Databáze, které slouží obchodním aplikacím, by měly často podporovat dočasná data. Předpokládejme například, že smlouva s dodavatelem je platná pouze po omezenou dobu. Může být platný od určitého časového bodu dále, nebo může být platný pro určitý časový interval – od počátečního časového bodu do konečného časového bodu. Navíc mnohokrát potřebujete auditovat všechny změny v jedné nebo více tabulkách. Možná budete muset být schopni zobrazit stav v určitém časovém okamžiku nebo všechny změny provedené v tabulce v určitém časovém období. Z hlediska integrity dat možná budete muset implementovat mnoho dalších specifických časově omezených omezení.
Představujeme dočasná data
V tabulce s časovou podporou záhlaví představuje predikát s alespoň jednorázovým parametrem, který představuje interval když je platný zbytek predikátu – úplný predikát je tedy predikát s časovým razítkem. Řádky představují návrhy s časovým razítkem a platné časové období řádku je obvykle vyjádřeno dvěma atributy:from a komu nebo začněte a konec .
Typy časových tabulek
Možná jste si všimli během úvodní části, že existují dva druhy časových problémů. První z nich je doba platnosti návrhu – ve kterém období byl výrok, který představuje řádek s časovým razítkem v tabulce, skutečně pravdivý. Například smlouva s dodavatelem byla platná pouze od časového bodu 1 do časového bodu 2. Tento druh doby platnosti je smysluplný pro lidi, smysluplný pro obchod. Doba platnosti se také nazývá doba aplikace nebo lidský čas . Pro stejnou entitu můžeme mít více platných období. Například výše uvedená smlouva, která byla platná od časového bodu 1 do časového bodu 2, může být platná také od časového bodu 7 do časového bodu 9.
Druhým dočasným problémem je čas transakce . Řádek pro smlouvu zmíněnou výše byl vložen v časovém bodě 1 a byla to jediná verze pravdy, kterou databáze znala, dokud ji někdo nezměnil, nebo dokonce do konce času. Když je řádek aktualizován v časovém bodě 2, byl původní řádek znám jako pravdivý pro databázi od časového bodu 1 do časového bodu 2. Vloží se nový řádek pro stejný návrh s časem platným pro databázi od časového bodu 2 do konec času. Čas transakce je také známý jako systémový čas nebo čas databáze .
Samozřejmě můžete také implementovat tabulky verzí pro aplikace i systémy. Takové tabulky se nazývají bitemporální tabulky.
V SQL Server 2016 získáte podporu pro systémový čas ihned po vybalení pomocí dočasných tabulek verze systému . Pokud potřebujete implementovat aplikační čas, musíte vyvinout řešení sami.
Operátoři Allenových intervalů
Teorie časových dat v relačním modelu se začala vyvíjet před více než třiceti lety. Představím několik užitečných booleovských operátorů a pár operátorů, které pracují na intervalech a vracejí interval. Tyto operátory jsou známé jako Allenovy operátory, pojmenované po J. F. Allenovi, který řadu z nich definoval ve výzkumném dokumentu z roku 1983 o časových intervalech. Všechny jsou stále přijímány jako platné a potřebné. Systém správy databází by vám mohl pomoci vypořádat se s dobou aplikací implementací těchto operátorů hned po vybalení.
Dovolte mi nejprve představit notaci, kterou budu používat. Budu pracovat ve dvou intervalech, označených i1 a i2 . Počáteční časový bod prvního intervalu je b1 a konec je e1 ; počáteční časový bod druhého intervalu je b2 a konec je e2 . Allenovy Booleovské operátory jsou definovány v následující tabulce.
[table id=2 /]
Kromě booleovských operátorů existují Allenovy tři operátory, které přijímají intervaly jako vstupní parametry a vracejí interval. Tyto operátory tvoří jednoduchou intervalovou algebru . Všimněte si, že tyto operátory mají stejný název jako relační operátory, které pravděpodobně již znáte:Union, Intersect a Minus. Nechovají se však přesně jako jejich vztahoví protějšky. Obecně platí, že při použití kteréhokoli ze tří intervalových operátorů, pokud by operace vedla k prázdné množině časových bodů nebo k množině, kterou nelze popsat jedním intervalem, operátor by měl vrátit hodnotu NULL. Spojení dvou intervalů má smysl pouze tehdy, pokud se intervaly setkávají nebo překrývají. Průsečík má smysl pouze v případě, že se intervaly překrývají. Operátor Minus interval má smysl pouze v některých případech. Například (3:10) Minus (5:7) vrátí hodnotu NULL, protože výsledek nelze popsat jedním intervalem. Následující tabulka shrnuje definice operátorů intervalové algebry.
