Toto je třetí z pětidílné série, která se hluboce ponoří do způsobu, jakým se začnou provádět paralelní plány SQL Server v režimu řádků. Část 1 inicializovala kontext provádění nula pro nadřazenou úlohu a část 2 vytvořila strom skenování dotazů. Nyní jsme připraveni zahájit kontrolu dotazů, provést nějakou ranou fázi zpracování a spusťte první další paralelní úlohy.
Spuštění skenování dotazů
Připomeňme, že pouze nadřazený úkol existuje právě teď a burzy (operátoři paralelního systému) mají pouze spotřebitelskou stránku. Přesto to stačí k zahájení provádění dotazu v pracovním vláknu nadřazené úlohy. Procesor dotazů zahájí provádění spuštěním procesu skenování dotazů prostřednictvím volání CQueryScan::StartupQuery . Připomenutí plánu (kliknutím zvětšíte):
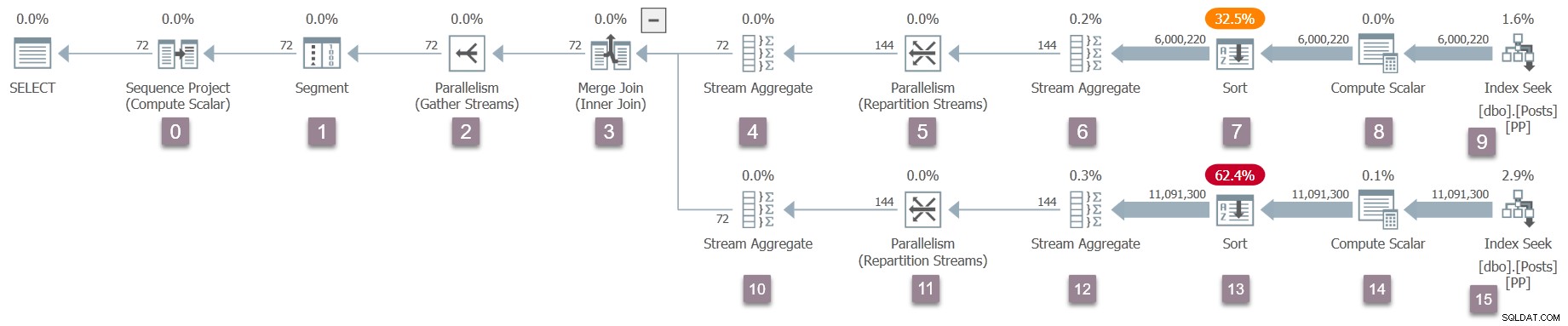
Toto je zatím první bod v procesu plánu provádění za letu je k dispozici (SQL Server 2016 SP1 a novější) v sys.dm_exec_query_statistics_xml . Na takovém plánu v tuto chvíli není k vidění nic zvlášť zajímavého, protože všechny přechodové čítače jsou nulové, ale plán je alespoň dostupný . Nic nenaznačuje, že ještě nebyly vytvořeny paralelní úlohy nebo že výměnám chybí produkční stránka. Plán vypadá ve všech ohledech ‚normálně‘.
