 Jakmile jsem vyrůstal, miloval jsem hry, které testovaly paměť a schopnosti přiřazování vzorů. Několik mých přátel mělo Simona, zatímco já měl sraz jménem Einstein. Jiní měli Atari Touch Me, o kterém jsem už tehdy věděl, že je to sporné rozhodnutí o názvu. V dnešní době pro mě shoda vzorů znamená něco mnohem jiného a může být drahou součástí každodenních databázových dotazů.
Jakmile jsem vyrůstal, miloval jsem hry, které testovaly paměť a schopnosti přiřazování vzorů. Několik mých přátel mělo Simona, zatímco já měl sraz jménem Einstein. Jiní měli Atari Touch Me, o kterém jsem už tehdy věděl, že je to sporné rozhodnutí o názvu. V dnešní době pro mě shoda vzorů znamená něco mnohem jiného a může být drahou součástí každodenních databázových dotazů.
Nedávno jsem narazil na několik komentářů na Stack Overflow, kde uživatel uvedl, jako by fakt, že CHARINDEX funguje lépe než LEFT nebo LIKE . V jednom případě dotyčná osoba citovala článek Davida Lozinského „SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX.“ Ano, článek ukazuje, že ve vykonstruovaném příkladu CHARINDEX předvedl nejlépe. Protože jsem však vždy skeptický k takovým paušálním prohlášením a nenapadl mě logický důvod, proč by funkce jednoho řetězce vždy dosahují lepších výsledků než ostatní, přičemž všechny ostatní jsou stejné , provedl jsem jeho testy. Jistě, měl jsem na svém počítači opakovaně odlišné výsledky (kliknutím zvětšíte):
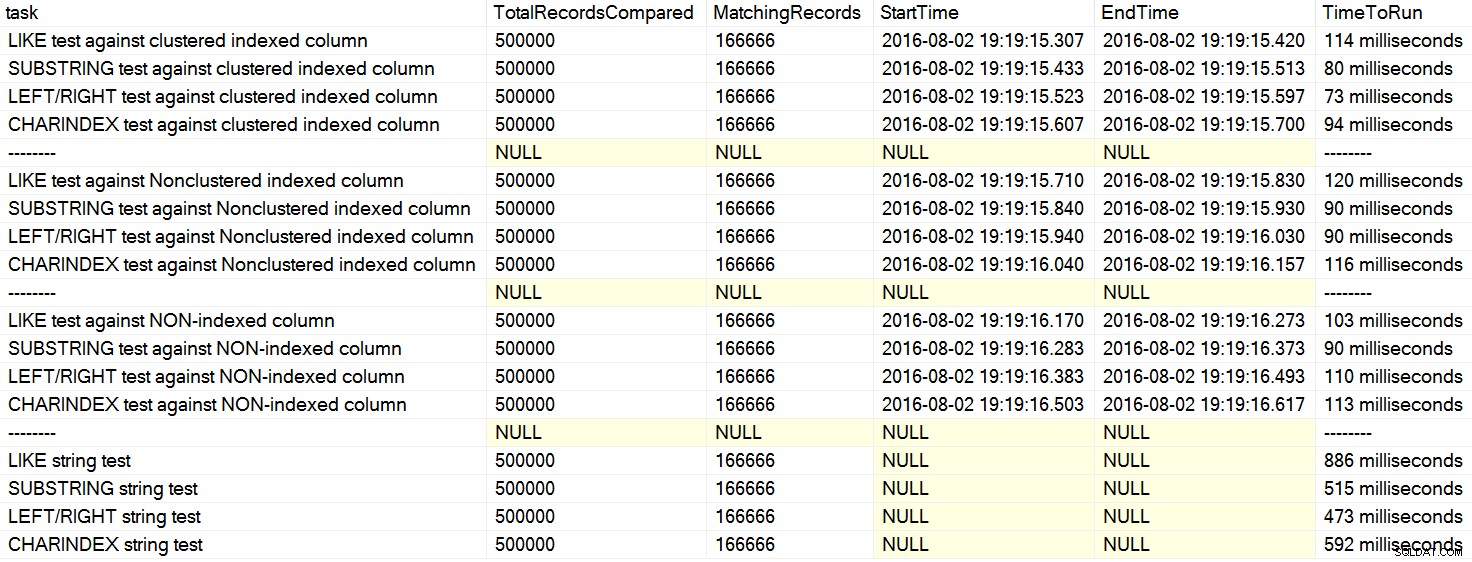 Na mém počítači byl CHARINDEX pomalejší než LEFT/RIGHT/SUBSTRING.
