Toto je psaná verze mého nového videa na youtube ✍️ 🙂
V tomto tutoriálu Redis se dozvíte o Redis a jak lze Redis použít jako primární databázi pro složité aplikace které potřebují ukládat data ve více formátech.
Přehled 📝
- Co je Redis a jeho použití a také proč je vhodný pro moderní komplexní mikroservisní aplikace?
- Jak Redis podporuje ukládání více formátů dat pro různé účely prostřednictvím svých modulů ?
- Jak může Redis jako databáze v paměti zachovat data a obnovit je po ztrátě dat ?
- Jak škálovat a replikovat Redis ?
- Nakonec, protože jednou z nejoblíbenějších platforem pro provozování mikroslužeb je Kubernetes a protože spouštění stavových aplikací v Kubernetes je trochu náročné, uvidíme, jak můžete snadno spustit Redis v Kubernetes
Co je Redis?
Redis znamená re mote dic tionary s erver
Redis je databáze v paměti . Mnoho lidí ji tedy použilo jako mezipaměť nad jinými databázemi ke zlepšení výkonu aplikace. 🤓
Mnoho lidí však neví, že Redis je plnohodnotná primární databáze které lze použít k uložení a zachování více datových formátů pro složité aplikace. 😎
Pojďme se tedy podívat na případy použití.
Proč vícemodelová databáze?
Podívejme se na běžné nastavení pro aplikaci mikroslužeb.
Řekněme, že máme komplexní aplikaci sociálních médií s miliony uživatelů. K tomu možná budeme muset uložit různé formáty dat v různých databázích:
- Relační databáze , jako je Mysql, k ukládání našich dat
- ElasticSearch pro rychlé vyhledávání a filtrování
- Databáze grafů reprezentovat spojení uživatelů
- Databáze dokumentů , jako je MongoDB k ukládání mediálního obsahu sdíleného našimi uživateli denně
- Služba mezipaměti pro lepší výkon aplikace
Je zřejmé, že se jedná o poměrně složité nastavení.
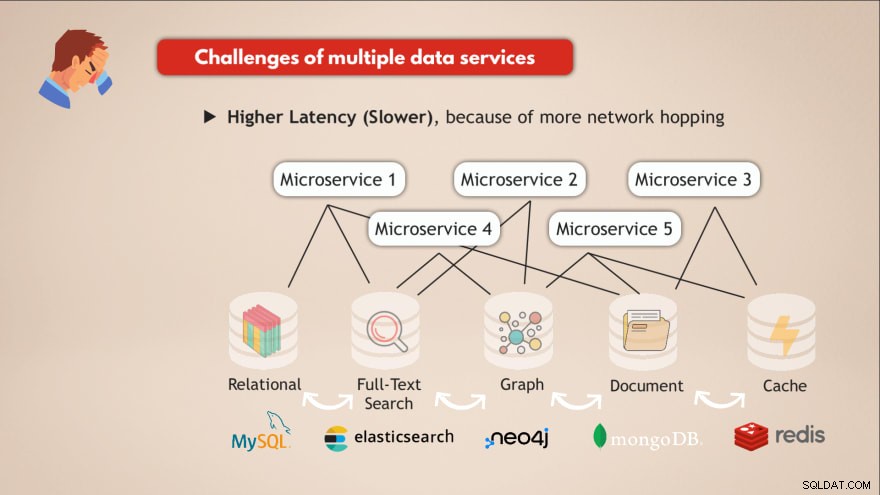
Problémy s více datovými službami
- ❌ Každá datová služba musí být nasazena a udržována
- ❌ Know-How potřebné pro každou datovou službu
- ❌ Různé požadavky na škálování a infrastrukturu
- ❌ Složitější aplikační kód pro interakci se všemi těmito různými databázemi
- ❌ Vyšší latence (pomalejší) kvůli většímu přeskakování sítě
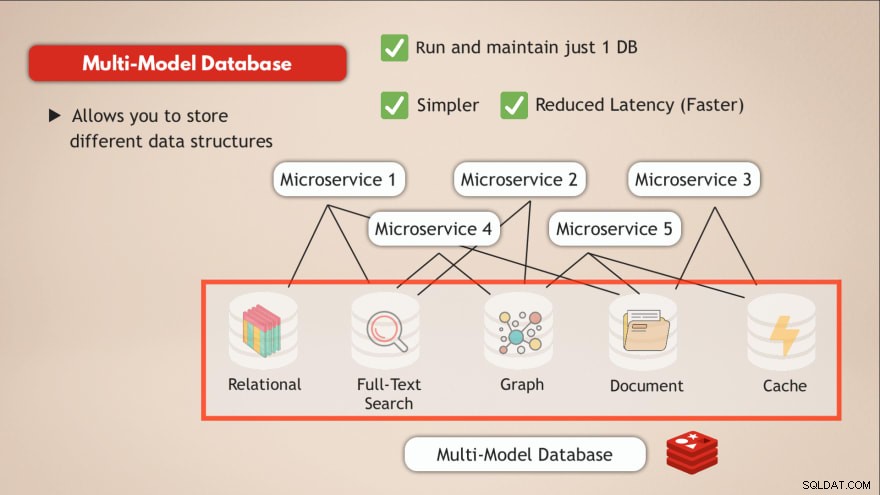
Mít databázi více modelů
Ve srovnání s multimodelovou databází vyřešíte většinu těchto problémů. Nejprve spustíte a spravujete pouze 1 datovou službu . Vaše aplikace tedy také potřebuje hovořit s jedním úložištěm dat a to vyžaduje pouze jedno programové rozhraní pro tuto datovou službu.