Větve paralelního plánu
Protože se jedná o paralelní plán, bude užitečné ukázat jej rozdělený do větví. Ty jsou níže stínované a označené jako větve A až D:
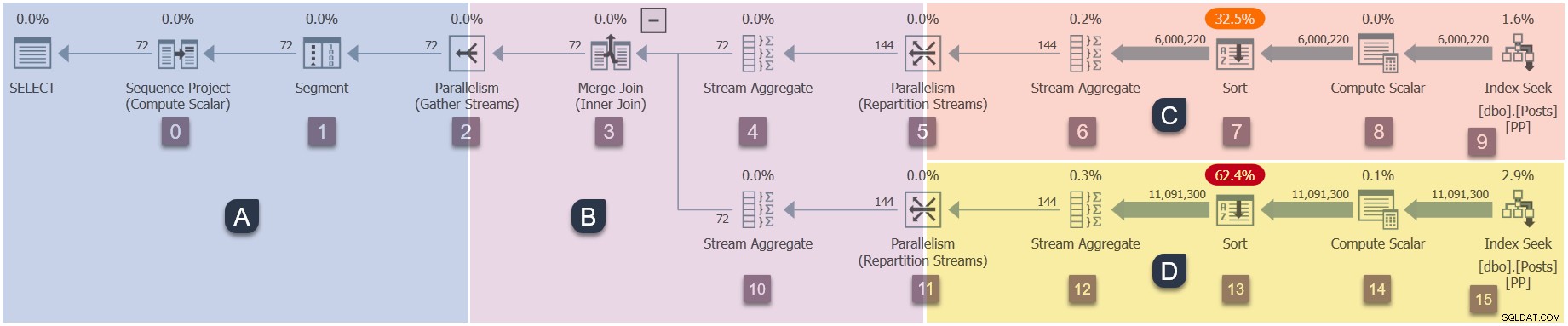
Větev A je přidružena k nadřazené úloze a běží na pracovním vláknu poskytovaném relací. Budou spuštěni další paralelní pracovníci, kteří budou spouštět další paralelní úlohy obsažené ve větvích B, C a D. Tyto větve jsou paralelní, takže v každé budou další úkoly a pracovníci DOP.
Náš vzorový dotaz běží na DOP 2, takže větev B dostane dvě další úlohy. Totéž platí pro větev C a větev D, což dává dohromady šest dodatečné úkoly. Každá úloha poběží na svém vlastním pracovním vláknu ve vlastním kontextu provádění.
Dva plánovače (S1 a S2 ) jsou přiřazeny k tomuto dotazu ke spuštění dalších paralelních pracovníků. Každý další pracovník poběží na jednom z těchto dvou plánovačů. Nadřazený pracovník může běžet na jiném plánovači, takže náš dotaz DOP 2 může používat maximálně tři procesorových jader v kterémkoli okamžiku.
Abychom to shrnuli, náš plán nakonec bude mít:
- Pobočka A (rodič)
- Rodičovský úkol.
- Nadřazené pracovní vlákno.
- Kontext provádění je nulový.
- Jakýkoli jednotlivý plánovač dostupný pro dotaz.
- Pobočka B (doplňkové)
- Dva další úkoly.
- Další pracovní vlákno vázané na každý nový úkol.
- Dva nové kontexty provádění, jeden pro každou novou úlohu.
- Jedno pracovní vlákno běží na plánovači S1 . Druhý běží na plánovači S2 .
- Pobočka C (doplňkové)
- Dva další úkoly.
- Další pracovní vlákno vázané na každý nový úkol.
- Dva nové kontexty provádění, jeden pro každou novou úlohu.
- Jedno pracovní vlákno běží na plánovači S1 . Druhý běží na plánovači S2 .
- Pobočka D (doplňkové)
- Dva další úkoly.
- Další pracovní vlákno vázané na každý nový úkol.
- Dva nové kontexty provádění, jeden pro každou novou úlohu.
- Jedno pracovní vlákno běží na plánovači S1 . Druhý běží na plánovači S2 .
Otázkou je, jak jsou všechny tyto dodatečné úkoly, pracovníci a kontexty provádění vytvořeny a kdy začnou běžet.
Počáteční sekvence
Pořadí, ve kterém jsou další úkoly začněte provádět pro tento konkrétní plán je:
- Větev A (nadřazený úkol).
- Větev C (další paralelní úlohy).
- Větev D (další paralelní úkoly).
- Větev B (další paralelní úkoly).
To nemusí být počáteční příkaz, který jste očekávali.
Může dojít k významnému zpoždění mezi každým z těchto kroků, důvody, které brzy prozkoumáme. Klíčovým bodem v této fázi je, že další úkoly, pracovníci a kontexty provádění nejsou všechny vytvořené najednou a nevytvářejí všechny se spustí ve stejnou dobu.
SQL Server mohl být navržen tak, aby spouštěl všechny další paralelní bity najednou. To by mohlo být snadné pochopit, ale obecně by to nebylo příliš efektivní. Maximalizovalo by to počet dalších vláken a dalších zdrojů používaných dotazem a vedlo by to ke spoustě zbytečných paralelních čekání.