Na mém počítači byl CHARINDEX pomalejší než LEFT/RIGHT/SUBSTRING.
Davidovy testy v podstatě porovnávaly tyto struktury dotazů – hledaly vzor řetězce buď na začátku nebo na konci hodnoty sloupce – z hlediska nezpracované doby trvání:
WHERE Sloupec LIKE @vzor + '%' OR Sloupec LIKE '%' + @vzor; WHERE PODŘETĚZEC(Sloupec, 1, DÉLKA(@vzor)) =@vzor NEBO PODŘETĚZEC(Sloupec, DÉLKA(Sloupec) - DÉLKA(@vzor) + 1, DÉLKA(@vzor)) =@vzor; WHERE LEFT(Sloupec, DÉLKA(@vzor)) =@vzor NEBO VPRAVO(Sloupec, DÉLKA(@vzor)) =@vzor; WHERE CHARINDEX(@vzor, PODŘETĚZEC(sloupec, 1, DÉLKA(@vzor)), 0)> 0 NEBO CHARINDEX(@vzor, SUBSTRING(sloupec, DÉLKA(sloupec) - DÉLKA(@vzor) + 1, DÉLKA(@vzor )), 0)> 0;
Při pouhém pohledu na tyto klauzule můžete vidět, proč CHARINDEX může být méně efektivní – provádí několik dalších funkčních volání, která ostatní přístupy nemusí provádět. Proč tento přístup fungoval nejlépe na Davidově stroji, nejsem si jistý; možná spustil kód přesně tak, jak byl zveřejněn, a ve skutečnosti mezi testy nevypouštěl vyrovnávací paměti, takže poslední testy těžily z dat uložených v mezipaměti.
Teoreticky CHARINDEX mohl být vyjádřen jednodušeji, např.:
WHERE CHARINDEX(@vzor, Sloupec) =1 NEBO CHARINDEX(@vzor, Sloupec) =DÉLKA(Sloupec) - LEN(@vzor) + 1;
(Ale toto ve skutečnosti fungovalo ještě hůře v mých příležitostných testech.)
A proč jsou to dokonce OR podmínky, nejsem si jistý. Ve skutečnosti většinu času provádíte jeden ze dvou typů vyhledávání vzorů:začíná nebo obsahuje (je mnohem méně obvyklé hledat končí ). A ve většině těchto případů má uživatel tendenci předem uvést, zda chce začíná nebo obsahuje , alespoň v každé aplikaci, se kterou jsem se ve své kariéře podílel.
Je rozumné je oddělit jako samostatné typy dotazů namísto použití NEBO podmíněné, protože začíná na může používat index (pokud existuje dostatečně vhodný pro hledání nebo je tenčí než seskupený index), zatímco končí na nelze (a NEBO podmínky mají tendenci házet klíče na optimalizátor obecně). Pokud mohu věřit LIKE používat index, když je to možné, a fungovat stejně dobře nebo lépe než ostatní výše uvedená řešení ve většině nebo ve všech případech, pak mohu tuto logiku velmi zjednodušit. Uložená procedura může mít dva parametry – hledaný vzor a typ vyhledávání (obecně existují čtyři typy shody řetězců – začíná, končí, obsahuje nebo přesná shoda).
