Úvod
Existují dva směry myšlení o provádění výpočtů ve vaší databázi:lidé, kteří si myslí, že je to skvělé, a lidé, kteří se mýlí. To neznamená, že svět funkcí, uložených procedur, generovaných nebo počítaných sloupců a spouštěčů je jen slunce a růže! Tyto nástroje nejsou ani zdaleka spolehlivé a nepromyšlené implementace mohou fungovat špatně, traumatizovat jejich správce a další, což do jisté míry vysvětluje existenci kontroverze.
Ale databáze jsou ze své definice velmi dobré ve zpracování a manipulaci s informacemi a většina z nich stejnou kontrolu a výkon zpřístupňuje svým uživatelům (SQLite a MS Access v menší míře). Externí programy pro zpracování dat začínají na zadní noze a musí vytahovat informace z databáze, často přes síť, než mohou něco udělat. A tam, kde databázové programy mohou plně využít operací nativních množin, indexování, dočasných tabulek a dalších plodů půlstoletí evoluce databází, mají externí programy jakékoli složitosti tendenci zahrnovat určitou úroveň znovuobjevení kola. Proč tedy nezprovoznit databázi?
Zde je důvod, proč nemůžete chcete naprogramovat svou databázi!
- Funkce databáze má tendenci stát se neviditelnou – zejména spouštěče. Tato slabina se škáluje přibližně s velikostí týmů a/nebo aplikací interagujících s databází, protože méně lidí si pamatuje nebo si je vědomo programování v databázi. Dokumentace pomáhá, ale jen tolik.
- SQL je jazyk určený k manipulaci s datovými sadami. Není zvlášť dobrý ve věcech, které nemanipulují s datovými soubory, a je tím méně dobrý, čím složitější jsou ty ostatní věci.
- Možnosti RDBMS a dialekty SQL se liší. Jednoduché generované sloupce jsou široce podporovány, ale portování složitější databázové logiky do jiných obchodů vyžaduje čas a úsilí minimálně.
- Upgrady schématu databáze jsou obvykle náročnější než upgrady aplikací. Rychle se měnící logiku je nejlepší udržovat jinde, i když to může stát za další pohled, jakmile se věci stabilizují.
- Správa databázových programů není tak přímočará, jak by se dalo doufat. Mnoho nástrojů pro migraci schémat dělá pro organizaci jen málo nebo vůbec nic, což vede k rozlehlým rozdílům a obtížným kontrolám kódu (grafy závislostí sqitche a přepracování jednotlivých objektů z toho činí výraznou výjimku a migra se snaží problém zcela obejít). Při testování rámce jako pgTAP a utPLSQL vylepšují integrační testy black-box, ale také představují další závazek podpory a údržby.
- Se zavedenou externí kódovou základnou bývá jakákoli strukturální změna náročná a riskantní.
Na druhou stranu pro úkoly, pro které se hodí, nabízí SQL rychlost, stručnost, trvanlivost a možnost „kanonizovat“ automatizované pracovní postupy. Datové modelování je víc než přichycení entit jako hmyzu na karton a rozlišení mezi daty v pohybu a daty v klidu je složité. Odpočinek je opravdu pomalejší pohyb v jemnějším stupni; informace vždy proudí odsud tam a programovatelnost databází je mocným nástrojem pro správu a směrování těchto toků.
Některé databázové stroje rozdělují rozdíl mezi SQL a jinými programovacími jazyky tím, že přizpůsobují i tyto další programovací jazyky. SQL Server podporuje funkce napsané v libovolném jazyce .NET Framework; Oracle má uložené procedury Java; PostgreSQL umožňuje rozšíření s C a je uživatelsky programovatelný v Pythonu, Perlu a Tcl, s pluginy přidávajícími shell skripty, R, JavaScript a další. Když doplníme obvyklé podezřelé, je to SQL nebo nic pro MySQL a MariaDB, MS Access je pouze programovatelný ve VBA a SQLite není uživatelsky programovatelný vůbec.
Použití jiných než SQL jazyků je možností, pokud je SQL pro nějaký úkol nedostačující nebo pokud chcete znovu použít jiný kód, ale neobejdete se s dalšími problémy, které z databázového programování dělají mnohosečný meč. Pokud něco takového, uchýlit se k nim dále komplikuje nasazení a interoperabilitu. Upozornění skriptora:nechť se má spisovatel na pozoru.
Funkce vs. procedury
Stejně jako u jiných aspektů implementace standardu SQL se přesné detaily u jednotlivých RDBMS trochu liší. Obecně:
- Funkce nemohou řídit transakce.
