstrukci a v tuto chvíli se nedoporučuje. Ale zkuste to, až DDE přejde na GA, a dejte nám vědět, co si myslíte.
Prozatím můžete vytvořit schéma a konfigurace Solr pomocí nástroje CLI ‚solrctl‘. Vytvořte konfiguraci s názvem „my-own-logs-config“ a kolekci nazvanou „my-own-logs“. To vyžaduje, abyste měli přístup CLI.
1. SSH do kteréhokoli z pracovních uzlů ve vašem clusteru.
2. kinit jako uživatel s oprávněním k vytvoření konfigurace kolekce:
kinit
3. Ujistěte se, že proměnná prostředí SOLR_ZK_ENSEMBLE je nastavena v /etc/solr/conf/solr-env.sh. Uložte jeho hodnotu, protože to bude vyžadováno v dalších krocích.
Stiskněte Enter a zadejte heslo pro pracovní zátěž (FreeIPA).
Například:
cat /etc/solr/conf/solr-env.sh
Očekávaný výstup:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Toto je automaticky nastaveno na hostitelích s rolí Solr Server nebo Gateway v Cloudera Manager.
4. Chcete-li vygenerovat konfigurační soubory pro kolekci, spusťte následující příkaz:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate je jednou z výchozích šablon dodávaných s Solr v CDP, ale jako šablona je neměnná. Pro účely tohoto pracovního postupu jej musíte zkopírovat a vytvořit tak nový, který je proměnlivý (k tomu slouží možnost immutable=false). To vám poskytuje flexibilní konfiguraci bez schématu. Vytvoření dobře navrženého schématu je něco, do čeho se vyplatí investovat čas návrhu, ale není to nutné pro průzkumné použití. Z tohoto důvodu je to nad rámec tohoto blogového příspěvku. Ve skutečném produkčním prostředí však důrazně doporučujeme používat dobře navržená schémata – a v případě potřeby rádi poskytneme odbornou pomoc!
5. Vytvořte novou kolekci pomocí následujícího příkazu:
kolekce solrctl --create my-own-logs -s 1 -c my-own-logs-config
Tím se vytvoří kolekce „my-own-logs“ založená na konfiguraci kolekce „my-own-logs-config“ na jednom datovém fragmentu.
6. Chcete-li ověřit, zda byla kolekce vytvořena, můžete přejít do uživatelského rozhraní správce Solr. Sbírka pro „vlastní protokoly“ bude dostupná prostřednictvím rozevíracího seznamu v levé navigační nabídce.

Indexujte svá data
Zde na jednoduchém příkladu popisujeme, jak nakonfigurovat a spustit vestavěný nástroj Crunch Indexer Tool pro rychlé indexování dat v S3 a obsluhu přes Solr v DDE. Vzhledem k tomu, že zabezpečení clusteru může využívat CM Auto TLS, Knox, Kerberos a Ranger, může „Spark submit“ záviset na aspektech, které nejsou uvedeny v tomto příspěvku.
Indexování dat z S3 je stejné jako indexování z HDFS.
Tyto kroky proveďte v uzlu Yarn worker (označovaném jako „Yarnworker“ ve webovém rozhraní Management Console).
1. SSH do vyhrazeného pracovního uzlu Yarn clusteru DDE jako správce Solr.
Chcete-li zjistit IP adresu pracovního uzlu Yarn, klikněte na Hardware na stránce s podrobnostmi o clusteru a poté přejděte na uzel „Yarnworker“.

