[ Část 1 | Část 2 | Část 3 | Část 4 ]
V části 3 této série jsem ukázal dvě řešení, jak se vyhnout rozšíření IDENTITY sloupec – jeden, který vám jednoduše kupuje čas, a druhý, který opouští IDENTITY celkem. První vám brání řešit externí závislosti, jako jsou cizí klíče, ale druhý stále tento problém neřeší. V tomto příspěvku jsem chtěl podrobně popsat přístup, který bych zvolil, kdybych nutně potřeboval přejít na bigint , potřeboval minimalizovat prostoje a měl spoustu času na plánování.
Kvůli všem potenciálním blokátorům a potřebě minimálního narušení může být tento přístup považován za trochu složitý a stává se ještě složitějším, pokud se používají další exotické funkce (řekněme dělení, OLTP v paměti nebo replikace) .
Na velmi vysoké úrovni je přístup k vytvoření sady stínových tabulek, kde jsou všechny vložené položky směrovány do nové kopie tabulky (s větším datovým typem) a existence těchto dvou sad tabulek je transparentní co nejvíce pro aplikaci a její uživatele.
Na podrobnější úrovni by sada kroků vypadala takto:
- Vytvářejte stínové kopie tabulek se správnými datovými typy.
- Upravte uložené procedury (nebo ad hoc kód) tak, aby se pro parametry používal bigint. (To může vyžadovat úpravu nad rámec seznamu parametrů, jako jsou místní proměnné, dočasné tabulky atd., ale v tomto případě tomu tak není.)
- Přejmenujte staré tabulky a vytvořte zobrazení s těmito názvy, které spojí staré a nové tabulky.
- Tato zobrazení budou mít namísto spouštěčů správné nasměrování operací DML do příslušných tabulek, aby bylo možné data během migrace stále upravovat.
- To také vyžaduje, aby bylo SCHEMABINDING zrušeno ze všech indexovaných zobrazení, existující pohledy měly sjednocení mezi novými a starými tabulkami a aby byly upraveny procedury založené na SCOPE_IDENTITY().
- Migrujte stará data do nových tabulek po částech.
- Vyčištění, které se skládá z:
- Odstranění dočasných zobrazení (které MÍSTO spouštěčů zruší).
- Přejmenování nových tabulek zpět na původní názvy.
- Oprava uložených procedur pro návrat k SCOPE_IDENTITY().
- Odstranění starých, nyní prázdných tabulek.
- Uvedení SCHEMABINDING zpět na indexovaná zobrazení a opětovné vytvoření seskupených indexů.
Pravděpodobně se můžete vyhnout mnoha pohledům a spouštěčům, pokud můžete řídit veškerý přístup k datům prostřednictvím uložených procedur, ale protože tento scénář je vzácný (a nelze mu věřit na 100 %), ukážu vám těžší cestu.
Počáteční schéma
Ve snaze zachovat tento přístup co nejjednodušší a zároveň se stále zabývat mnoha blokátory, které jsem zmínil dříve v sérii, předpokládejme, že máme toto schéma:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Takže jednoduchá personální tabulka s seskupeným sloupcem IDENTITY, neshlukovaným indexem, vypočítaným sloupcem založeným na sloupci IDENTITY, indexovaným pohledem a samostatnou tabulkou HR/špína, která má cizí klíč zpět do personální tabulky (I nemusím nutně podporovat tento design, jen jej používám pro tento příklad). To všechno jsou věci, které tento problém komplikují, než kdybychom měli samostatnou nezávislou tabulku.
S tímto schématem máme pravděpodobně nějaké uložené procedury, které dělají věci jako CRUD. Jsou to spíše pro dokumentaci než cokoli jiného; Udělám změny v základním schématu tak, aby změny těchto postupů byly minimální. To má simulovat skutečnost, že změna ad hoc SQL z vašich aplikací nemusí být možná a nemusí být nezbytná (dobře, pokud nepoužíváte ORM, který dokáže detekovat tabulku vs. pohled).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Nyní přidejte 5 řádků dat do původních tabulek:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Krok 1 – nové tabulky
Zde vytvoříme novou dvojici tabulek, která bude zrcadlit originály s výjimkou datového typu sloupců ČísloZaměstnance, počátečního zdroje pro sloupec IDENTITA a dočasné přípony u jmen:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Krok 2 – opravte parametry procedury
Zde uvedené procedury (a potenciálně váš ad hoc kód, pokud již nepoužívá typ většího celého čísla) budou vyžadovat velmi malou změnu, aby v budoucnu mohly přijímat hodnoty EmployeeID za horní hranicí celého čísla. I když byste mohli tvrdit, že pokud se chystáte změnit tyto postupy, můžete je jednoduše nasměrovat na nové tabulky, snažím se tvrdit, že konečného cíle můžete dosáhnout s *minimálním* zásahem do stávajícího, trvalého kód.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Krok 3 – zobrazení a spouštění
Bohužel to nelze *všechno* provést potichu. Většinu operací můžeme provádět paralelně a bez ovlivnění souběžného použití, ale kvůli SCHEMABINDING musí být indexovaný pohled změněn a index později znovu vytvořen.