Kromě toho bude latence snížena přechodem na jeden datový koncový bod a odstraněním několika interních síťových rozbočovačů.
Takže mít jednu databázi, jako je Redis, která vám umožňuje ukládat různé typy dat nebo v podstatě umožňuje mít více typů databází v jedné a zároveň fungovat jako mezipaměť, řeší takové problémy.
- ✅ Provozujte a udržujte pouze 1 databázi
- ✅ Jednodušší
- ✅ Snížená latence (rychlejší)
Jak Redis funguje?
Moduly Redis 📦
Funguje to tak, že máte Redis Core, což je úložiště klíčových hodnot který již podporuje ukládání více typů dat a poté můžete toto jádro rozšířit o takzvané moduly pro různé typy dat , které vaše aplikace potřebuje pro různé účely. Takže například RediSearch pro funkce vyhledávání, jako je ElasticSearch nebo Redis Graph pro ukládání dat grafů a tak dále:

A skvělé na tom je, že je modulární . Tyto různé typy databázových funkcí tedy nejsou těsně integrovány do jedné databáze, ale spíše si můžete vybrat a vybrat přesně, kterou funkcionalitu datových služeb potřebujete pro svou aplikaci, a poté v podstatě přidat tento modul.
Předběžná mezipaměť ⚡️
Při použití Redis jako primární databáze samozřejmě nepotřebujete další mezipaměť, protože ji máte u Redis automaticky po vybalení. To opět znamená menší složitost vaší aplikace, protože nemusíte implementovat logiku pro správu naplňování a znehodnocování mezipaměti.
Redis je rychlý 🚀
Jako in-memory (data jsou uložena v RAM) databáze je Redis super rychlý a výkonný, což samozřejmě zrychluje samotnou aplikaci.
Ale v tuto chvíli vás může zajímat:
Jak může databáze v paměti uchovávat data? 🤔
Jak může Redis uchovat data a obnovit je po ztrátě dat? 🧐
Pokud selže proces Redis nebo server, na kterém Redis běží, všechna data v paměti jsou pryč? Jak jsou tedy data uchována a jak v podstatě mohu mít jistotu, že jsou moje data v bezpečí? 👀
Replikujete Redis?
No, nejjednodušší způsob, jak mít zálohy dat, je replikovat Redis . Pokud tedy hlavní instance Redis selže, repliky budou stále spuštěny a budou mít všechna data. Takže pokud máte replikovaný Redis, repliky budou mít data.
Ale samozřejmě, pokud všechny instance Redis selžou, ztratíte data, protože nezůstane žádná replika. 🤯 Takže potřebujeme skutečnou vytrvalost .
Snímání a AOF
Redis má několik mechanismů pro uchování dat a jejich uchování v bezpečí.
Snímky
První:snímky, které můžete konfigurovat podle času, počtu požadavků atd. Takže snímky vašich dat budou uloženy na disku , kterou můžete použít k obnovení dat, pokud je celá databáze Redis pryč.
Pamatujte však, že přijdete o poslední minuty dat , protože snímky obvykle provádíte každých pět minut nebo hodinu v závislosti na vašich potřebách. 😐
AOF
Redis tedy jako alternativu používá něco, co se nazývá AOF , což znamená A ppend O pouze F ile.
V tomto případě se každá změna uloží na disk, aby byla trvale zachována . A při restartování Redis nebo po výpadku Redis znovu přehraje protokoly Append Only File, aby znovu sestavil stav.
Takže AOF je odolnější , ale může být pomalejší než pořizování snímků.
Nejlepší možnost 💡 :Použijte kombinaci AOF a snímků, kde AOF nepřetržitě uchovává data z paměti na disk a mezi nimi máte pravidelné snímky pro uložení stavu dat pro případ, že je budete potřebovat obnovit:

Jak škálovat databázi Redis?
