Co dělá indexování?
Indexování je způsob, jak dostat neuspořádanou tabulku do pořadí, které maximalizuje efektivitu dotazu při vyhledávání.
Když je tabulka neindexovaná, pořadí řádků nebude pravděpodobně v dotazu rozpoznatelné jako optimalizované, a váš dotaz proto bude muset prohledávat řádky lineárně. Jinými slovy, dotazy budou muset prohledávat každý řádek, aby našly řádky odpovídající podmínkám. Jak si dokážete představit, může to trvat dlouho. Prohlížet každý jednotlivý řádek není příliš efektivní.
Například tabulka níže představuje tabulku ve fiktivním zdroji dat, který je zcela neuspořádaný.
| id_společnosti | jednotka | jednotkové_náklady |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Pokud bychom spustili následující dotaz:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Databáze by musela prohledávat všech 17 řádků v pořadí, v jakém se objevují v tabulce, odshora dolů, jeden po druhém. Chcete-li tedy vyhledat všechny potenciální instance company_id číslo 18, databáze musí prohledat celou tabulku pro všechny výskyty 18 v company_id sloupec.
S rostoucí velikostí stolu to bude jen více a více časově náročné. S rostoucí propracovaností dat se může nakonec stát to, že se tabulka s jednou miliardou řádků spojí s další tabulkou s miliardou řádků; dotaz nyní musí prohledávat dvojnásobné množství řádků, které stojí dvakrát tolik času.
Můžete vidět, jak se to stává problematické v našem světě, který je stále přesycený daty. Velikost tabulek se zvětšuje a prohledávání se prodlužuje doba provádění.
Dotazování na neindexovanou tabulku, pokud je prezentována vizuálně, by vypadalo takto:
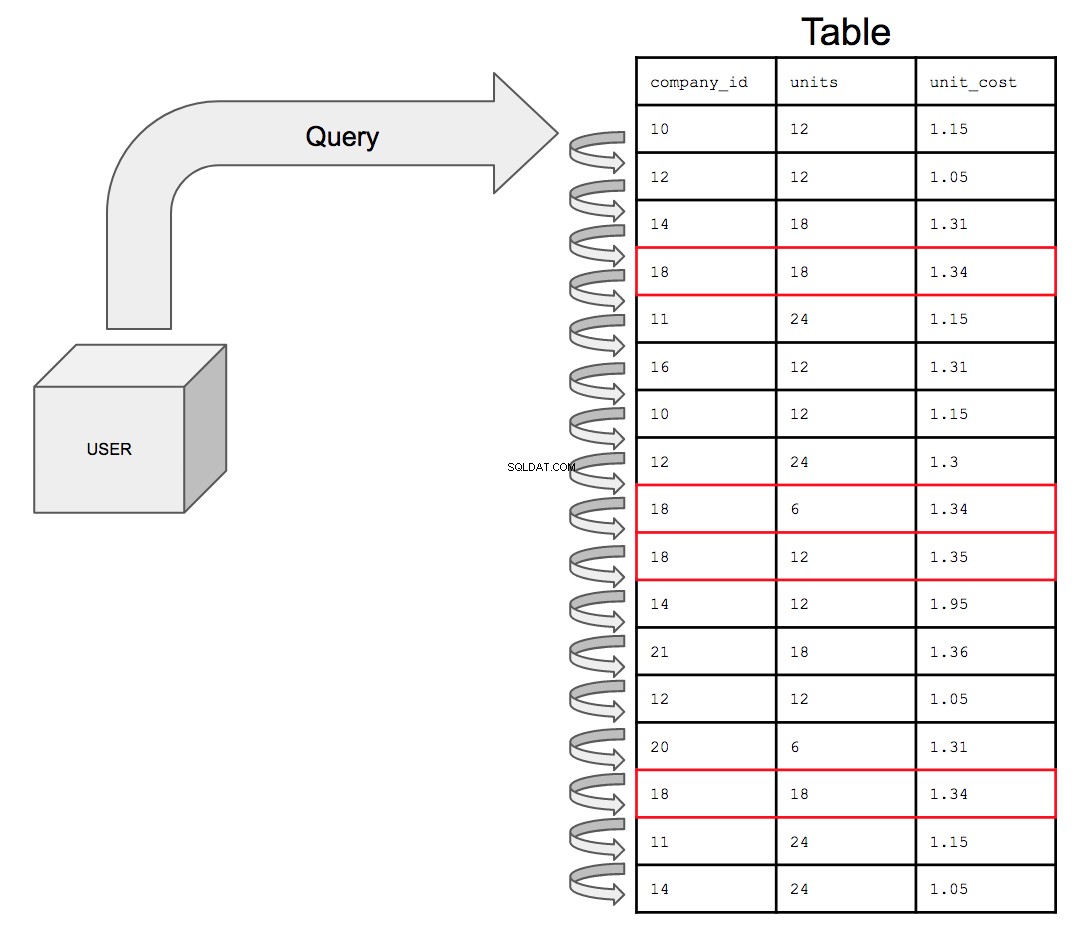
Indexování spočívá v tom, že nastaví sloupec, ve kterém jsou podmínky vyhledávání, v seřazeném pořadí, aby pomohl optimalizovat výkon dotazů.