S návrhem používaným SQL Serverem budou paralelní plány často používat méně celkového počtu pracovních vláken než (DOP vynásobené celkovým počtem poboček). Toho je dosaženo uznáním, že některé větve mohou být dokončeny dříve, než je třeba spustit jinou větev. To může umožnit opětovné použití vláken v rámci stejného dotazu a obecně to celkově snižuje spotřebu prostředků.
Pojďme se nyní podívat na podrobnosti o tom, jak náš paralelní plán začíná.
Otevření větve A
Skenování dotazů se spustí s nadřazenou úlohou volající Open() na iterátoru v kořeni stromu. Toto je začátek sekvence provádění:
- Větev A (nadřazený úkol).
- Větev C (další paralelní úlohy).
- Větev D (další paralelní úkoly).
- Větev B (další paralelní úkoly).
Tento dotaz provádíme s požadovaným „skutečným“ plánem, takže kořenový iterátor není operátor sekvenčního projektu v uzlu 0. Je to spíše neviditelný iterátor profilování který zaznamenává metriky běhu v plánech režimu řádků.
Obrázek níže ukazuje iterátory skenování dotazů ve větvi A plánu s pozicí neviditelných iterátorů profilování reprezentovanými ikonami „brýlí“.
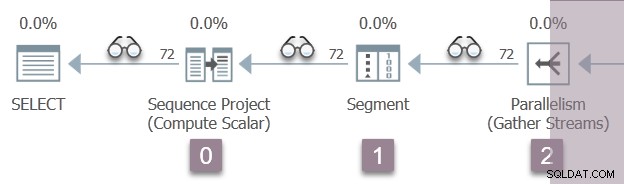
Spuštění začíná voláním k otevření prvního profilovače, CQScanProfileNew::Open . Tím nastavíte čas otevření pro operátora projektu podřízené sekvence prostřednictvím rozhraní API Query Performance Counter operačního systému.
Toto číslo můžeme vidět v sys.dm_exec_query_profiles :
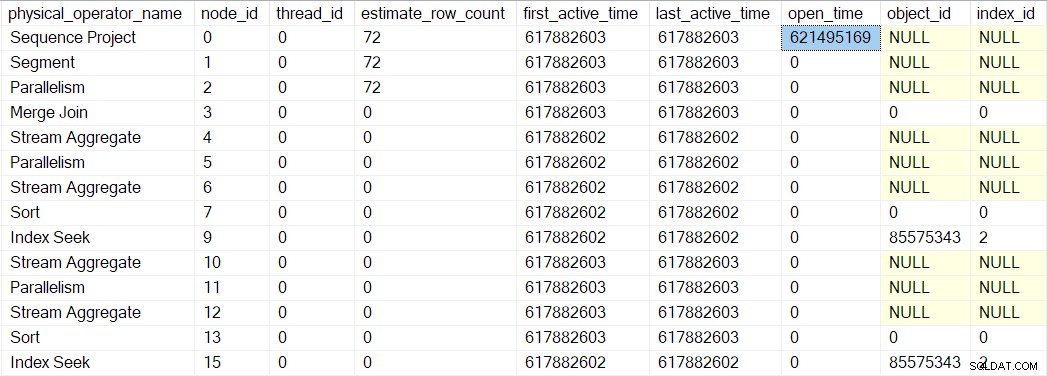
Položky tam mohou mít uvedena jména operátorů, ale data pocházejí z profileru nad operátorem, nikoli nad operátorem samotným.
Jak už to tak bývá, sekvenční projekt (CQScanSeqProjectNew ) po otevření nemusí dělat žádnou práci , takže ve skutečnosti nemá Open() metoda. Profiler nad sekvenčním projektem je zavoláno, takže otevřený čas pro sekvenční projekt je zaznamenán v DMV.