- Funkce vrací hodnoty; procedury mohou měnit parametry označené
OUTneboINOUTkteré pak lze číst ve volajícím kontextu, ale nikdy nevrací výsledek (s výjimkou serveru SQL). - Funkce se vyvolávají z příkazů SQL, aby prováděly nějakou práci na záznamech, které se načítají nebo ukládají, zatímco procedury jsou samostatné.
Přesněji řečeno, MySQL také nepovoluje rekurzi a některé další příkazy SQL ve funkcích. SQL Server zakazuje funkcím upravovat data, spouštět dynamické SQL a zpracovávat chyby. PostgreSQL do roku 2017 s verzí 11 vůbec neodděloval uložené procedury od funkcí, takže funkce Postgresu mohou dělat téměř vše, co procedury dokážou, s výjimkou kontroly transakcí.
Kdy tedy použít? Funkce jsou nejvhodnější pro logiku, která používá záznam po záznamu při ukládání a načítání dat. Složitější pracovní postupy, které se vyvolávají samy o sobě a přesouvají data interně, jsou lepší jako procedury.
Výchozí a generování
I jednoduché výpočty mohou způsobit potíže, pokud jsou prováděny dostatečně často nebo pokud existuje více konkurenčních implementací. Operace s hodnotami v jednom řádku – například převod mezi metrickými a imperiálními jednotkami, násobení sazby odpracovanými hodinami pro mezisoučty faktur, výpočet plochy geografického mnohoúhelníku – lze deklarovat v definici tabulky, aby se vyřešil jeden nebo druhý problém. :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Většina RDBMS nabízí výběr mezi "uloženými" a "virtuálními" generovanými sloupci. V prvním případě se hodnota vypočítá a uloží při vložení nebo aktualizaci řádku. Toto je jediná možnost s PostgreSQL od verze 12 a MS Access. Virtuálně generované sloupce se při dotazu počítají jako v pohledech, takže nezabírají místo, ale budou se častěji přepočítávat. Oba druhy jsou přísně omezeny:hodnoty nemohou záviset na informacích mimo řádek, do kterého patří, nelze je aktualizovat a jednotlivé RDBMS mohou mít ještě konkrétnější omezení. PostgreSQL například zakazuje rozdělení tabulky na vygenerovaný sloupec.
Vygenerované sloupce jsou specializovaným nástrojem. Častěji je vše, co je potřeba, výchozí v případě, že na vložce není zadána hodnota. Funkce jako now() často se zobrazují jako výchozí sloupce, ale většina databází umožňuje vlastní i vestavěné funkce (kromě MySQL, kde je pouze current_timestamp může být výchozí hodnota).
Vezměme si poněkud suchý, ale jednoduchý příklad čísla šarže ve formátu YYYYXXX, kde první čtyři číslice představují aktuální rok a poslední tři číslice zvyšující se počítadlo:první šarže vyrobená v tomto roce je 2020001, druhá 2020002 atd. . Neexistuje žádný výchozí typ nebo vestavěná funkce, která by generovala hodnotu jako je tato, ale uživatelsky definovaná funkce může očíslovat každou šarži
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Odkazování na data ve funkcích
Výše uvedený sekvenční přístup má jednu důležitou slabinu (a lot_counter bude mít stále stejnou hodnotu jako 31. prosince. Existuje však více než jeden způsob, jak sledovat, kolik položek bylo vytvořeno za rok, a pomocí dotazu lots sám o sobě next_lot_number Funkce může zaručit správnou hodnotu po přeběhnutí roku.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Pracovní postupy
Dokonce i funkce s jedním příkazem má zásadní výhodu oproti externímu kódu:provádění nikdy neopustí bezpečnost záruk ACID databáze. Porovnejte next_lot_number výše k možnostem klientské aplikace nebo i manuálního procesu, spouštějícího
Uložené programy s více příkazy otevírají obrovský prostor možností, protože SQL obsahuje všechny nástroje, které potřebujete k psaní procedurálního kódu, od zpracování výjimek až po body uložení (dokonce je to Turing kompletní s okenními funkcemi a běžnými tabulkovými výrazy!). V databázi lze provádět celé pracovní postupy zpracování dat, čímž se minimalizuje vystavení jiným oblastem systému a eliminují se časově náročné zpáteční cesty mezi databází a jinými doménami.
Tolik softwarové architektury obecně je o správě a izolaci složitosti, aby se zabránilo jejímu přelévání přes hranice mezi subsystémy. Pokud nějaký více či méně komplikovaný pracovní postup zahrnuje stahování dat do aplikačního backendu, skriptu nebo úlohy cron, zpracovávání a přidávání do nich a ukládání výsledku – je na čase se zeptat, co si skutečně vyžaduje pustit se mimo databázi.
