Toto je čtvrtý díl ze série o řešení problému generátoru číselných řad. Mnohokrát děkujeme Alanu Bursteinovi, Joe Obbishovi, Adamu Machanicovi, Christopheru Fordovi, Jeffu Modenovi, Charliemu, NoamGr, Kamilu Kosnovi, Dave Masonovi, Johnu Nelsonovi #2, Edu Wagnerovi, Michaelu Burbeovi a Paulu Whiteovi za sdílení vašich nápadů a komentářů.
Miluji práci Paula Whitea. Stále jsem šokován jeho objevy a zajímalo by mě, jak sakra přišel na to, co dělá. Také se mi líbí jeho efektivní a výmluvný styl psaní. Při čtení jeho článků nebo příspěvků často kroutím hlavou a říkám své ženě Lilach, že až vyrostu, chci být jako Paul.
Když jsem původně zveřejnil výzvu, tajně jsem doufal, že Paul zveřejní řešení. Věděl jsem, že kdyby to udělal, bylo by to velmi speciální. No, udělal, a je to fascinující! Má vynikající výkon a je toho docela dost, co se od něj můžete naučit. Tento článek je věnován Pavlovu řešení.
Provedu své testování v tempdb a povolím I/O a časové statistiky:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Omezení dřívějších nápadů
Při hodnocení dřívějších řešení byla jedním z důležitých faktorů pro dosažení dobrého výkonu schopnost použít dávkové zpracování. Ale využili jsme to v maximální možné míře?
Podívejme se na plány dvou dřívějších řešení, která využívala dávkové zpracování. V části 1 jsem pokryl funkci dbo.GetNumsAlanCharlieItzikBatch, která kombinovala nápady Alana, Charlieho a mě.
Zde je definice funkce:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Toto řešení definuje základní konstruktor hodnot tabulky se 16 řádky a řadu kaskádových CTE s křížovými spoji pro zvýšení počtu řádků na potenciálně 4B. Řešení využívá funkci ROW_NUMBER k vytvoření základní sekvence čísel v CTE nazývané Nums a filtr TOP k filtrování požadované mohutnosti číselné řady. K povolení dávkového zpracování používá řešení fiktivní levé spojení s falešnou podmínkou mezi Nums CTE a tabulkou nazvanou dbo.BatchMe, která má index columnstore.
Pomocí následujícího kódu otestujte funkci pomocí techniky přiřazení proměnných:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zobrazení skutečného v Průzkumníku plánu plán tohoto provedení je znázorněn na obrázku 1.
 Obrázek 1:Plán funkce dbo.GetNumsAlanCharlieItzikBatch
Obrázek 1:Plán funkce dbo.GetNumsAlanCharlieItzikBatch
Při analýze dávkového režimu vs. zpracování v režimu řádků je docela hezké, když se podíváte na plán na vysoké úrovni, můžete zjistit, který režim zpracování každý operátor použil. Ve skutečnosti, Plan Explorer ukazuje světle modrý dávkový obrázek v levé dolní části operátora, když je jeho skutečným režimem provádění Dávka. Jak můžete vidět na obrázku 1, jediným operátorem, který používal dávkový režim, je operátor Window Aggregate, který počítá čísla řádků. Ostatní operátoři v režimu řádků ještě odvedli spoustu práce.
Zde jsou čísla výkonu, která jsem získal ve svém testu:
Čas CPU =10032 ms, uplynulý čas =10025 ms.logické čtení 0
Chcete-li zjistit, kterým operátorům trvalo provedení nejvíce času, použijte možnost Skutečný plán provádění v SSMS nebo možnost Získat skutečný plán v Průzkumníku plánů. Nezapomeňte si přečíst Paulův nedávný článek Understanding Execution Plan Operator Timings. Článek popisuje, jak normalizovat nahlášené doby provádění operátorů, abyste získali správná čísla.
V plánu na obrázku 1 většinu času tráví operátory Nested Loops a Top operátory nejvíce vlevo, přičemž oba pracují v režimu řádků. Kromě toho, že řádkový režim je méně účinný než dávkový režim pro operace náročné na CPU, mějte také na paměti, že přepínání z řádkového do dávkového režimu a zpět si vyžaduje další daň.
V části 2 jsem pokryl další řešení, které využívalo dávkové zpracování, implementované ve funkci dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. Toto řešení spojilo nápady od Johna Number2, Davea Masona, Joe Obbishe, Alana, Charlieho a mě. Hlavní rozdíl mezi předchozím řešením a tímto je v tom, že jako základní jednotka první používá konstruktor virtuálních hodnot tabulky a druhá používá skutečnou tabulku s indexem columnstore, což vám dává dávkové zpracování „zdarma“. Zde je kód, který vytvoří tabulku a naplní ji pomocí příkazu INSERT se 102 400 řádky, aby byla komprimována:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Zde je definice funkce:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Jediné křížové spojení mezi dvěma instancemi základní tabulky je dostačující k vytvoření daleko za požadovaným potenciálem 4B řádků. Řešení zde opět používá funkci ROW_NUMBER k vytvoření základní posloupnosti čísel a filtr TOP k omezení kardinality požadované číselné řady.
Zde je kód pro testování funkce pomocí techniky přiřazení proměnných:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 2.