S indexem na company_id tabulka by v podstatě „vypadala“ takto:
| id_společnosti | jednotka | jednotkové_náklady |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Nyní může databáze hledat company_id číslo 18 a vraťte všechny požadované sloupce pro daný řádek a přejděte na další řádek. Pokud je company_id na dalším řádku číslo je také 18, pak vrátí všechny sloupce požadované v dotazu. Pokud je company_id na dalším řádku je 20, dotaz ví, že má zastavit vyhledávání a dotaz se dokončí.
Jak funguje indexování?
Ve skutečnosti se databázová tabulka nezmění pokaždé, když se změní podmínky dotazu, aby se optimalizoval výkon dotazu:to by bylo nerealistické. Ve skutečnosti se stane, že index způsobí, že databáze vytvoří datovou strukturu. Typ datové struktury je velmi pravděpodobně B-Strom. Zatímco výhod B-Stromu je mnoho, hlavní výhodou pro naše účely je, že je tříditelný. Když je datová struktura setříděna v pořadí, naše vyhledávání je efektivnější ze zřejmých důvodů, na které jsme poukázali výše.
Když index vytváří datovou strukturu na konkrétním sloupci, je důležité si uvědomit, že v datové struktuře není uložen žádný jiný sloupec. Naše datová struktura pro tabulku výše bude obsahovat pouze company_id čísla. Jednotky a unit_cost nebudou uloženy v datové struktuře.
Jak databáze ví, jaká další pole v tabulce má vrátit?
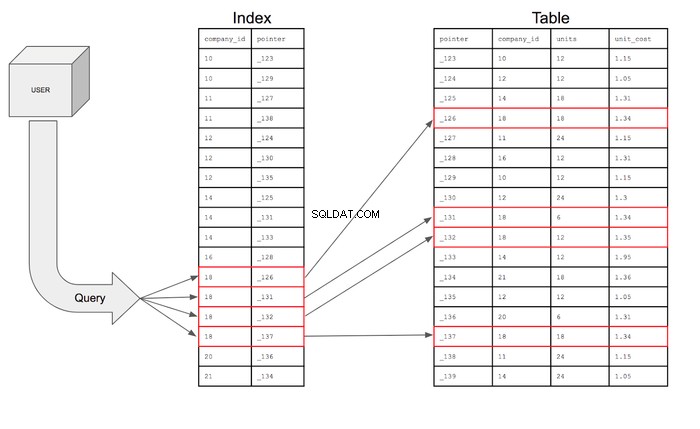
Databázové indexy budou také ukládat ukazatele, které jsou jednoduše referenčními informacemi pro umístění doplňkových informací v paměti. Index v zásadě obsahuje company_id a domovskou adresu konkrétního řádku na paměťovém disku. Index bude ve skutečnosti vypadat takto:
| id_společnosti | ukazatel |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
S tímto indexem může dotaz hledat pouze řádky v company_id sloupec, který má 18 a poté pomocí ukazatele můžete přejít do tabulky a najít konkrétní řádek, kde tento ukazatel žije. Dotaz pak může přejít do tabulky a načíst pole pro sloupce požadované pro řádky, které splňují podmínky.
Pokud by bylo vyhledávání prezentováno vizuálně, vypadalo by takto:
Rekapitulace
- Indexování přidává datovou strukturu se sloupci pro podmínky vyhledávání a ukazatel
- Ukazatel je adresa na paměťovém disku řádku se zbytkem informací
- Datová struktura indexu je tříděna za účelem optimalizace efektivity dotazů
- Dotaz hledá konkrétní řádek v indexu; index odkazuje na ukazatel, který najde zbytek informací.
- Index snižuje počet řádků, které musí dotaz prohledat, ze 17 na 4.