Analýza šíření koronaviru SARS-CoV-2 nebyla mým vysněným případem použití . Ale na základě odpovědí na článek Ferry Djaja's Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA jsem se rozhodl přidat také své dva groše.
[Aktualizováno 20. 3. 30 se změněnými odkazy na zdrojová data; a nový mapový výstup založený na nové granularitě dat. Děkujeme Douglasi Maltbymu za váš komentář!]
Ferry ve svém příspěvku na blogu použil JavaScript v SAP HANA XSA k získání dat ze souborů CSV, které denně aktualizuje Univerzita Johnse Hopkinse.
Rád bych vám ukázal, jak můžete natáhnout a načíst tyto soubory do SAP HANA pomocí pouhých několika řádků kódu díky SAP HANA Python Client API pro strojové učení (hana_ml balíček).
Někteří lidé byli zmateni vizualizací na mapě na konci — vezměte prosím na vědomí, že tento článek se zaměřuje na technické případy použití propojující různé komponenty, nikoli na hloubkovou analýzu dat o koronaviru.
Získejte prostředí Python, např. Jupyter
K tomu použiji Jupyter v kontejneru Docker. Podívejte se prosím na můj předchozí příspěvek Pochopení kontejnerů (část 05):sdílené soubory mezi hostitelem a kontejnery, pokud nevíte, jak to spustit. Stejně tak můžete všechny stejné kroky níže provádět z jakéhokoli jiného prostředí Pythonu.
Takže mám svůj kontejner myjupyter01 běh. Jsem připojen k uživatelskému rozhraní Jupyter, jak je popsáno v předchozím blogu.
Nainstalujte hana_ml
Obrázek Jupyter, který jsem použil z registru Docker Hub, byl jupyter/minimal-notebook . Obsahuje již některé oblíbené balíčky pro zpracování dat, jako jsou pandas .
Ale navíc musím nainstalovat hana_ml , který je – ve své aktuální verzi 1.0.8 – dostupný v úložišti PyPI:https://pypi.org/project/hana-ml/.
Příkaz ke spuštění instalace je python -m pip install hana_ml , ale protože jej spouštím z notebooku Jupyter s jádrem Python3, musím jej spustit s ! na začátku:
!python -m pip install hana_ml
Je zřejmé, že tento krok instalace je třeba provést pouze jednou. Není třeba jej znovu spouštět ve stejném kontejneru, např. při opětovném načítání nejnovějších souborů.
Používejte pandas importovat soubory s daty
