Úvod
Ukládání dat je jedna věc; ukládání smysluplné, užitečné, správné data jsou úplně jiná. Zatímco význam a užitečnost jsou samy o sobě subjektivní vlastnosti, správnost lze přinejmenším logicky definovat a vynutit. Typy již zajišťují, že čísla jsou čísla a data jsou data, ale nemohou zaručit, že váha nebo vzdálenost jsou kladná čísla, ani zabránit překrývání období. Omezení n-tice, tabulky a databáze aplikují pravidla na ukládaná data a odmítají hodnoty nebo kombinace hodnot, které neprojdou seskupením.
Omezení nečiní jiné techniky ověřování vstupu v žádném případě nepoužitelnými, ani když testují stejná tvrzení. Čas strávený pokusy a neúspěšným ukládáním neplatných dat je ztracený čas. Zprávy o porušení, jako je assert v systémech a aplikačních programovacích jazycích pouze odhalí první problém s prvním kandidátským záznamem mnohem podrobněji, než potřebuje kdokoli, kdo se bezprostředně nezabývá databází. Ale pokud jde o správnost dat, omezení jsou zákonem, ať už dobrá nebo špatná; cokoli jiného je rada.
Na nicích:Not Null, Default a Check
Nenulová omezení jsou nejjednodušší kategorií. N-tice musí mít hodnotu pro omezený atribut, nebo jinak řečeno, sada povolených hodnot pro sloupec již neobsahuje prázdnou sadu. Žádná hodnota znamená žádnou n-tici:vložení nebo aktualizace jsou odmítnuty.
Ochrana proti hodnotám null je stejně snadná jako deklarace column_name COLUMN_TYPE NOT NULL v CREATE TABLE nebo ADD COLUMN . Hodnoty Null způsobují celé kategorie problémů mezi databází a koncovými uživateli, takže reflexivní definování nenulových omezení v jakémkoli sloupci bez dobrého důvodu povolit hodnoty null je dobrým zvykem.
Poskytnutí výchozí hodnoty, pokud není nic specifikováno (vynecháním nebo explicitním NULL ) ve vložení nebo aktualizaci není vždy považováno za omezení, protože kandidátské záznamy jsou upraveny a uloženy namísto zamítnutí. V mnoha DBMS mohou být výchozí hodnoty generovány funkcí, ačkoli MySQL pro tento účel nepovoluje uživatelem definované funkce.
Jakékoli jiné ověřovací pravidlo, které závisí pouze na hodnotách v rámci jedné n-tice, lze implementovat jako CHECK omezení. V jistém smyslu NOT NULL sám o sobě je zkratkou pro CHECK (column_name IS NOT NULL); chybová zpráva přijatá v rozporu je největší rozdíl. CHECK , však může použít a vynutit pravdivost libovolného booleovského predikátu na jedné n-tice. Například tabulka obsahující zeměpisné polohy by měla CHECK (latitude >= -90 AND latitude < 90) a podobně pro zeměpisnou délku mezi -180 a 180 – nebo, je-li k dispozici, použijte a ověřte GEOGRAPHY datový typ.
V tabulkách:Jedinečné a vyloučené
Omezení na úrovni tabulky testují n-tice proti sobě. V rámci jedinečného omezení může mít pouze jeden záznam jakoukoli danou sadu hodnot pro omezené sloupce. Možnost null zde může způsobit problémy, protože NULL nikdy se nerovná ničemu jinému, až do NULL včetně sám. Jedinečné omezení pro (batman, robin) proto umožňuje nekonečné kopie jakéhokoli Robinless Batmana.
Omezení vyloučení jsou podporována pouze v PostgreSQL a DB2, ale vyplňují velmi užitečnou mezeru:mohou zabránit překrývání. Zadejte omezená pole a operace, kterými bude každé hodnoceno, a nový záznam bude přijat pouze v případě, že žádný existující záznam nebude úspěšně porovnán s každým polem a operací. Například schedules tabulku lze nakonfigurovat tak, aby odmítala konflikty:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upsert operace, jako je PostgreSQL ON CONFLICT klauzule nebo MySQL ON DUPLICATE KEY UPDATE k detekci konfliktů použijte omezení na úrovni tabulky. A stejně jako nenulová omezení mohou být vyjádřena jako CHECK omezení, lze jedinečné omezení vyjádřit jako vylučovací omezení rovnosti.