[id tabulky=3 /]
Problém výkonu překrývajících se dotazů Jedním z nejsložitějších operátorů k implementaci jsou překrývání operátor. Dotazy, které potřebují najít překrývající se intervaly, není snadné optimalizovat. Takové dotazy jsou však u časových tabulek poměrně časté. V tomto a dvou následujících článcích vám ukážu několik způsobů, jak takové dotazy optimalizovat. Ale než představím řešení, dovolte mi představit problém.
Abych vysvětlil problém, potřebuji nějaká data. Následující kód ukazuje příklad, jak vytvořit tabulku s intervaly platnosti vyjádřenými pomocí b a e sloupce, kde začátek a konec intervalu jsou reprezentovány jako celá čísla. Tabulka je naplněna ukázkovými daty z tabulky WideWorldImporters.Sales.OrderLines. Upozorňujeme, že existuje několik verzí WideWorldImporters databáze, takže můžete získat mírně odlišné výsledky. Použil jsem záložní soubor WideWorldImporters-Standard.bak z https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 k obnovení této ukázkové databáze na mé instanci SQL Server .
Vytvoření ukázkových dat
Vytvořil jsem ukázkovou tabulku dbo.Intervals v tempd databázi s následujícím kódem.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Všimněte si také indexů vytvořené. Dva indexy jsou optimální pro vyhledávání na začátku intervalu nebo na konci intervalu. Minimální začátek a maximální konec všech intervalů můžete zkontrolovat pomocí následujícího kódu.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Ve výsledcích můžete vidět, že minimální čas začátku je 1 a maximální čas ukončení je 1155.
Dát datům kontext
Můžete si všimnout, že představuji začátek a konec časových bodů jako celá čísla. Nyní potřebuji dát intervalům nějaký časový kontext. V tomto případě představuje jeden časový bod den . Následující kód vytvoří vyhledávací tabulku podle data a osídluje ji. Upozorňujeme, že počáteční datum je 1. července 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Nyní můžete dvakrát připojit tabulku dbo.Intervals k tabulce dbo.DateNums, abyste dali kontext celým číslům, která představují začátek a konec intervalů.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Představení problému s výkonem
Problém s dočasnými dotazy spočívá v tom, že při čtení z tabulky může SQL Server použít pouze jeden index a úspěšně eliminovat řádky, které nejsou kandidáty na výsledek, pouze z jedné strany a poté prohledá zbytek dat. Například potřebujete v tabulce najít všechny intervaly, které se s daným intervalem překrývají. Pamatujte, že dva intervaly se překrývají, když začátek prvního je nižší nebo roven konci druhého a začátek druhého je menší nebo roven konci prvního, nebo matematicky, když (b1 ≤ e2) AND (b2 ≤ e1).
Následující dotaz hledal všechny intervaly, které se překrývají s intervalem (10, 30). Všimněte si, že druhá podmínka (b2 ≤ e1) je otočena na (e1 ≥ b2) pro jednodušší čtení (začátek a konec intervalů z tabulky je vždy na levé straně podmínky). Daný nebo hledaný interval je na začátku časové osy pro všechny intervaly v tabulce.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Dotaz použil 36 logických čtení. Pokud zkontrolujete plán provádění, uvidíte, že dotaz použil hledání indexu v indexu idx_b s predikátem hledání [tempdb].[dbo].[Intervaly].b <=Skalární operátor((30)) a poté prohledejte řádky a vyberte výsledné řádky pomocí zbytkového predikátu [tempdb].[dbo].[Intervaly].[e]>=(10). Protože hledaný interval je na začátku časové osy, predikát vyhledávání úspěšně eliminoval většinu řádků; pouze několik intervalů v tabulce má počáteční bod nižší nebo rovný 30.
Podobně efektivní dotaz byste dostali, pokud by hledaný interval byl na konci časové osy, akorát by SQL Server pro vyhledávání použil index idx_e. Co se však stane, pokud je hledaný interval uprostřed časové osy, jak ukazuje následující dotaz?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Tentokrát dotaz použil 111 logických čtení. S větší tabulkou by byl rozdíl s prvním dotazem ještě větší. Pokud zkontrolujete plán provádění, můžete zjistit, že SQL Server použil index idx_e s [tempdb].[dbo].[Intervaly].e>=Scalar Operator((570)) seek predikát a [tempdb].[ dbo].[Intervaly].[b]<=(590) reziduální predikát. Predikát hledání vyloučí přibližně polovinu řádků na jedné straně, zatímco polovina řádků na druhé straně je naskenována a výsledné řádky se extrahují se zbytkovým predikátem.
Vylepšené řešení T-SQL
Existuje řešení, které by použilo tento index pro eliminaci řádků z obou stran hledaného intervalu pomocí jediného indexu. Následující obrázek ukazuje tuto logiku.