CREATE PROCEDURE dbo.Search @pattern nvarchar(100), @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains' – poslední dva jsou podporovány, ale nebudou testovány hereASBEGIN SET NOCOUNT ON; SELECT ... WHERE Sloupec LIKE -- pokud obsahuje nebo končí na, je třeba uvést na začátku zástupný znak CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- if obsahuje nebo začíná s, potřebuje koncový zástupný znak CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO
To zpracuje každý potenciální případ bez použití dynamického SQL; OPTION (RECOMPILE) je tam proto, že byste nechtěli, aby byl plán optimalizovaný pro „končí na“ (který bude téměř jistě nutné skenovat) znovu použit pro dotaz „začíná na“ nebo naopak; také zajistí, že odhady jsou správné („začíná na S“ má pravděpodobně výrazně odlišnou mohutnost než „začíná na QX“). I když máte scénář, kdy uživatelé v 99 % případů volí jeden typ vyhledávání, můžete zde místo rekompilace použít dynamické SQL, ale v takovém případě byste byli stále zranitelní vůči sniffování parametrů. V mnoha dotazech podmíněné logiky je často nejrozumnějším přístupem rekompilace a/nebo úplné dynamické SQL (viz můj příspěvek o „kuchynském dřezu“).
Testy
Vzhledem k tomu, že jsem nedávno začal prohlížet novou vzorovou databázi WideWorldImporters, rozhodl jsem se tam provést vlastní testy. Bylo těžké najít tabulku slušné velikosti bez indexu ColumnStore nebo časové tabulky historie, ale Sales.Invoices , který má 70 510 řádků, má jednoduchý nvarchar(20) sloupec s názvem CustomerPurchaseOrderNumber které jsem se rozhodl použít pro testy. (Proč je to nvarchar(20) když každá jednotlivá hodnota je 5místné číslo, nemám ponětí, ale porovnávání vzorů je ve skutečnosti jedno, zda bajty pod nimi představují čísla nebo řetězce.)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Vzor | <. # řádků% tabulky | |
| Začíná "1" | 70 505 | 99,993 % |
| Začíná "2" | 5 | 0,007 % |
| Končí na "5" | 6 897 | 9,782 % |
| Končí na „30“ | 749 | 1,062 % |
Prohrabal jsem se hodnotami v tabulce, abych přišel s více vyhledávacími kritérii, která by produkovala výrazně odlišný počet řádků, doufejme, že odhalím jakékoli chování bodu zlomu s daným přístupem. Vpravo jsou vyhledávací dotazy, na které jsem se dostal.
Chtěl jsem si dokázat, že výše uvedený postup byl nepopiratelně celkově lepší pro všechna možná vyhledávání než kterýkoli z dotazů, které používají OR podmíněné, bez ohledu na to, zda používají LIKE , LEFT/RIGHT , SUBSTRING nebo CHARINDEX . Vzal jsem Davidovy základní struktury dotazů a vložil je do uložených procedur (s výhradou, že nemohu skutečně testovat „obsahuje“ bez jeho vstupu a že jsem musel vytvořit jeho OR logika trochu flexibilnější, abych získal stejný počet řádků), spolu s verzí mé logiky. Plánoval jsem také otestovat procedury s indexem a bez něj, který bych vytvořil ve vyhledávacím sloupci, a to pod teplou i studenou mezipamětí.
Postupy:
CREATE PROCEDURE dbo.David_LIKE @pattern nvarchar(10), @option varchar(10) -- StartsWith nebo EndsWithASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CustomerPurchaseOrderNumber LIKE @pattern + N'%') OR (@option ='EndsWith' AND CustomerPurchaseOrderNumber LIKEN'% OP) (LIKEpatREPITION) OP;ENDGO CREATE PROCEDURE dbo.David_SUBSTRING @pattern nvarchar(10), @option varchar(10) -- StartsWith nebo EndsWithASBEGIN SET NOCOUNT ON; VYBERTE CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@vzor)) =@vzor) OR (@option ='EndsWith', A SUBURCHberNumberNomberOmberCust - DÉLKA(@vzor) + 1, DÉLKA(@vzor)) =@vzor) MOŽNOST (ZNOVU KOMPILOVAT); ENDGO VYTVOŘIT POSTUP dbo.David_LEFTRIGHT @vzor nvarchar(10), @volba varchar(10) -- ZačínáWith nebo Končí ASBEGIN SET NOCOUNT NA; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND LEFT(CustomerPurchaseOrderNumber, LEN(@vzor)) =@vzor) OR (@option ='EndsWith' AND RIGHT(CustomerPurchaseOrderum) =@pattern) OPTION (REKOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX @pattern nvarchar(10), @option varchar(10) -- StartsWith nebo EndsWithASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CHARINDEX(@vzor, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@vzor)), 0)> 0) NEBO (@option ='CHARINDEX' ANDARENDEX (@vzor, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@vzor) + 1, LEN(@vzor)), 0)> 0) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.Aaron10nchardional , @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'ASBEGIN SET NOCOUNT ON; VYBERTE CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE -- pokud obsahuje nebo končí, je potřeba úvodní zástupný znak CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- pokud obsahuje nebo začíná, je potřeba koncový zástupný znak CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO
Také jsem vytvořil verze Davidových postupů věrné jeho původnímu záměru, za předpokladu, že je skutečně požadavkem najít všechny řádky, kde je vyhledávací vzor na začátku *nebo* na konci řetězce. Udělal jsem to jednoduše, abych mohl porovnat výkon různých přístupů, přesně tak, jak je napsal, abych zjistil, zda na tomto souboru dat budou moje výsledky odpovídat mým testům jeho původního skriptu v mém systému. V tomto případě nebyl důvod zavádět moji vlastní verzi, protože by jednoduše odpovídala jeho LIKE % + @pattern OR LIKE @pattern + % variace.