Open profilovače metoda nevolá Open na sekvenčním projektu (protože žádný nemá). Místo toho volá Open na profilovači pro další iterátor v pořadí. Toto je segment iterátor v uzlu 1. Tím se nastaví doba otevření segmentu, stejně jako to udělal předchozí profiler pro sekvenční projekt:
Iterátor segmentu dělá mít po otevření co dělat, takže další volání je CQScanSegmentNew::Open . Jakmile segment udělá, co potřebuje, zavolá profilovač pro další iterátor v pořadí – spotřebitel straně výměny sběrných proudů v uzlu 2:
Dalším voláním stromu skenování dotazů v procesu otevírání je CQScanExchangeNew::Open , což je místo, kde věci začínají být zajímavější.
Otevření výměny sběrných streamů
Požádání spotřebitelské strany burzy o otevření:
- Otevře místní (paralelně vnořenou) transakci (
CXTransLocal::Open). Každý proces potřebuje obsahující transakci a další paralelní úlohy nejsou výjimkou. Nemohou přímo sdílet nadřazenou (základní) transakci, takže se používají vnořené transakce. Když paralelní úloha potřebuje přistupovat k základní transakci, synchronizuje se na latch a může narazit naNESTING_TRANSACTION_READONLYneboNESTING_TRANSACTION_FULLčeká. - Zaregistruje aktuální pracovní vlákno s portem Exchange (
CXPort::Register). - Synchronizuje se s ostatními vlákny na spotřebitelské straně výměny (
sqlmin!CXTransLocal::Synchronize). Na spotřebitelské straně sběrných datových proudů nejsou žádná další vlákna, takže při této příležitosti to v podstatě není možné.
Zpracování „počátečních fází“
Nadřazená úloha nyní dosáhla okraje větve A. Další krok je konkrétní na paralelní plány v režimu řádků:Nadřazená úloha pokračuje v provádění voláním CQScanExchangeNew::EarlyPhases na iterátoru výměny sběrných proudů v uzlu 2. Toto je další metoda iterátoru nad rámec obvyklého Open , GetRow a Close metody, které mnozí z vás budou znát. EarlyPhases se volá pouze v paralelních plánech v režimu řádků.
V tuto chvíli chci mít v něčem jasno:Producentská strana výměny sběrných streamů v uzlu 2 ne dosud vytvořeno a ne byly vytvořeny další paralelní úlohy. Stále provádíme kód pro nadřazenou úlohu pomocí jediného vlákna, které právě běží.
Ne všechny iterátory implementují EarlyPhases , protože ne všechny mají v tomto bodě paralelních plánů v režimu řádků na práci něco zvláštního. To je analogické sekvenčnímu projektu, který neimplementuje Open protože v té době nemá co dělat. Hlavní iterátory s EarlyPhases metody jsou:
CQScanConcatNew(zřetězení).CQScanMergeJoinNew(sloučit připojení).CQScanSwitchNew(přepínač).CQScanExchangeNew(paralelnost).CQScanNew(přístup k sadě řádků, např. prohledávání a vyhledávání).CQScanProfileNew(neviditelní profilovači).CQScanLightProfileNew(neviditelné lehké profilovače).
Počáteční fáze větve B
Rodičovský úkol pokračuje voláním EarlyPhases na podřízených operátorech za výměnou shromažďovacích proudů v uzlu 2. Úloha pohybující se přes hranici větve se může zdát neobvyklá, ale pamatujte, že kontext provádění nula obsahuje celý sériový plán včetně výměn. Zpracování v rané fázi je o inicializaci paralelismu, takže se to nepočítá jako provedení per se .
Abychom vám pomohli udržet si přehled, obrázek níže ukazuje iterátory ve větvi B plánu:
Pamatujte, že jsme stále v kontextu provádění nula, takže to pro usnadnění nazývám pouze jako větev B. Nezačali žádné paralelní provedení.
Pořadí vyvolání kódu rané fáze ve větvi B je:
CQScanProfileNew::EarlyPhasespro profilovač nad uzlem 3.CQScanMergeJoinNew::EarlyPhasesv uzlu 3 sloučení spojení .CQScanProfileNew::EarlyPhasespro profilovač nad uzlem 4. Uzel 4 shromáždí proud sama o sobě nemá metodu raných fází.CQScanProfileNew::EarlyPhasesna profilovači nad uzlem 5.CQScanExchangeNew::EarlyPhasespro přerozdělovací proudy výměna v uzlu 5.