Primární klíč
Jedinečná omezení mají zvláště užitečný speciální případ. S dalším nenulovým omezením na jedinečný sloupec nebo sloupce lze každý záznam v tabulce samostatně identifikovat podle jeho hodnot pro omezené sloupce, které se souhrnně nazývají klíč . V tabulce může koexistovat více kandidátních klíčů, například users ještě někdy mít zřetelný jedinečný a nenulový email s a username s; ale deklarace primárního klíče stanoví jediné kritérium, podle kterého jsou záznamy veřejně a výlučně známé. Některé RDBMS dokonce organizují řádky na stránkách podle primárního klíče, který se pro tento účel nazývá shlukovaný index , aby bylo vyhledávání podle hodnot primárního klíče co nejrychlejší.
Existují dva typy primárního klíče. Přirozený klíč je definován na sloupci nebo sloupcích „přirozeně“ zahrnutých v datech tabulky, zatímco náhradní nebo syntetický klíč je vynalezen pouze za účelem, aby se stal klíčem. Přirozené klíče vyžadují péči – změnit se může více věcí, než návrháři databází často připisují, od jmen po schémata číslování. Vyhledávací tabulka obsahující názvy zemí a oblastí může používat jejich příslušné kódy ISO 3166 jako bezpečný přirozený primární klíč, ale users tabulka s přirozeným klíčem založeným na měnitelných hodnotách, jako jsou jména nebo e-mailové adresy, přináší potíže. V případě pochybností vytvořte náhradní klíč.
Pokud přirozený klíč zahrnuje více sloupců, měl by se vždy alespoň zvážit náhradní klíč, protože vícesloupcové klíče vyžadují více úsilí při správě. Pokud však vyhovuje přirozený klíč, měly by být sloupce seřazeny se zvyšující se přesností, stejně jako v indexech:kód země pak kód regionu, nikoli naopak.
Náhradním klíčem byl historicky sloupec s jedním celým číslem, neboli BIGINT kde budou nakonec přiděleny miliardy. Relační databáze mohou automaticky vyplnit náhradní klíče dalším celým číslem v řadě, což se obvykle nazývá SERIAL nebo IDENTITY .
Automaticky se zvyšující číselné počítadlo není bez nevýhod:přidávání záznamů s předem vygenerovanými klíči může způsobit konflikty, a pokud jsou uživatelům vystaveny sekvenční hodnoty, je pro ně snadné uhodnout, jaké další platné klíče mohou být. Univerzálně jedinečné identifikátory neboli UUID se těmto nedostatkům vyhýbají a staly se běžnou volbou pro náhradní klíče, i když jsou na stránce také mnohem větší než pouhé číslo. Nejčastěji se používají typy UUID v1 (na základě adresy MAC) a v4 (pseudonáhodné).
V databázi:cizí klíče
Relační databáze implementují pouze jednu třídu omezení pro více tabulek,
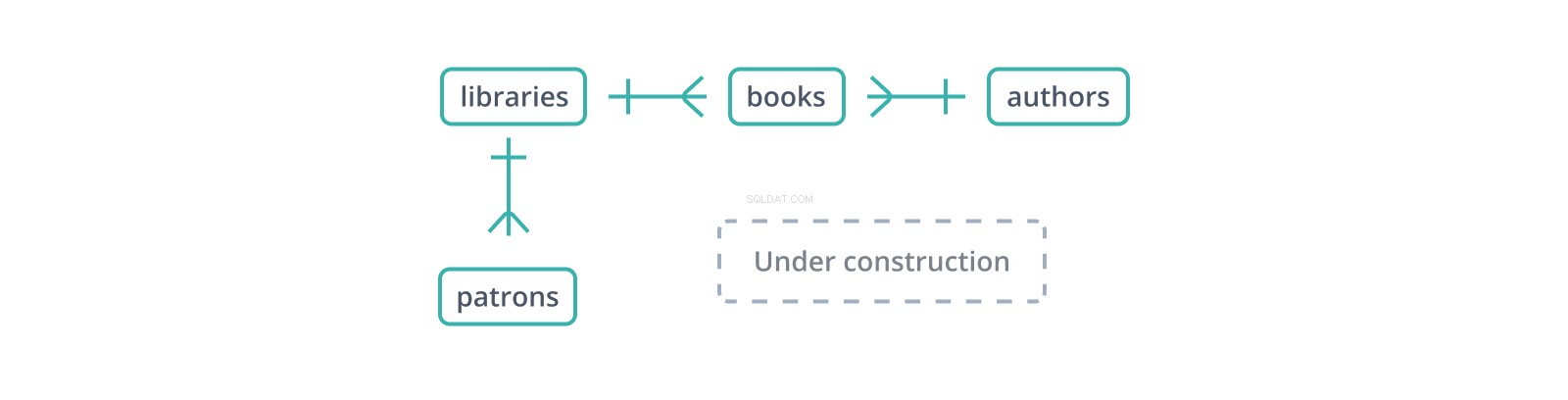