CREATE PROCEDURE dbo.David_LIKE_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE @vzor + N'%' OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern OPTION (REKOMPILUJTE);ENDGO CREATE PROCEDURE dbo.NOrigal ON SUBchara. SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@vzor)) =@vzor OR SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber), LEN(zákazníkNákup1,pattern) -PATTERNORDER) -LEN) pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@vzor)) =@vzor OR RIGHT(CustomerPurchaseOrderNumber, LEN(@vzor)) =@vzor OPTION (CustomerPurchaseOrderNumber, LEN(@vzor))) (10) ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CHARINDEX(@vzor, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@vzor)), 0)> 0 OR CHARINDEX(@vzor, SUBREDUMNumberNumberPurchaseOrdertern ) + 1, DÉLKA(@vzor)), 0)> 0 MOŽNOST (ZNOVU KOMPILOVAT);ENDGO
Se zavedenými postupy jsem mohl vygenerovat testovací kód – což je často stejně zábavné jako původní problém. Nejprve protokolovací tabulka:
DROP TABLE IF EXISTS dbo.LoggingTable;GOSET NOCOUNT ON; CREATE TABLE dbo.LoggingTable( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), vzor nvarchar(10), frame varchar(11), trvání int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME());Potom kód, který by provedl vybrané operace pomocí různých procedur a argumentů:
SET NOCOUNT ON;;WITH prc(jméno) AS ( SELECT jméno FROM sys.procedures WHERE LEFT(jméno,5) IN (N'David', N'Aaron')),args(opt,pattern) AS ( SELECT 'StartsWith', N' 1' UNION ALL SELECT 'StartsWith', N'2' UNION ALL SELECT 'EndsWith', N'5' UNION ALL SELECT 'EndsWith', N'30'),frame(w) AS ( SELECT 'BeforeIndex' UNION ALL SELECT 'AfterIndex'),y AS( -- zde zakomentujte řádky 2-4, pokud chceme teplou mezipaměť SELECT cmd ='GO DBCC FREEPROCCACHE() S NO_INFOMSGS; DBCC DROPCLEANBUFFERS() S NO_INFOMSGS; GO DECLARE @d datetime2, @delta int; SET @d =SYSUTCDATETIME(); EXEC dbo.' + prc.name + ' @vzor =N''' + args.pattern + '''' + CASE WHEN prc.name LIKE N'%_Original' THEN '' ELSE ',@option =''' + args.opt + '''' END + '; SET @delta =DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME()); INSERT dbo.LoggingTable(prc,opt,pattern,frame ,duration) SELECT N''' + prc.name + ''',''' + args.opt + ''',N''' + args.pattern + ''',''' + frame.w + ''',@delta; ', *, rn =ŘÁDEK_ČÍSLO() PŘES (PARTITIO) N BY frame.w ORDER BY frame.w DESC, LEN(prc.name), args.opt DESC, args.pattern) FROM prc CROSS JOIN args CROSS JOIN frame)SELECT cmd =cmd + CASE WHEN rn =36 THEN CASE WHEN w ='BeforeIndex' THEN 'CREATE INDEX testing ON '+ 'Sales.Invoices(CustomerPurchaseOrderNumber); ' ELSE 'DROP INDEX Sales.Invoices.testing;' END ELSE '' END--, name, opt, pattern, w, rn FROM yORDER BY w DESC, rn;Výsledky
Tyto testy jsem provedl na virtuálním počítači se systémem Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), se 4 CPU a 32 GB RAM. Každou sadu testů jsem provedl 11krát; pro testy teplé mezipaměti jsem vyhodil první sadu výsledků, protože některé z nich byly skutečně testy studené mezipaměti.