Všimněte si, že v této fázi zpracováváme pouze vnější (horní) vstup pro slučovací spojení. Toto je pouze normální iterační sekvence provádění režimu řádků. Není to specifické pro paralelní plány.
Počáteční fáze větve C
Zpracování rané fáze pokračuje s iterátory ve větvi C:

Posloupnost volání je zde:
CQScanProfileNew::EarlyPhasespro profilovač nad uzlem 6.CQScanProfileNew::EarlyPhasespro profilovač nad uzlem 7.CQScanProfileNew::EarlyPhasesna profilovači nad uzlem 9.CQScanNew::EarlyPhasespro hledání indexu v uzlu 9.
Neexistují žádné EarlyPhases metoda na agregaci nebo řazení proudu. Práce provedená výpočetním skalárem v uzlu 8 je odložena (na řazení), takže se nezobrazuje ve stromu kontroly dotazů a nemá přidružený profilovač.
O časování profileru
Nadřazený úkol zpracování v rané fázi začalo při výměně shromažďovacích proudů v uzlu 2. Sestoupilo se stromem skenování dotazů, po vnějším (horním) vstupu do slučovacího spojení, až dolů k hledání indexu v uzlu 9. Po cestě zavolala rodičovská úloha EarlyPhases metoda na každém iterátoru, který ji podporuje.
Žádná z počátečních fází nebyla dosud aktualizována kdykoli v profilujícím DMV. Konkrétně žádný z iterátorů, jichž se zpracování v raných fázích dotklo, neměl nastavenou „otevřenou dobu“. To dává smysl, protože zpracování v rané fázi pouze nastavuje paralelní provádění – tyto operátory budou otevřeny k provedení později.
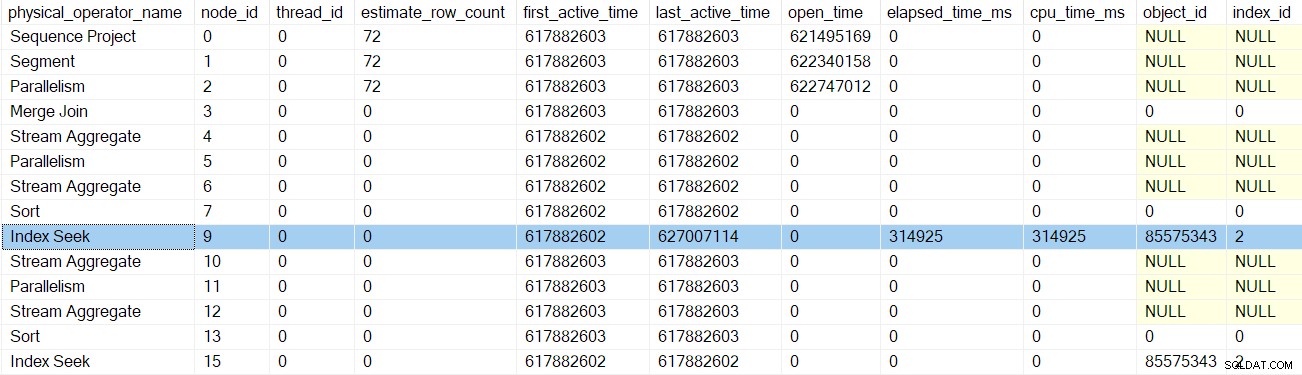
Vyhledávání indexu v uzlu 9 je listový uzel – nemá žádné potomky. Nadřazená úloha se nyní začne vracet z vnořených EarlyPhases hovory, vzestupně strom skenování dotazů zpět k výměně shromažďovacích proudů.
Každý z profilovačů volá Počítadlo výkonu dotazů API při vstupu do jejich EarlyPhases metoda a oni ji volají znovu na cestě ven. Rozdíl mezi těmito dvěma čísly představuje uplynulý čas pro iterátor a všechny jeho podřízené (protože volání metod jsou vnořená).