Jak bylo uvedeno výše, toto je oblast, kde se do popředí dostávají rozdíly mezi příchutěmi RDBMS a dialekty SQL. Funkce nebo procedura vyvinutá pro jednu databázi pravděpodobně nebude běžet v jiné beze změn, ať už jde o náhradu TOP SQL Serveru. za standardní LIMIT klauzule nebo úplné přepracování způsobu uložení dočasného stavu v podnikové migraci Oracle na PostgreSQL. Kanonizace vašich pracovních postupů v SQL vás také zavazuje k vaší aktuální platformě a dialektu důkladněji než téměř jakákoli jiná volba, kterou můžete udělat.
Výpočty v dotazech
Doposud jsme se zabývali používáním funkcí k ukládání a úpravám dat, ať už vázaných na definice tabulek nebo na správu pracovních postupů s více tabulkami. V jistém smyslu je to nejvýkonnější využití, ke kterému je lze použít, ale funkce mají své místo také při získávání dat. Mnoho nástrojů, které již můžete použít ve svých dotazech, je implementováno jako funkce, od standardních vestavěných prvků, jako je count na rozšíření, jako je Postgres' jsonb_build_object , PostGIS' ST_SnapToGrid , a více. Samozřejmě, protože jsou těsněji integrovány se samotnou databází, jsou většinou napsány v jiných jazycích než SQL (např. C v případě PostgreSQL a PostGIS).
Pokud se často přistihnete (nebo si myslíte, že byste se mohli najít), že potřebujete získat data a poté provést nějakou operaci s každým záznamem, než to bude skutečně připraveni, zvažte jejich transformaci na cestě z databáze! Plánujete nějaký počet pracovních dní od data? Generování rozdílu mezi dvěma JSONB pole? V SQL lze provést prakticky jakýkoli výpočet, který závisí pouze na informacích, na které se dotazujete. A co se děje v databázi – pokud je k ní konzistentně přistupováno – je kanonické, pokud jde o vše, co je postaveno na databázi.
Je třeba říci:pokud pracujete s aplikačním backendem, jeho sada nástrojů pro přístup k datům může omezit, kolik kilometrů získáte rozšířením výsledků dotazů o funkce. Většina takových knihoven může spouštět libovolný SQL, ale ty, které generují běžné SQL příkazy založené na modelových třídách, mohou nebo nemusí umožňovat přizpůsobení dotazu SELECT seznamy. Zde mohou být odpovědí generované sloupce nebo pohledy.
Spouštěče a důsledky
Funkce a procedury jsou mezi návrháři databází a uživateli dostatečně sporné, ale věci skutečně vzlétnout pomocí spouště. Spouštěč definuje automatickou akci, obvykle proceduru (SQLite umožňuje pouze jeden příkaz), která má být provedena před, po nebo místo jiné akce.
Iniciační akcí je obecně vložení, aktualizace nebo odstranění tabulky a spouštěcí procedura může být obvykle nastavena tak, aby byla provedena buď pro každý záznam, nebo pro příkaz jako celek. SQL Server také umožňuje spouštěče na aktualizovatelných pohledech, většinou jako způsob, jak vynutit podrobnější bezpečnostní opatření; a to, PostgreSQL a Oracle všechny nabízejí nějakou formu události nebo
Běžné použití spouštěčů s nízkým rizikem je jako extra výkonné omezení zabraňující ukládání neplatných dat. Ve všech hlavních relačních databázích pouze primární a cizí klíče a UNIQUE omezení mohou vyhodnotit informace mimo záznam kandidáta. V definici tabulky není možné deklarovat, že například za měsíc mohou být vytvořeny pouze dvě šarže -- a nejjednodušší řešení databáze a kódu je zranitelné podobným konfliktním stavem jako přístup počet-pak-nastav. lot_number výše. Chcete-li vynutit jakékoli jiné omezení, které zahrnuje celou tabulku nebo jiné tabulky, potřebujete
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Jakmile začnete spouštět lots sám o sobě může být konečnou operací spouštěče iniciované vložením do orders , bez lidského uživatele nebo aplikačního backendu oprávněného zapisovat do lots přímo. Nebo jako items jsou přidány do hodně, spouštěč by tam mohl zvládnout aktualizaci current_quantity a spusťte nějaký další proces, když dosáhne target_quantity .
Spouštěče a funkce mohou běžet na úrovni přístupu jejich definujícího (v PostgreSQL SECURITY DEFINER deklarace vedle LANGUAGE funkce ), což jinak omezeným uživatelům dává možnost spouštět procesy širšího rozsahu – a ověřování a testování těchto procesů je o to důležitější.
