Právě odkliduji svůj dům (v létě je příliš pozdě na to, abych to zkusil vydávat za jarní úklid). Znáte to, uklízet skříně, procházet dětské hračky a organizovat sklep. Je to bolestivý proces. Když jsme se před 10 lety nastěhovali do našeho domu, měli jsme TOLIK prostoru. Teď mám pocit, že je všude spousta věcí a je těžší najít to, co opravdu hledám, a úklid a uspořádání trvá stále déle.
Zní to jako nějaká databáze, kterou spravujete?
Mnoho klientů, se kterými jsem pracoval, řeší čištění dat jako dodatečný nápad. V době realizace chce každý vše zachránit. "Nikdy nevíme, kdy to budeme potřebovat." Po roce nebo dvou si někdo uvědomí, že v databázi je spousta věcí navíc, ale teď se lidé bojí se toho zbavit. "Musíme se poradit s právním oddělením, jestli to můžeme smazat." Ale nikdo to nekontroluje u Legal, nebo pokud někdo ano, Legal se vrátí k majitelům firem, aby se zeptal, co si ponechat, a pak se projekt zastaví. "Nemůžeme dojít ke konsenzu o tom, co lze smazat." Projekt je zapomenut a pak dva nebo čtyři roky po cestě je databáze najednou terabajt, obtížně se spravuje a lidé obviňují všechny problémy s výkonem na velikost databáze. Slyšíte slova „rozdělení na oddíly“ a „archivační databáze“ a někdy stačí smazat spoustu dat, což má své vlastní problémy.
V ideálním případě byste se měli o své strategii čištění rozhodnout před implementací nebo během prvních šesti až dvanácti měsíců uvedení do provozu. Ale protože jsme tuto fázi již za sebou, podívejme se, jaký dopad mohou mít tato další data.
Metodika testu
Abych připravil scénu, vzal jsem kopii databáze kreditů a obnovil ji do své instance SQL Server 2012. Vypustil jsem tři existující indexy bez klastrů a přidal dva vlastní:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Poté jsem zvýšil počet řádků v tabulce na 14,4 milionů opakovaným vložením původní sady řádků, přičemž jsem mírně upravil data:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Nakonec jsem nastavil testovací svazek k provedení série příkazů proti databázi čtyřikrát, každý z nich. Prohlášení jsou níže:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Před každým příkazem, který jsem provedl
DBCC DROPCLEANBUFFERS; GO
k vymazání fondu vyrovnávacích pamětí. Zjevně to není něco, co by se mělo provádět proti produkčnímu prostředí. Udělal jsem to zde, abych poskytl konzistentní výchozí bod pro každý test.
Po každém provedení jsem zvětšil velikost tabulky dbo.charge vložením 14,4 milionů řádků, se kterými jsem začal, ale zvýšil jsem charge_dt o jeden rok pro každé provedení. Například:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Po přidání 14,4 milionů řádků jsem znovu spustil testovací svazek. Opakoval jsem to šestkrát, v podstatě jsem přidal šest „roků“ dat. Tabulka dbo.charge začala daty z roku 1999 a po opakovaných vloženích obsahovala data až do roku 2005.