Poté, co se profiler pro hledání indexu vrátí, profiler DMV zobrazí uplynulý čas a CPU pro hledání indexu pouze a také aktualizované poslední aktivní čas. Všimněte si také, že tyto informace jsou zaznamenány u nadřazeného úkolu (momentálně jediná možnost):
Žádnému z předchozích iterátorů, kterých se volání raných fází dotkla, neuplynuly časy ani neaktualizovaly poslední aktivní časy. Tato čísla se aktualizují pouze při vzestupu stromu.
Po návratu dalšího volání v rané fázi profilovače, třídění časy jsou aktualizovány:
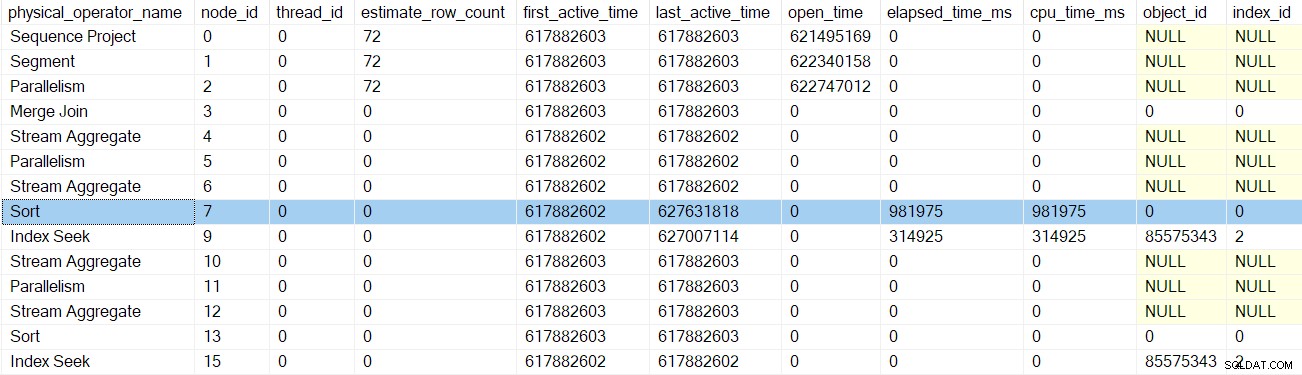
Další návrat nás zavede za profiler pro agregát streamů v uzlu 6:
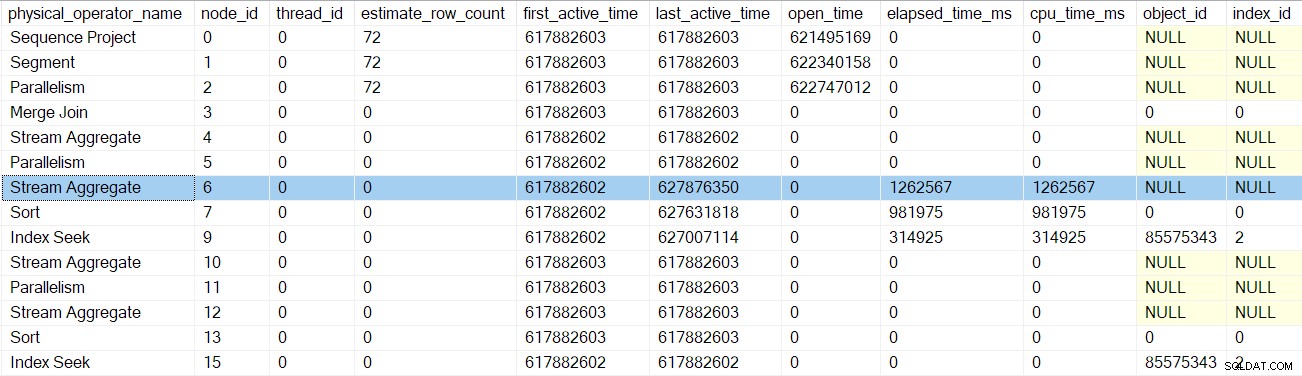
Návrat z tohoto profilovače nás zavede zpět do EarlyPhases zavolejte na přerozdělovací proudy výměna v uzlu 5 . Pamatujte, že zde nezačala sekvence prvních fází volání – to byla výměna sběrných datových proudů v uzlu 2.