Tento neformální „diagram vztahů entit“ neboli ERD ukazuje počátky schématu pro databázi knihoven a jejich sbírek a patronů. Každá hrana představuje vztah mezi tabulkami, které spojuje. | glyf označuje jeden záznam na své straně, zatímco glyf "vrána noha" představuje několik:knihovna obsahuje mnoho knih a má mnoho čtenářů.
Cizí klíč je kopie primárního klíče jiné tabulky, sloupec po sloupci (bod ve prospěch náhradních klíčů:pouze jeden sloupec ke kopírování a odkazování), s hodnotami spojujícími záznamy v této tabulce s „nadřazenými“ záznamy v této tabulce. Ve výše uvedeném schématu books tabulka udržuje library_id cizí klíč do libraries , která obsahuje knihy, a author_id na authors , kteří je píší. Co se ale stane, když je kniha vložena s author_id který v authors neexistuje ?
Pokud cizí klíč není omezen – tj. je to jen další sloupec nebo sloupce – kniha může mít autora, který neexistuje. To je problém:pokud se někdo pokusí sledovat odkaz mezi books a authors , nikde nekončí. Pokud authors.author_id je sériové celé číslo, existuje také možnost, že si toho nikdo nevšimne, dokud si nevšimne falešného author_id je nakonec přiřazen a vy skončíte s konkrétní kopií Dona Quijota připisováno nejprve nikomu neznámému a poté Pierru Menardovi, přičemž Miguela Cervantese nikde nenašel.
Omezení cizího klíče nemůže zabránit tomu, aby byla kniha nesprávně přiřazena v případě chybného author_id přejděte na existující záznam v authors , takže další kontroly a testy zůstávají důležité. Sada existujících hodnot cizích klíčů je však téměř vždy malou podmnožinou možných hodnoty cizího klíče, takže omezení cizího klíče zachytí a zabrání většině nesprávných hodnot. S omezením cizího klíče, Quixote s neexistujícím autorem bude místo zaznamenáno odmítnuto.
Odkud pochází "relační" v "relační databázi"?
Cizí klíče vytvářejí vztahy mezi tabulkami, ale tabulky, jak je známe, jsou matematicky vztahy mezi sady možných hodnot pro každý atribut. Jedna n-tice spojuje hodnotu pro sloupec A s hodnotou pro sloupec B a dále. Původní práce E.F. Codda používá v tomto smyslu slovo „relační“.
To nezpůsobilo žádný zmatek a pravděpodobně tomu tak bude i nadále.
Pro určité hodnoty správnosti
Existuje mnohem více způsobů, jak mohou být data nesprávná, než je zde uvedeno. Omezení pomáhají, ale i ta jsou jen tak flexibilní; mnoho běžných specifikací uvnitř tabulky, jako je například limit dvě nebo vyšší, kolikrát se hodnota může objevit ve sloupci, lze vynutit pouze pomocí spouštěčů.
Existují však také způsoby, jak samotná struktura tabulky může vést k nesrovnalostem. Abychom tomu zabránili, budeme muset zařadit primární i cizí klíče nejen k definování a ověření, ale také k normalizaci vztahy mezi tabulkami. Zaprvé jsme však sotva poškrábali povrch toho, jak vztahy mezi tabulkami definují strukturu samotné databáze.