Výsledky
Výsledky exekucí jsou k vidění zde:
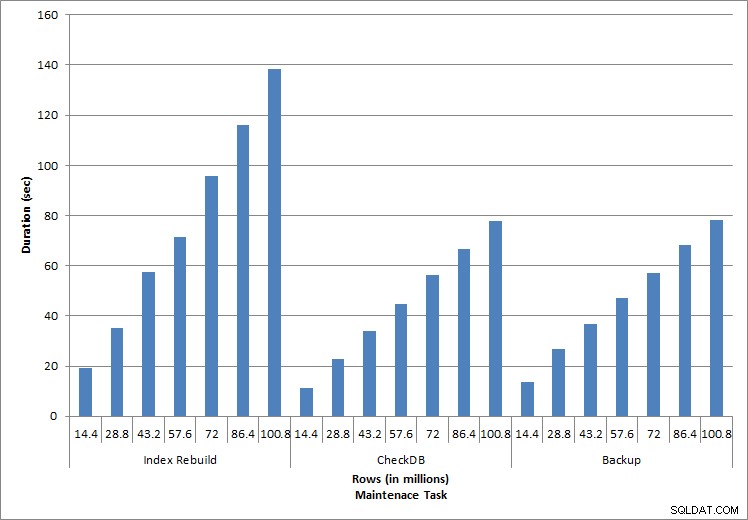
Doba trvání úkolů údržby
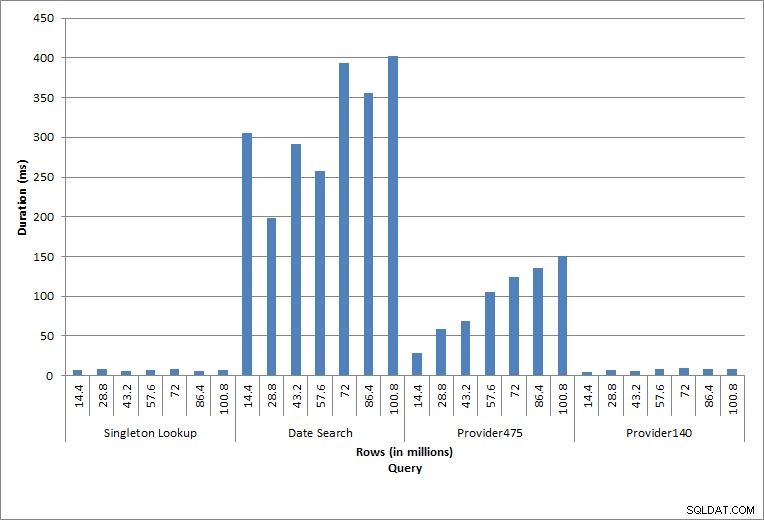
Doba trvání dotazů
Jednotlivé provedené příkazy odrážejí typickou činnost databáze. Přestavby indexů, kontroly integrity a zálohy jsou součástí pravidelné údržby databáze. Dotazy na tabulku poplatků představují jednoduché vyhledávání a také tři varianty skenování rozsahu specifické pro data v tabulce.
Obnovy indexu, CHECKDB a zálohy
Jak se očekávalo u úloh údržby, doba trvání a hodnoty IO se zvýšily, jak bylo do databáze přidáno více řádků. Velikost databáze se zvýšila 10krát, a i když se doby trvání nezvyšovaly stejným tempem, byl pozorován konzistentní nárůst. Dokončení každé úlohy údržby zpočátku trvalo méně než 20 sekund, ale jak byly přidány další řádky, doba trvání úloh se zvýšila na téměř 1 minutu a 20 sekund u 100 milionů řádků (a na více než 2 minuty u opětovného sestavení indexu). To odráží další čas, který SQL Server potřebuje k dokončení úlohy kvůli dalším datům.
Singleton vyhledávání
Dotaz na dbo.charge pro konkrétní charge_no vždy vytvořil jeden řádek – a vytvořil by jeden řádek bez ohledu na použitou hodnotu, protože charge_no je jedinečná identita. Pro toto vyhledávání existuje minimální variace. Jak jsou řádky do tabulky průběžně přidávány, index se může zvětšovat do hloubky o jednu nebo dvě úrovně (více, jak se tabulka rozrůstá), a proto se přidá několik IO, ale toto je jednoduché vyhledávání s velmi malým počtem IO.
Prohledávání rozsahu
Dotaz na časové období (charge_dt) byl po každém vložení upraven tak, aby vyhledával data posledního roku za červenec (např. '2005-07-01' až '2005-07-01' pro poslední sadu testů), ale vrátil pokaždé něco málo přes 1,2 milionu řádků. Ve scénáři reálného světa bychom neočekávali, že bude vrácen stejný počet řádků za stejný měsíc, rok za rokem, ani bychom neočekávali, že by se každý měsíc v roce vrátil stejný počet řádků. Ale počty řádků by mohly zůstat ve stejném rozmezí mezi měsíci, s mírným nárůstem v průběhu času. Trvání tohoto dotazu kolísá, ale kontrola IO dat zachycených z sys.dm_io_virtual_file_stats ukazuje konzistenci v počtu přečtení.