Naimportujme tři stejné soubory (confirmed , deaths , recovered ) z https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series jak Ferry použil ve svém příkladu.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
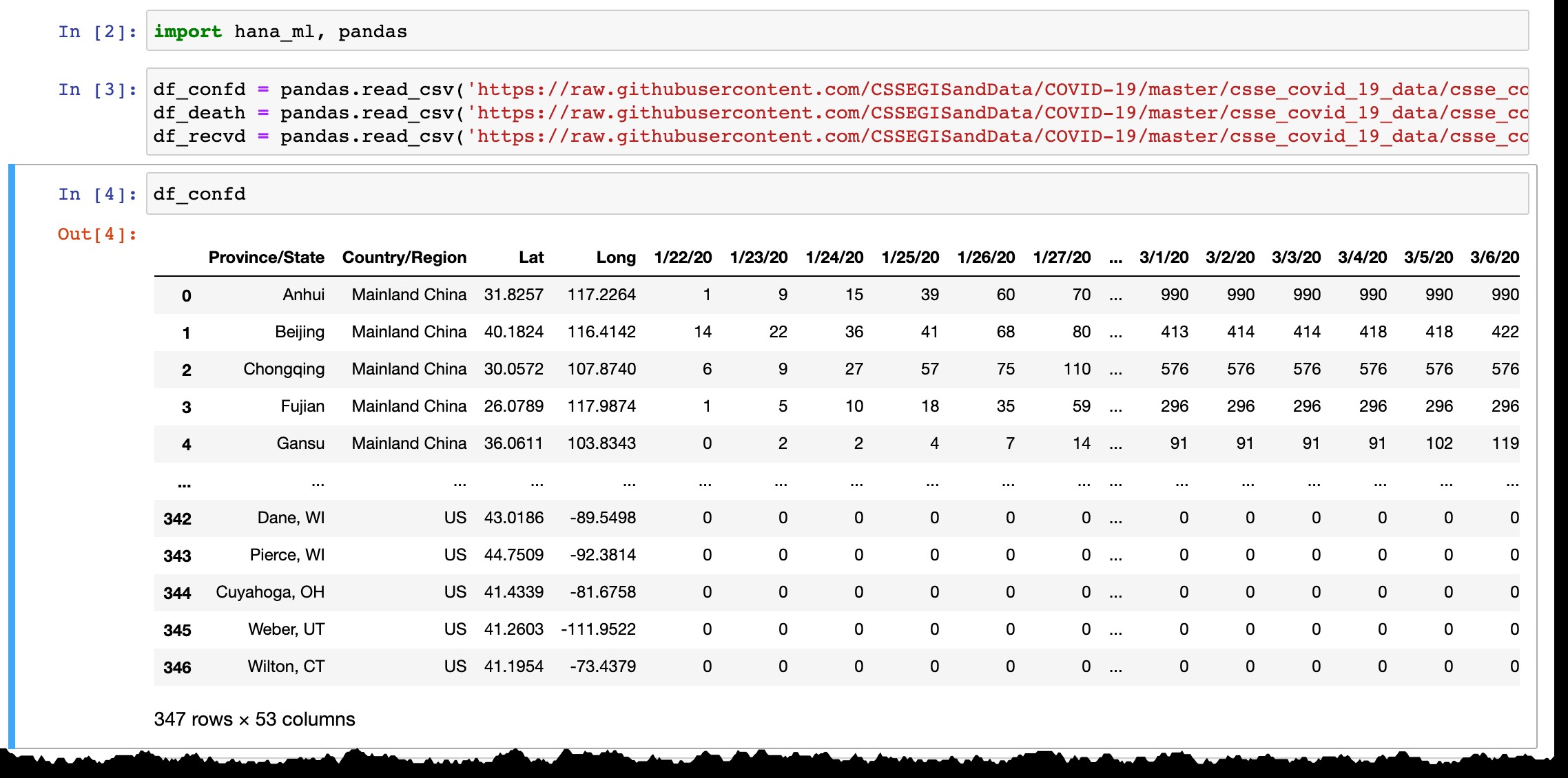
Jak můžete vidět z náhledu datového rámce Pandas, uvádí pouze země nebo provincie s potvrzenými případy a každý den je přidán nový sloupec s nejnovějšími daty z předchozího dne. Řádky jsou přidány, když je potvrzen první případ(y) v nové oblasti.
Používejte pandas k přeformátování datového rámce
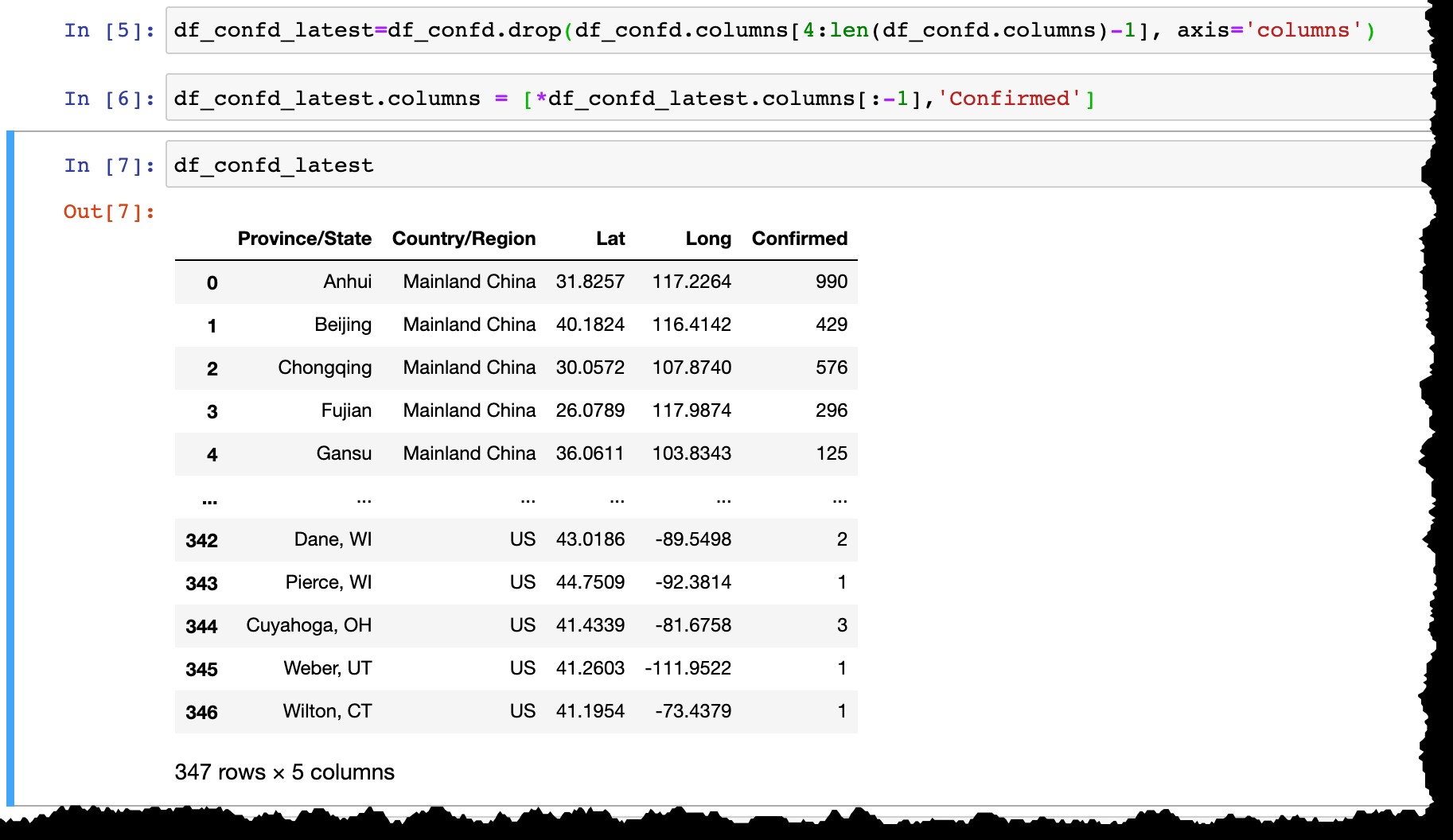
Před uložením dat do SAP HANA proveďte následující kroky:
- Odeberte všechny sloupce s datem kromě posledního,
- Přejmenujte poslední sloupec ze skutečného data (např. dnešní
3/10/20naConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Použijte hana_ml pro zachování dat v tabulce SAP HANA
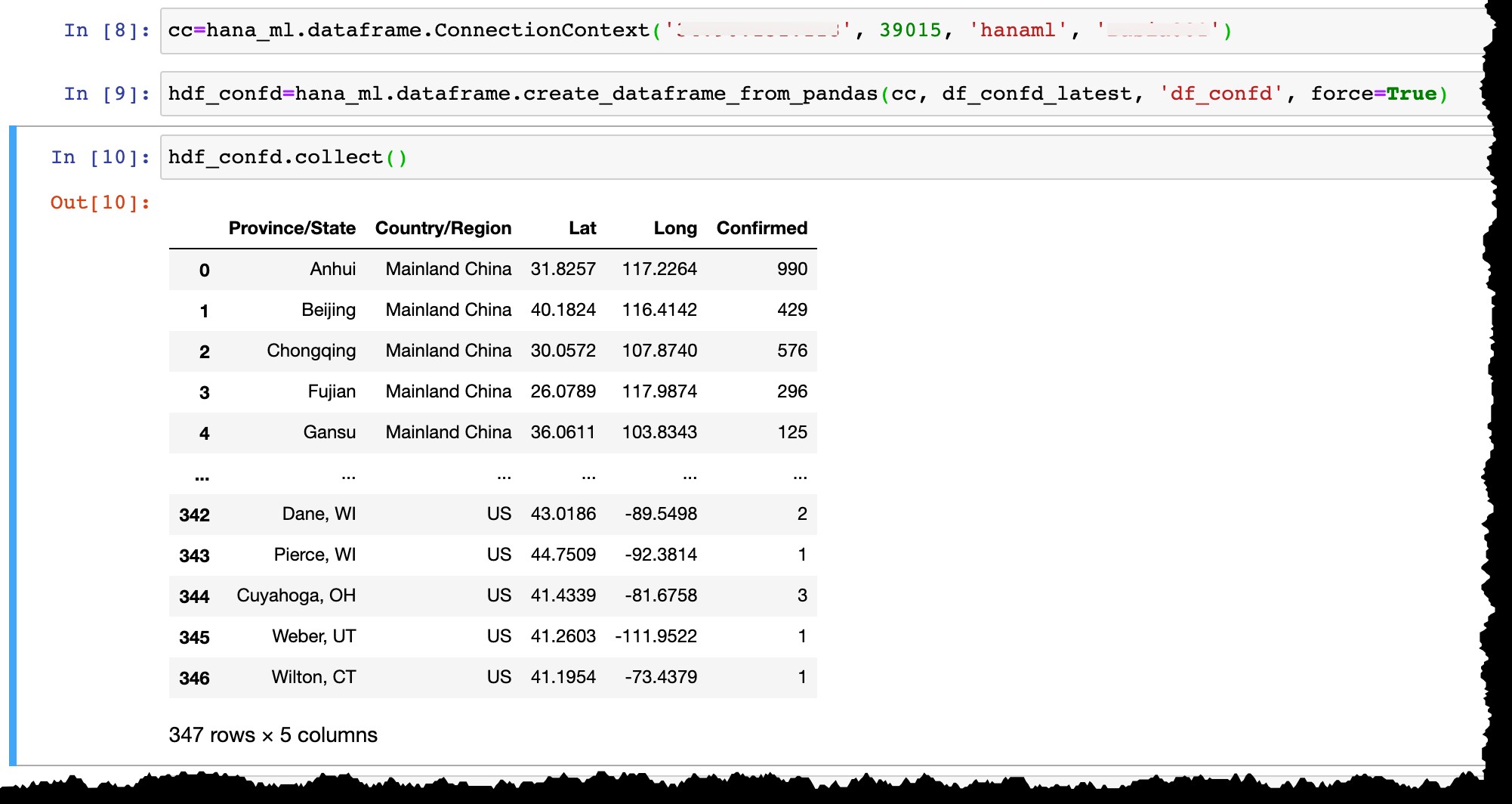