To platí pro všechny ostatní objekty, které používají SCHEMABINDING a odkazují na některou z našich tabulek. Doporučuji jej změnit na neindexovaný pohled na začátku operace a index pouze znovu vytvořit jednou po migraci všech dat, nikoli několikrát v procesu (protože tabulky budou přejmenovány několikrát). Ve skutečnosti to, co udělám, je změnit pohled na spojení nové a staré verze tabulky Zaměstnanci po dobu trvání procesu.
Jedna další věc, kterou musíme udělat, je změnit uloženou proceduru Employee_Add tak, aby dočasně používala @@IDENTITY namísto SCOPE_IDENTITY(). Důvodem je, že spouštěč NAMÍSTO OF, který bude zpracovávat nové aktualizace „Zaměstnanci“, nebude mít viditelnost hodnoty SCOPE_IDENTITY(). To samozřejmě předpokládá, že tabulky nemají po triggery, které ovlivní @@IDENTITY. Doufejme, že tyto dotazy můžete buď změnit v uložené proceduře (kde byste mohli jednoduše namířit INSERT na novou tabulku), nebo kód vaší aplikace nemusí v první řadě spoléhat na SCOPE_IDENTITY().
Uděláme to pod SERIALIZABLE, aby se žádné transakce nepokoušely proniknout dovnitř, když jsou objekty v pohybu. Jedná se o sadu operací převážně pouze s metadaty, takže by to mělo být rychlé.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Krok 4 – Migrace starých dat do nové tabulky
Budeme migrovat data po kouscích, abychom minimalizovali dopad na souběžnost i protokol transakcí, přičemž si vypůjčíme základní techniku z mého starého příspěvku „Rozdělit velké operace mazání na kousky“. Tyto dávky budeme provádět také v SERIALIZABLE, což znamená, že budete chtít být opatrní s velikostí dávky a kvůli stručnosti jsem vynechal zpracování chyb.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Výsledky:
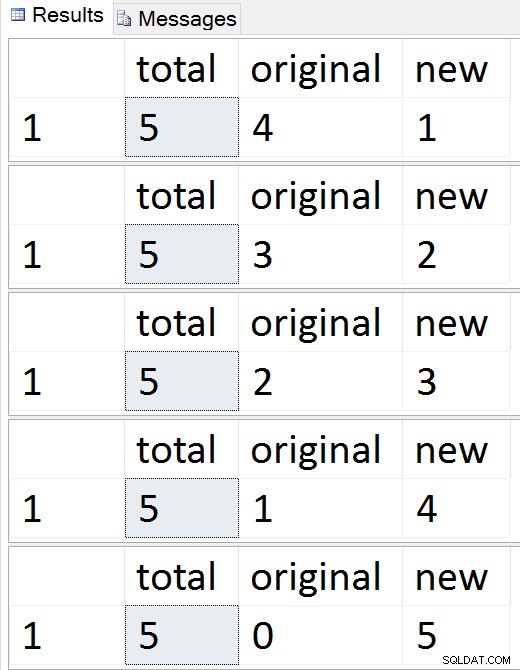 Podívejte se, jak se řádky migrují jeden po druhém
Podívejte se, jak se řádky migrují jeden po druhém
Kdykoli během této sekvence můžete otestovat vložení, aktualizace a odstranění a mělo by se s nimi zacházet odpovídajícím způsobem. Po dokončení migrace můžete přejít ke zbytku procesu.
Krok 5 – Vyčištění
Je vyžadována řada kroků k vyčištění objektů, které byly dočasně vytvořeny, a k obnovení Employees / EmployeeFile jako správných, prvotřídních občanů. Většina těchto příkazů jsou jednoduše operace s metadaty – s výjimkou vytváření seskupeného indexu v indexovaném pohledu by měly být všechny okamžité.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO V tuto chvíli by se vše mělo vrátit do normálního provozu, i když možná budete chtít zvážit typické činnosti údržby po velkých změnách schématu, jako je aktualizace statistik, přestavba indexů nebo vyřazení plánů z mezipaměti.
Závěr
Toto je docela složité řešení toho, co by měl být jednoduchý problém. Doufám, že v určitém okamžiku SQL Server umožní dělat věci, jako je přidání/odebrání vlastnosti IDENTITY, opětovné sestavení indexů s novými cílovými datovými typy a změna sloupců na obou stranách vztahu bez obětování vztahu. Mezitím by mě zajímalo, jestli vám toto řešení pomůže, nebo jestli máte jiný přístup.
Velká výzva Jamesi Lupoltovi (@jlupoltsql) za to, že mi pomohl prověřit můj přístup zdravým rozumem a podrobil ho konečné zkoušce na jednom z jeho vlastních skutečných stolů. (Dopadlo to dobře. Díky Jamesi!)
—
[ Část 1 | Část 2 | Část 3 | Část 4 ]