Bojoval jsem s tím, jak znázornit výsledky do grafu, většinou proto, že prostě žádné vzory nebyly. Téměř každá metoda byla nejlepší v jednom scénáři a nejhorší v jiném. V následujících tabulkách jsem pro každý sloupec zvýraznil nejlepší a nejhůře fungující postup a můžete vidět, že výsledky nejsou zdaleka průkazné:
V těchto testech někdy CHARINDEX vyhrál a někdy ne.
Zjistil jsem, že celkově, pokud budete čelit mnoha různým situacím (různé typy porovnávání vzorů, s podpůrným indexem nebo ne, data nemohou být vždy v paměti), ve skutečnosti neexistuje jasný vítěz a rozsah výkonu v průměru je docela malý (ve skutečnosti, protože teplá mezipaměť ne vždy pomohla, měl bych podezření, že výsledky byly ovlivněny spíše náklady na vykreslení výsledků než na jejich načítání). U jednotlivých scénářů se nespoléhejte na mé testy; spusťte některé benchmarky sami s ohledem na váš hardware, konfiguraci, data a vzorce používání.
Upozornění
Některé věci jsem u těchto testů nezvažoval:
- Skupinové vs. neshlukované . Protože je nepravděpodobné, že váš seskupený index bude ve sloupci, kde provádíte vyhledávání podle vzoru na začátku nebo na konci řetězce, a protože hledání bude v obou případech z velké části stejné (a rozdíly mezi skeny budou do značné míry být funkcí šířky indexu vs. šířky tabulky), testoval jsem výkon pouze pomocí indexu bez klastrů. Máte-li nějaké konkrétní scénáře, kdy tento rozdíl sám o sobě má zásadní vliv na shodu vzorů, dejte mi prosím vědět.
- MAX typů . Pokud hledáte řetězce v rámci
varchar(max)/nvarchar(max), nelze je indexovat, takže pokud nepoužijete k reprezentaci částí hodnoty vypočítané sloupce, bude vyžadováno skenování – ať už hledáte začínající, končící nebo obsahuje. Netestoval jsem, zda režie výkonu koreluje s velikostí řetězce, nebo je zavedena další režie jednoduše kvůli typu.
- Fulltextové vyhledávání . Hrál jsem si s touto funkcí tady a tam a umím to hláskovat, ale pokud rozumím správně, může to být užitečné pouze v případě, že hledáte celá nepřetržitá slova a nestaráte se o to, kde v řetězci byla nalezeno. Nebylo by užitečné, kdybyste ukládali odstavce textu a chtěli najít všechny odstavce, které začínají na „Y“, obsahují slovo „the“ nebo končí otazníkem.
Shrnutí
Jediným všeobecným prohlášením, které mohu učinit, když odstoupím od tohoto testu, je, že neexistují žádná obecná prohlášení o tom, jaký je nejúčinnější způsob, jak provádět porovnávání řetězců. I když jsem zaujatý vůči svému podmíněnému přístupu pro flexibilitu a udržovatelnost, nebyl to ve všech scénářích vítěz výkonu. Pro mě, pokud nenarazím na překážku ve výkonu a nebudu kráčet po všech cestách, budu i nadále používat svůj přístup pro konzistenci. Jak jsem navrhl výše, pokud máte velmi úzký scénář a jste velmi citliví na malé rozdíly v trvání, budete chtít provést vlastní testy, abyste zjistili, která metoda je pro vás trvale nejlepší.