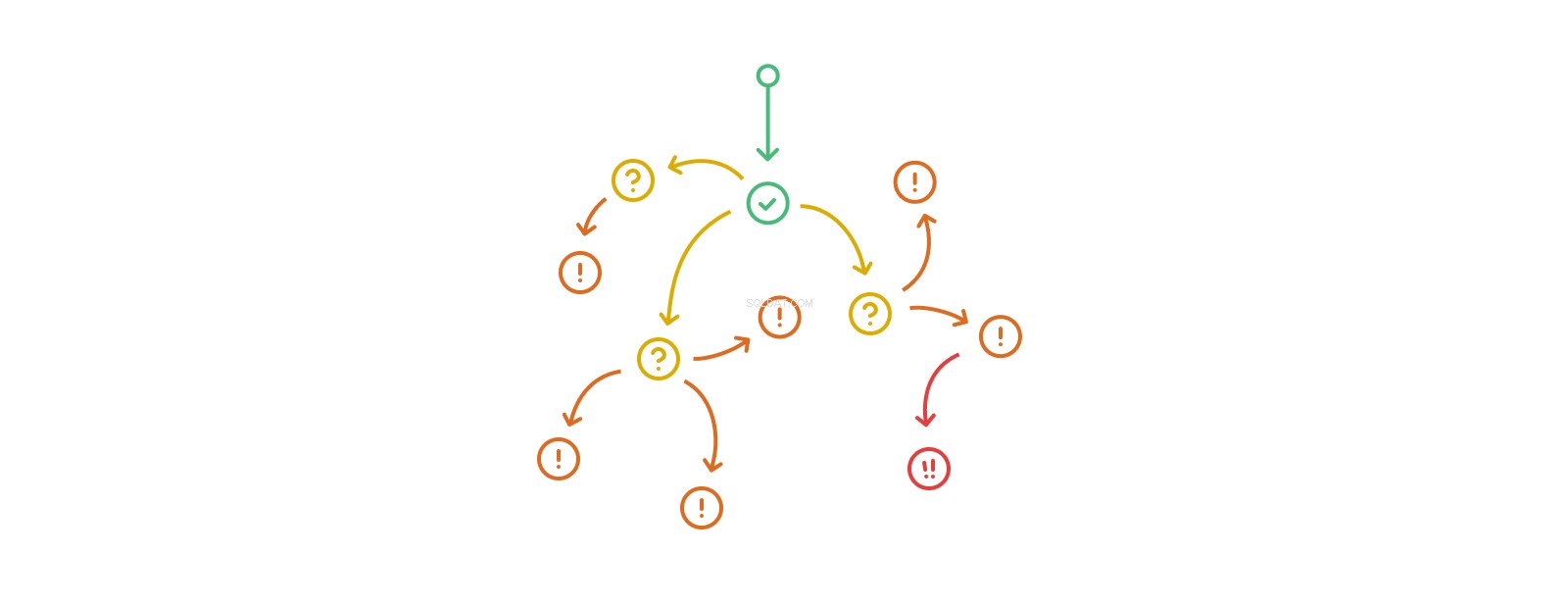
Zásobník volání trigger-action-trigger-action se může libovolně prodloužit, ačkoli skutečná rekurze ve formě vícenásobných úprav stejných tabulek nebo záznamů v jakémkoli takovém toku je na některých platformách nezákonná a obecněji špatný nápad téměř za všech okolností. Spouštěcí hnízdění rychle předčí naši schopnost pochopit jeho rozsah a účinky. Databáze, které intenzivně využívají vnořené spouštěče, se začnou posouvat z říše komplikovaného do říše komplexní, takže je obtížné nebo nemožné analyzovat, ladit a předvídat.
Praktická programovatelnost
Výpočty v databázi nejsou jen rychlejší a stručněji vyjádřené:eliminují nejednoznačnost a nastavují standardy. Výše uvedené příklady poskytují uživatelům bezplatné databáze z toho, že si sami musí vypočítat čísla šarží, nebo z obav z náhodného vytvoření více šarží, než mohou zvládnout. Zejména vývojáři aplikací byli často vycvičeni k tomu, aby považovali databáze za „hloupé úložiště“, které poskytuje pouze strukturu a perzistenci, a mohou se tak ocitnout – nebo ještě hůř, neuvědomovat si, že jsou – nemotorně artikulovat mimo databázi, co by mohli dělat. efektivněji v SQL.
Programovatelnost je neprávem opomíjenou vlastností relačních databází. Existují důvody, proč se mu vyhnout, a další důvody pro omezení jeho použití, ale funkce, procedury a spouštěče jsou mocnými nástroji pro omezení složitosti, kterou váš datový model klade na systémy, ve kterých je zabudován.