Řekněme, že mé 1 instanci Redis dojde paměť, takže data budou příliš velká na to, aby je udržela v paměti, nebo se Redis stane úzkým hrdlem a nemůže zpracovat žádné další požadavky. Jak v takovém případě zvýším kapacitu a velikost paměti pro moji databázi Redis? 🤔
Máme k tomu několik možností:
1. Shlukování
Za prvé, Redis podporuje shlukování . To znamená, že můžete mít primární nebo hlavní instanci Redis, kterou lze použít ke čtení a zápisu dat, a můžete mít několik replik této primární instance pro čtení dat :
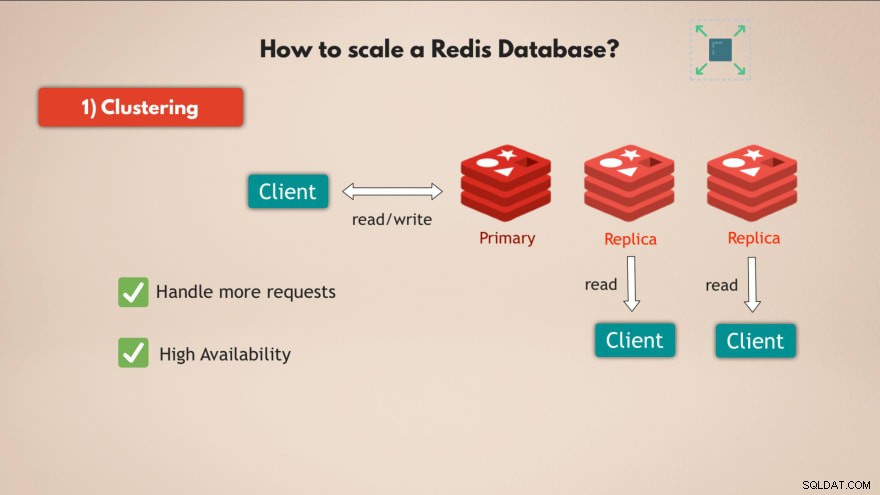
Tímto způsobem můžete škálovat Redis, aby zvládl více požadavků a navíc zvýšil vysokou dostupnost vaší databáze, protože pokud hlavní selže, 1 z replik může převzít kontrolu a vaše databáze Redis může v podstatě bez problémů fungovat dál.
2. Sharding
To se zdá být dost dobré, ale co když
- vaše datová sada je příliš velká, aby se vešla do paměti na jediném serveru .
- Navíc jsme škálovali čtení v databázi, takže všechny požadavky, které v podstatě pouze dotazují data. Ale naše hlavní instance je stále sama a stále musí zpracovávat všechny zápisy .
Jaké je zde tedy řešení? 🤔
K tomu používáme koncept sharding , což je obecný koncept v databázích a který podporuje i Redis.
Takže sharding v podstatě znamená, že vezmete kompletní soubor dat a rozdělíte jej na menší části nebo podmnožiny dat , kde každý fragment odpovídá za svou vlastní podmnožinu dat.
To tedy znamená, že místo jedné hlavní instance, která zpracovává všechny zápisy do kompletní datové sady, ji můžete rozdělit na řekněme 4 fragmenty, z nichž každý je zodpovědný za čtení a zápis do podmnožiny dat . 💡
A každý fragment také potřebuje menší kapacitu paměti , protože mají jen čtvrtinu dat. To znamená, že můžete distribuovat a spouštět fragmenty na menších uzlech a v zásadě škálovat svůj cluster horizontálně:
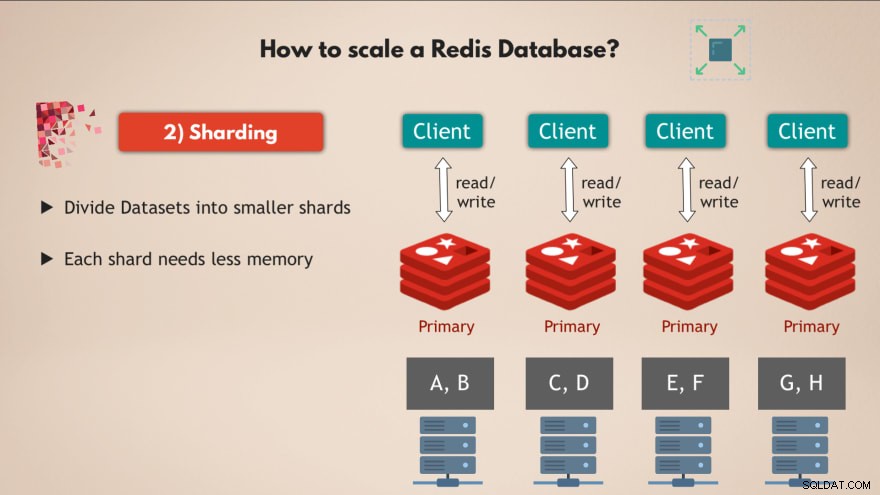
Tedy mít více uzlů , na kterých běží více replik z Redis, které jsou všechny střepy vám poskytuje velmi výkonnou a vysoce dostupnou databázi Redis, která dokáže zpracovat mnohem více požadavků bez vytváření překážek 👍
Další témata...
Podívejte se na mé video níže s posledními 2 tématy a scénáři:
- Aplikace, které vyžadují ještě vyšší dostupnost a výkon v různých geografických oblastech
- Novým standardem pro provozování mikroslužeb je platforma Kubernetes, takže spouštění Redis v Kubernetes je velmi zajímavý a běžný případ použití
Celé video je k dispozici zde:🤓
Doufám, že to bylo pro některé z vás užitečné a zajímavé! 😊
To se mi líbí, sdílejte a sledujte mě 😍 pro další obsah:
- Instagram – zveřejňování mnoha věcí ze zákulisí
- Soukromá FB skupina