Zařazené paralelní úlohy větve C
Kromě aktualizace profilovacích dat se zdálo, že předchozí hovory v raných fázích příliš nefungovaly. To vše se změní s přerozdělovacími proudy výměna v uzlu 5.
Větev C popíšu poměrně podrobně, abych představil řadu důležitých pojmů, které budou platit i pro ostatní paralelní větve. Když nyní pokryjeme tuto půdu, může být pozdější diskuse na pobočce stručnější.
Po dokončení vnořeného zpracování rané fáze pro svůj podstrom (až po hledání indexu v uzlu 9) může burza zahájit vlastní práci v rané fázi. Začíná to stejně jako otevření sběr datových proudů se vyměňuje v uzlu 2:
CXTransLocal::Open(otevření místní paralelní dílčí transakce).CXPort::Register(registrace na výměnném portu).
Další kroky jsou odlišné, protože větev C obsahuje plně blokování iterátor (řazení v uzlu 7). Zpracování rané fáze v uzlu 5 přerozdělovacích proudů provádí následující:
- Volání
CQScanExchangeNew::StartAllProducers. Je to poprvé, co jsme se setkali s něčím, co by odkazovalo na stranu výrobce výměny. Node 5 je první burzou v tomto plánu, která vytvořila svou produkční stranu. - Získává mutex takže žádné jiné vlákno nemůže zařazovat úkoly ve stejnou dobu.
- Spustí paralelní vnořené transakce pro úlohy producenta (
CXPort::StartNestedTransactionsaReadOnlyXactImp::BeginParallelNestedXact). - Zaregistruje dílčí transakce s nadřazeným objektem kontroly dotazu (
CQueryScan::AddSubXact). - Vytváří deskriptory producentů (
CQScanExchangeNew::PxproddescCreate). - Vytváří nové kontexty provádění producentů (
CExecContext) odvozené z kontextu provádění nula. - Aktualizuje propojenou mapu iterátorů plánu.
- Nastaví DOP pro nový kontext (
CQueryExecContext::SetDop), takže všechny úlohy vědí, jaké je celkové nastavení DOP. - Inicializuje mezipaměť parametrů (
CQueryExecContext::InitParamCache). - Propojuje paralelní vnořené transakce se základní transakcí (
CExecContext::SetBaseXact). - Zařadí nové podprocesy do fronty ke spuštění (
SubprocessMgr::EnqueueMultipleSubprocesses). - Vytváří nové paralelní úlohy úkoly přes
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Zásobník volání nadřazeného úkolu (pro ty z vás, které tyto věci baví) v tomto okamžiku je:
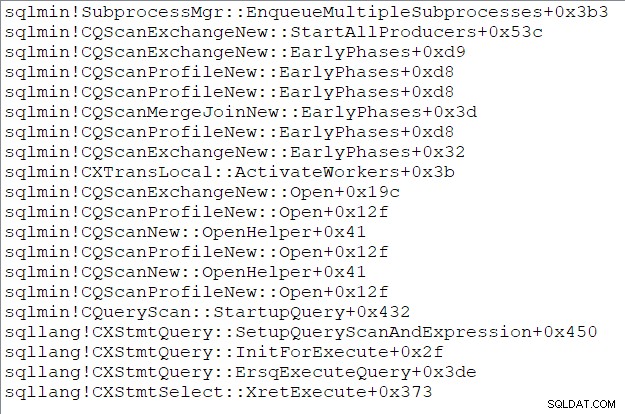
Konec třetí části
Nyní jsme vytvořili stranu výrobce výměny přerozdělovacích proudů v uzlu 5 vytvořily další paralelní úlohy spustit větev C a vše propojit zpět s nadřazeným struktury podle potřeby. Větev C je první větev pro spuštění jakýchkoli paralelních úloh. Poslední část této série se podrobně podívá na otevření větve C a zahájí zbývající paralelní úlohy.