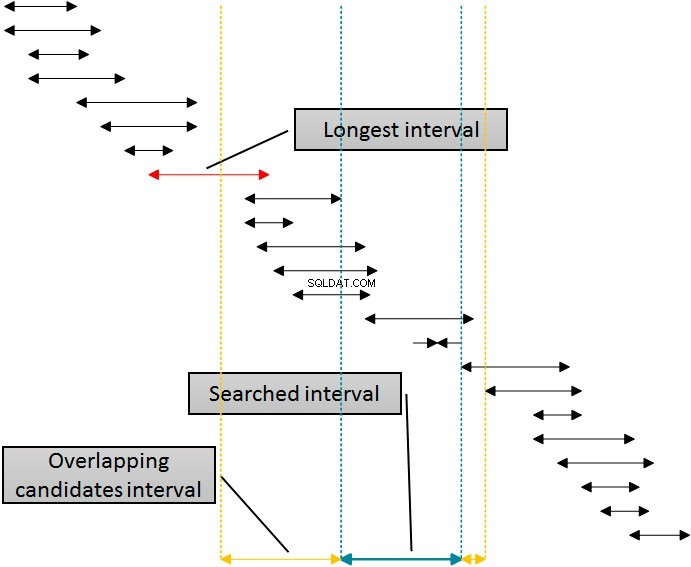
Intervaly na obrázku jsou seřazeny podle spodní hranice, která představuje využití indexu idx_b serverem SQL. Odstranění intervalů z pravé strany daného (hledaného) intervalu je jednoduché:stačí odstranit všechny intervaly, jejichž začátek je alespoň o jednu jednotku větší (více vpravo) než konec daného intervalu. Tuto hranici můžete vidět na obrázku označeném tečkovanou čarou zcela vpravo. Vyřazení zleva je však složitější. Abych mohl použít stejný index, index idx_b pro eliminaci zleva, musím použít začátek intervalů v tabulce v klauzuli WHERE dotazu. Musím jít na levou stranu pryč od začátku daného (hledaného) intervalu alespoň na délku nejdelšího intervalu v tabulce, který je na obrázku označen popiskem. Intervaly, které začínají před levou žlutou čarou, se nemohou překrývat s daným (modrým) intervalem.
Protože již vím, že délka nejdelšího intervalu je 20, mohu napsat rozšířený dotaz celkem jednoduchým způsobem.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Tento dotaz načte stejné řádky jako předchozí s pouze 20 logickými čteními. Pokud zkontrolujete plán provádění, uvidíte, že byl použit idx_b s predikátem hledání Klíče hledání[1]:Start:[tempdb].[dbo].[Intervaly].b>=Skalární operátor((550)) , End:[tempdb].[dbo].[Intervaly].b <=Skalární operátor((590)), který úspěšně odstranil řádky z obou stran časové osy, a poté zbytkový predikát [tempdb].[dbo]. [Intervaly].[e]>=(570) AND [tempdb].[dbo].[Intervaly].[e]<=(610) bylo použito k výběru řádků z velmi omezeného částečného skenování.
Obrázek by se samozřejmě dal otočit, aby pokryl případy, kdy by byl užitečnější index idx_e. S tímto indexem je eliminace zleva jednoduchá – vyřaďte všechny intervaly, které končí alespoň jednu jednotku před začátkem daného intervalu. Tentokrát je eliminace zprava složitější – konec intervalů v tabulce nemůže být více vpravo než konec daného intervalu plus maximální délka všech intervalů v tabulce.
Upozorňujeme, že tento výkon je důsledkem konkrétních údajů v tabulce. Maximální délka intervalu je 20. SQL Server tak může velmi efektivně eliminovat intervaly z obou stran. Pokud by však v tabulce byl pouze jeden dlouhý interval, kód by se stal mnohem méně efektivním, protože SQL Server by nebyl schopen odstranit mnoho řádků z jedné strany, ať už zleva nebo zprava, v závislosti na tom, který index by použil. . Každopádně v reálném životě se délka intervalu mnohonásobně nemění, takže tato optimalizační technika může být velmi užitečná, zejména proto, že je jednoduchá.
Závěr
Upozorňujeme, že toto je pouze jedno možné řešení. V článku Interval Queries in SQL Server od Itzika Ben-Gana (https://sqlmag.com/t-sql/) můžete najít řešení, které je složitější, ale poskytuje předvídatelný výkon bez ohledu na délku nejdelšího intervalu sql-server-interval-queries). Velmi se mi však líbí vylepšené T-SQL řešení, které jsem představil v tomto článku. Řešení je velmi jednoduché; vše, co musíte udělat, je přidat dva predikáty do klauzule WHERE vašich překrývajících se dotazů. Tím však možnosti nekončí. Zůstaňte naladěni, v následujících dvou článcích vám ukážu další řešení, takže v sadě nástrojů pro optimalizaci budete mít bohatou sadu možností.
Užitečný nástroj:
dbForge Query Builder pro SQL Server – umožňuje uživatelům rychle a snadno vytvářet složité SQL dotazy prostřednictvím intuitivního vizuálního rozhraní bez ručního psaní kódu.