Nyní mi dovolte připojit se k mé instanci SAP HANA Express s uživatelem hanaml který tam již existuje…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…a převeďte datový rámec Pandas df_confd_latest do datového rámce HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Po vytvoření datového rámce HANA:
- V HANA se vytvoří tabulka fyzických sloupců a vloží se do ní data z datového rámce Pandas,
- Datový rámec HANA
hdf_confdv Pythonu neukládá žádná data do vašeho notebooku, ale pouze ukazuje na tabulkuHANAML.df_confdv paměti serveru SAP HANA a všechny operace Pythonu na datovém rámci HANA jsou fyzicky prováděny v HANA db bez přesouvání dat mezi serverem a klientem, - Chceme-li zobrazit výsledek jakékoli operace, musíme použít
collect()metoda pro převod datového rámce HANA na Pandas (a v důsledku toho přenesení dat ze serveru HANA db do místního klienta).
Použijte DBeaver ke kontrole dat v SAP HANA…
Možná si pamatujete, že jsem již používal DBeaver – bezplatný databázový nástroj podporující SAP HANA – v mém předchozím příspěvku „GeoArt se SAP HANA a DBeaver“.
Nyní to znovu používám a skutečně mohu najít tabulku df_confd ve schématu HANAML se všemi daty ze zdrojového datového rámce Pandas.