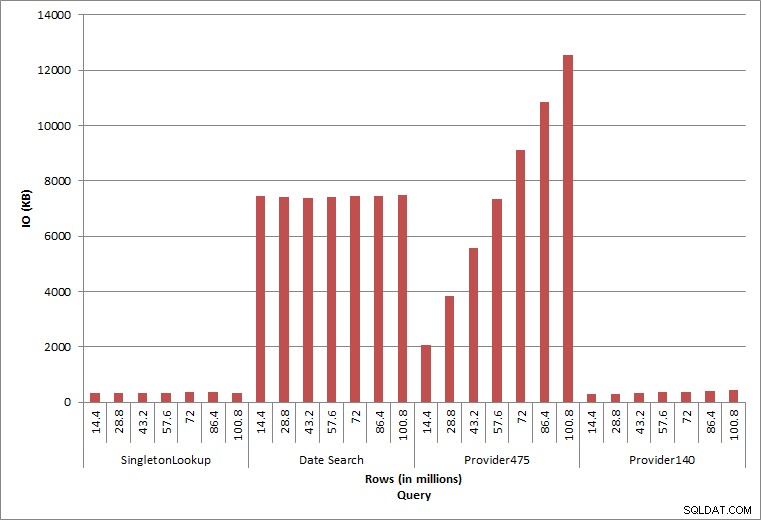
Dotaz IO
Poslední dva dotazy pro dvě různé hodnoty provider_no ukazují skutečný efekt uchovávání dat. V původní tabulce dbo.charge měl provider_no 475 více než 126 000 řádků a poskytovatel_no 140 více než 1700 řádků. Pro každých 14,4 milionů přidaných řádků byl přidán přibližně stejný počet řádků pro každý provider_no. V produkčním prostředí není tento typ distribuce dat neobvyklý a dotazy na tato data mohou fungovat dobře v prvních letech řešení, ale mohou se časem zhoršit, když budou přidány další řádky. Doba trvání dotazu se prodlužuje pětinásobně (z 31 ms na 153 ms) mezi počátečním a konečným spuštěním pro provider_no 475. I když se tento dopad nemusí zdát významný, všimněte si paralelního nárůstu IO (výše). Pokud se jednalo o dotaz, který se spouštěl s vysokou frekvencí, a/nebo se vyskytly podobné dotazy, které se spouštěly s pravidelnou frekvencí, další zatížení se může sčítat a ovlivnit celkové využití zdrojů. Dále zvažte dopad, když pracujete s tabulkami, které mají miliardy řádků a které se používají v dotazech se složitými spojeními, a dopad na vaše běžné – a extrémně kritické – úlohy údržby. Nakonec vezměte v úvahu dobu obnovitelnosti. Váš plán obnovy po havárii by měl být založen na dobách obnovy a jak roste velikost databáze, obnova celé databáze bude trvat déle. Pokud své obnovy pravidelně netestujete a nenačasujete, obnova po havárii může trvat déle, než jste si mysleli.
Shrnutí
Zde uvedené příklady jsou jednoduchými ilustracemi toho, co se může stát, když není během implementace databáze určena strategie archivace dat, a existuje mnoho dalších scénářů, které je třeba prozkoumat a otestovat. Stará data, ke kterým se přistupuje jen zřídka, pokud vůbec, mají větší dopad než jen na místo na disku. Může ovlivnit výkon dotazu a dobu trvání úkolů údržby. Jako DBA spravující více databází na instanci může jedna databáze, která obsahuje historická data, ovlivnit výkon a úkoly údržby jiných databází. Kromě toho, pokud se sestavy provádějí na základě historických dat, může to způsobit zmatek v již tak vytíženém prostředí OLTP.
Od začátku je důležité, aby byla určena životnost dat v databázi a byl zaveden akční plán. U některých řešení je nutné uchovávat všechna data navždy. V tomto případě použijte strategie, které udrží velikost databáze zvládnutelnou, například:pravidelně archivujte data do samostatné tabulky nebo samostatné databáze. V případě, že data není třeba uchovávat roky a roky, implementujte strategii čištění, která data pravidelně odstraňuje. Tímto způsobem můžete vyhodit hračky, se kterými se již nehraje, oblečení, které se již nehodí, a náhodné haraburdí, které prostě nepoužíváte, každé tři měsíce… spíše než jednou za 10 let.