2. Přejděte do adresáře zdrojů (nebo si jej vytvořte, pokud jej ještě nemáte:
cd
Jako adresář zdrojů použijte domovskou složku uživatele správce (
3. Kinit svého uživatele:
kinit
Stiskněte Enter a zadejte heslo pro pracovní zátěž (FreeIPA).
4. Spusťte následující příkaz curl, nahraďte
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. Vytvořte konfigurační soubor Morphline pro nástroj Crunch Indexer Tool, v tomto příkladu read-log-morphline.conf. Nahraďte
SOLR_LOCATOR :{ # Název sbírky solr kolekce :moje-vlastní-logy #zk ensemble zkHost :
Tento Morphline načte trasování zásobníku z daného souboru protokolu, poté zapíše protokol záznamu ladění a načte jej do zadaného Solr.
6. Vytvořte soubor log4j.properties pro konfiguraci protokolu:
log4j.rootLogger=INFO, A1# A1 je nastaveno na ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 používá PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Zkontrolujte, zda soubor, který chcete číst, existuje na S3 (pokud žádný nemáte, zde je odkaz na soubor, který jsme použili pro tento jednoduchý příklad:
aws s3 ls s3://
8. Spusťte příkaz spark-submit:
Nahraďte zástupné symboly v a s hodnotami, které jste nastavili.
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(najít $myDriverJarDir - maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar')export myDependencyJarFiles=$(najít $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1)export myDependencyJarPaths=$(najít $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir="
Pokud narazíte na podobnou zprávu, můžete ji ignorovat:
WARN metadata.Hive:Nepodařilo se zaregistrovat všechny funkce.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
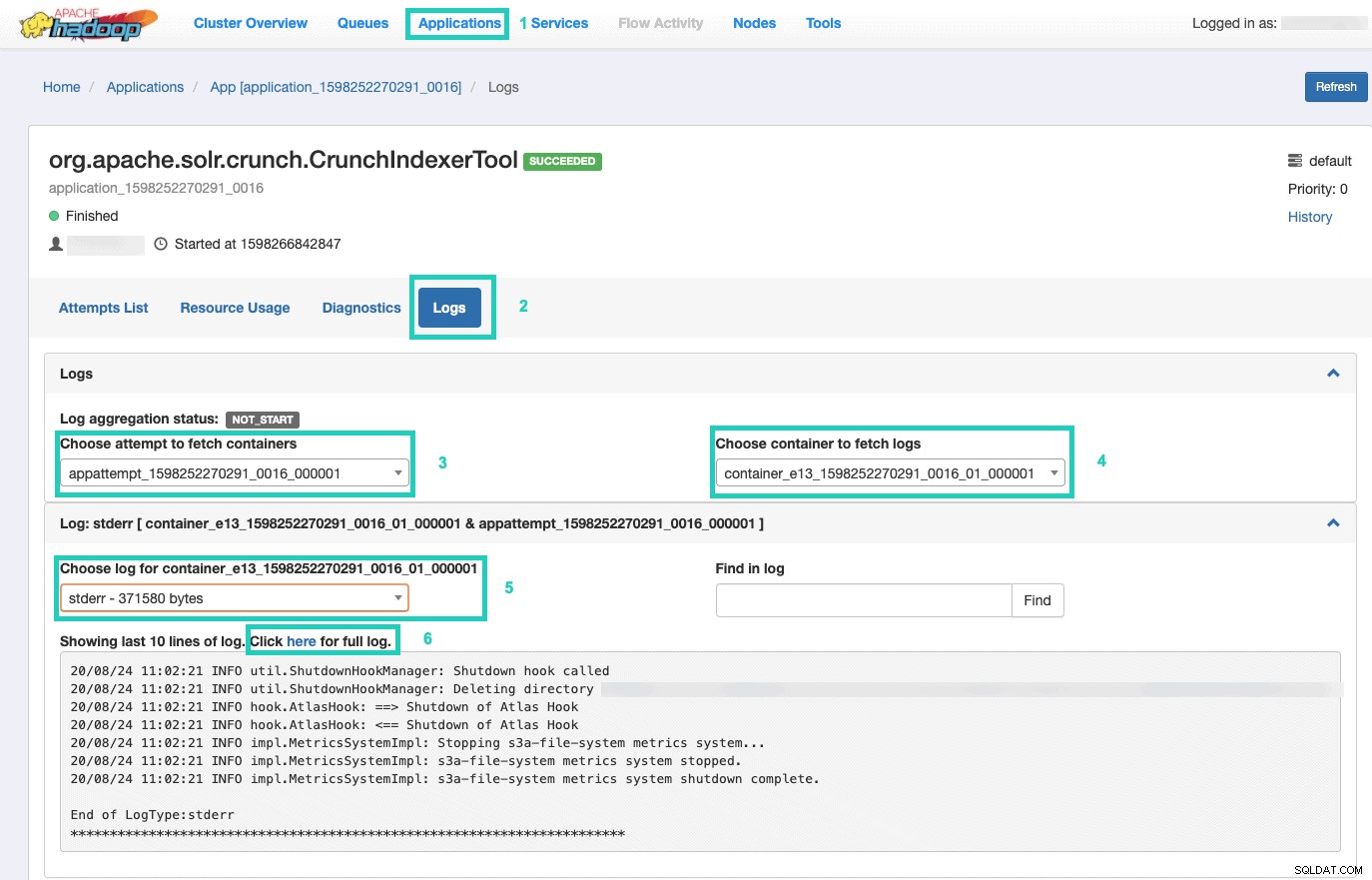
9. Chcete-li sledovat provádění příkazu, přejděte do Správce prostředků.

Až tam budete, vyberte Aplikace kartu > Klikněte na ID aplikace pokusu aplikace, který chcete sledovat > Vyberte Protokoly> Vybrat pokus o načtení kontejnerů> Vybrat kontejner pro načtení protokolů> Vybrat protokol pro kontejner> Vyberte stderr log> Klikněte na Kliknutím sem zobrazíte úplný protokol .
Poskytujte svůj index
Máte mnoho možností, jak poskytovat prohledávatelná indexovaná data koncovým uživatelům. Můžete si vytvořit svou vlastní bohatou aplikaci založenou na bohatých API Solr (velmi běžné). Můžete připojit svůj oblíbený nástroj třetí strany, jako je Qlik, Tableau atd. přes jejich certifikovaná připojení Solr. K vytváření prototypů aplikací můžete použít jednoduchý ovládací panel Solr společnosti Hue.
Postup:
1. Přejděte na Hue.

2. V zobrazení řídicího panelu přejděte na požadovaný indexový soubor (např. ten, který jste právě vytvořili).
3. Začněte přetahovat různé prvky řídicího panelu a výběrem polí z indexu naplňte data pro daný vizuál.
Rychlé instruktážní video z minulosti k dashboardu naleznete zde pro inspiraci.
Hlubší ponor si necháme na budoucí příspěvek na blogu.
Shrnutí
Doufáme, že jste se z tohoto příspěvku na blogu hodně naučili o tom, jak získat data v S3 indexovaná Solrem v DDE pomocí Crunch Indexer Tool. Samozřejmě existuje mnoho dalších způsobů (Spark v prostředí Data Engineering, Nifi v prostředí Data Flow, Kafka v prostředí Stream Management atd.), ale těmi se budeme zabývat v budoucích příspěvcích na blogu. Doufáme, že budete ve své další cestě k vytváření výkonných aplikací pro přehledy zahrnujících text a další nestrukturovaná data velmi úspěšní. Pokud se rozhodnete vyzkoušet DDE v CDP, dejte nám prosím vědět, jak to celé dopadlo!