…a proveďte prostorový náhled
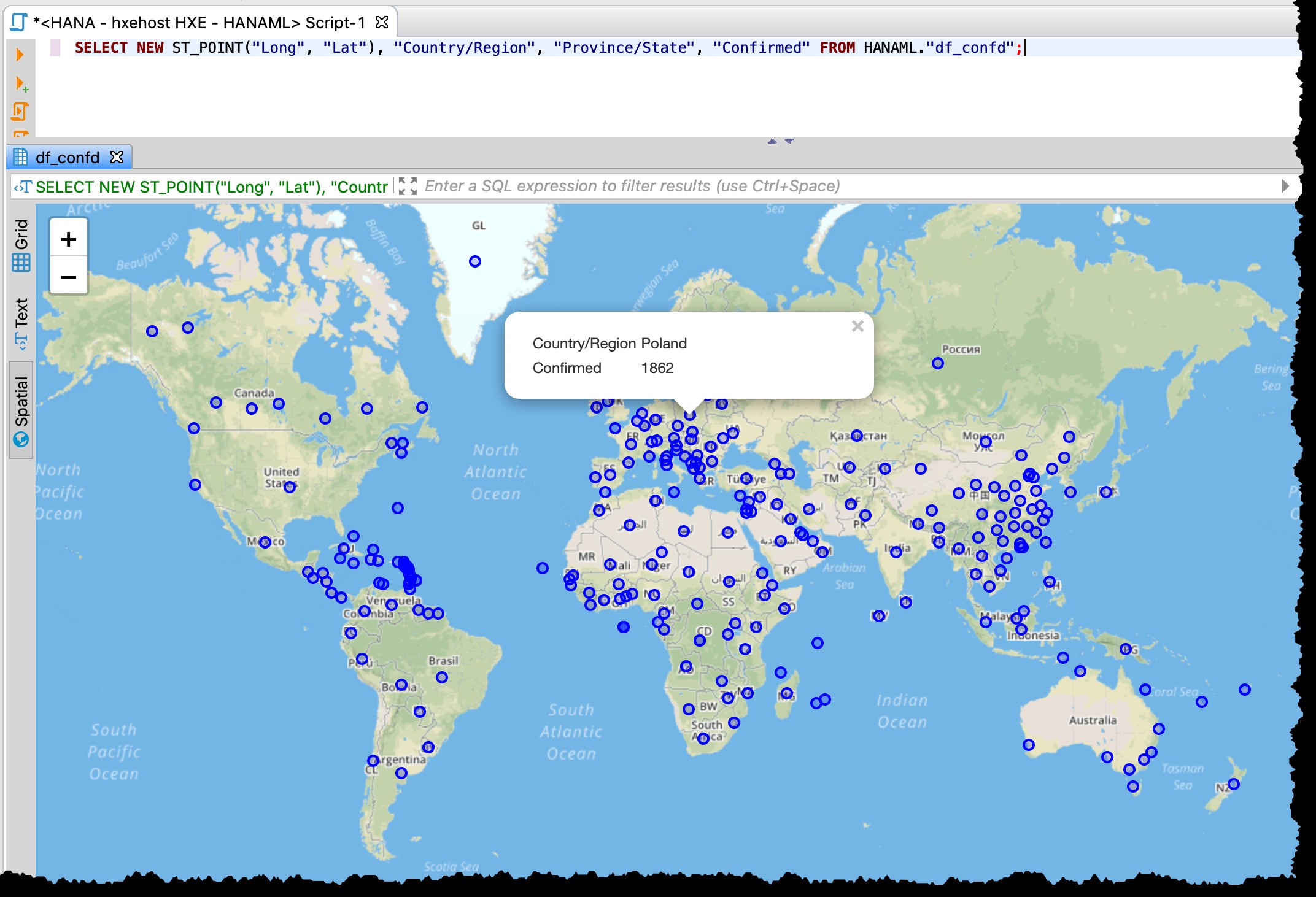
Protože tabulka obsahuje sloupce zeměpisné šířky a délky, mohu si přímo z DBeaveru vizualizovat dotčené země/státy pomocí následujícího SQL pomocí náhledu prostorových dat.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Potřeboval jsem změnit projekci mapy na EPSG:4326 získat tyto body na mapě. A DBeaver mi zobrazí zbytek dat záznamu, když kliknu na jakýkoli bod.
[Níže je starý snímek obrazovky z 2020-03-11, který také demonstruje různou granularitu např. Údaje z USA používané v té době]
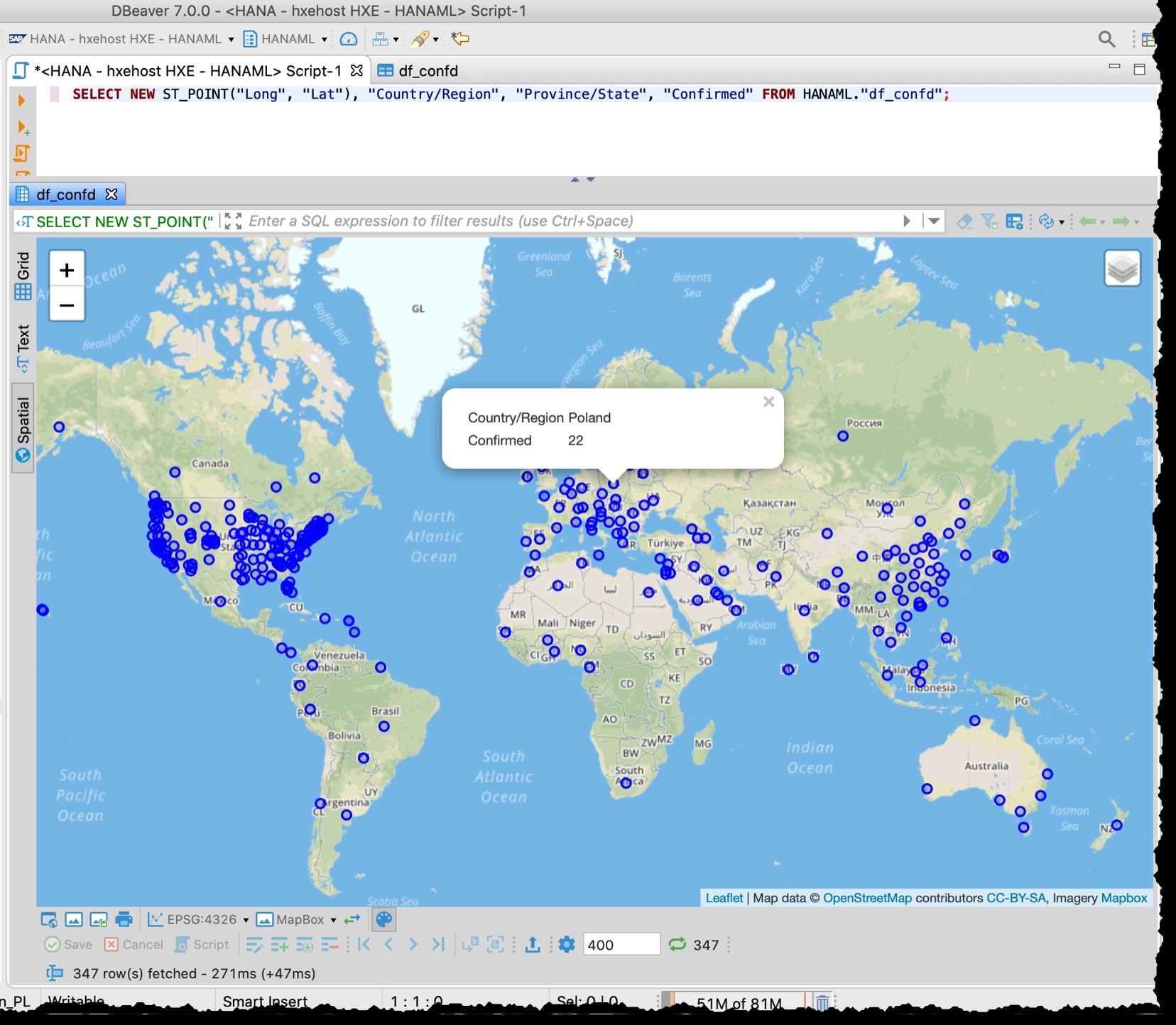
Prostorový náhled DBeaver není plnohodnotným nástrojem pro vizuální průzkum geoprostoru. Přesto je dost dobré vidět ovlivněné země/oblasti (v závislosti na podrobnosti ve zdrojových souborech).
Měli byste mít zájem dozvědět se více o hana_ml …
… pak bych určitě doporučil zkontrolovat Hands-On Tutorial:Machine Learning push-down to SAP HANA with Python by Andreas Forster.
HANA ML je součástí nového tématu „Advanced Analytics with SAP HANA“ pro události CodeJam. Bohužel kvůli situaci s koronavirem jsme museli zrušit první, které tento měsíc pořádal Jakob Flaman v Bernu. Další pořádá Ewelina Pękała 27. května v Katovicích:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Doufejme, že se do té doby situace normalizuje a nebudeme muset rušit ani tuto.