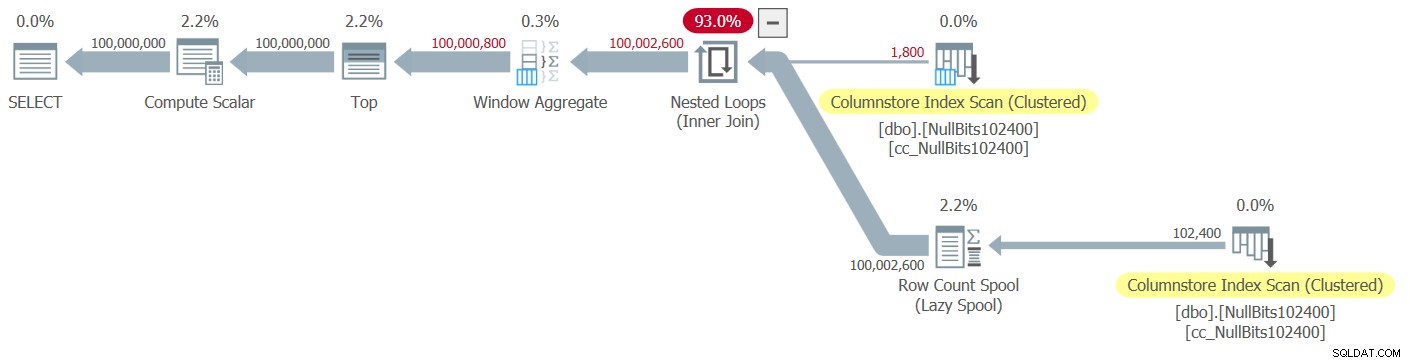 Obrázek 2:Plán pro funkci dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Obrázek 2:Plán pro funkci dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Všimněte si, že pouze dva operátory v tomto plánu využívají dávkový režim – horní skenování klastrovaného indexu columnstore tabulky, který se používá jako vnější vstup spojení Nested Loops, a operátor Window Aggregate, který se používá k výpočtu čísel základních řádků. .
Pro můj test jsem získal následující výkonnostní čísla:
Čas CPU =9812 ms, uplynulý čas =9813 ms.Tabulka 'NullBits102400'. Počet skenů 2, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, logické čtení 8, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Tabulka 'NullBits102400'. Segment má hodnotu 2, segment přeskočen 0.
Opět platí, že většinu času při provádění tohoto plánu stráví operátory Nested Loops a Top operátory nejvíce vlevo, které se provádějí v režimu řádků.
Pavlovo řešení
Než představím Paulovo řešení, začnu svou teorií týkající se myšlenkového procesu, kterým prošel. Toto je ve skutečnosti skvělé cvičení a doporučuji, abyste si ho prošli, než se podíváte na řešení. Paul rozpoznal oslabující účinky plánu, který kombinuje dávkové i řádkové režimy, a postavil si výzvu, aby přišel s řešením, které dostane plán v plném dávkovém režimu. V případě úspěchu je potenciál takového řešení poměrně vysoký. Je jistě zajímavé zjistit, zda je takový cíl vůbec dosažitelný, vzhledem k tomu, že stále existuje mnoho operátorů, kteří ještě nepodporují dávkový režim, a mnoho faktorů, které brání dávkovému zpracování. Například v době psaní tohoto článku byl jediným spojovacím algoritmem, který podporuje dávkové zpracování, algoritmus spojení hash. Křížové spojení je optimalizováno pomocí algoritmu vnořených smyček. Operátor Top je navíc zatím implementován pouze v řádkovém režimu. Tyto dva prvky jsou kritickými základními prvky používanými v plánech mnoha řešení, která jsem dosud pokrýval, včetně dvou výše uvedených.
Za předpokladu, že jste výzvu k vytvoření řešení s plánem všech dávkových režimů slušně zkusili, pojďme k druhému cvičení. Nejprve představím Paulovo řešení tak, jak je poskytl, s jeho vloženými komentáři. Spustím to také, abych porovnal jeho výkon s ostatními řešeními. Naučil jsem se hodně tím, že jsem jeho řešení krok po kroku dekonstruoval a rekonstruoval, abych se ujistil, že jsem pečlivě pochopil, proč použil každou z technik, které dělal. Navrhuji, abyste udělali totéž, než přejdete k přečtení mých vysvětlení.
Zde je Paulovo řešení, které zahrnuje pomocnou tabulku columnstore nazvanou dbo.CS a funkci nazvanou dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Zde je kód, který jsem použil k testování funkce pomocí techniky přiřazení proměnných:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Pro svůj test jsem dostal plán zobrazený na obrázku 3.
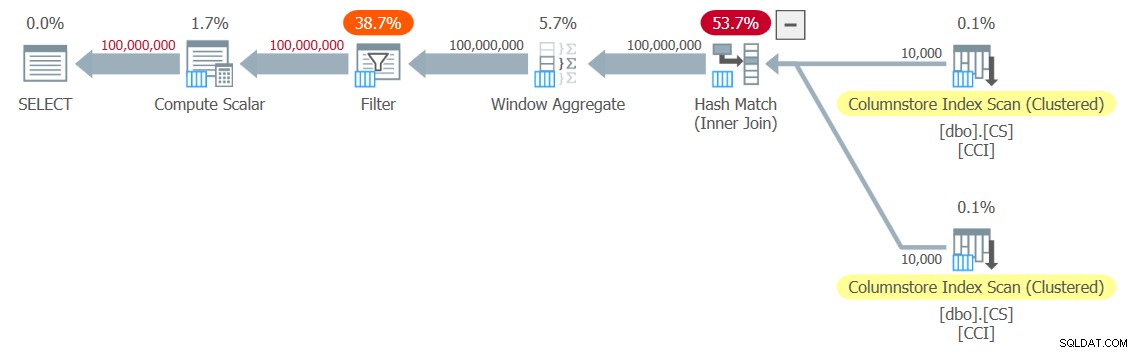 Obrázek 3:Plán pro funkci dbo.GetNums_SQLkiwi
Obrázek 3:Plán pro funkci dbo.GetNums_SQLkiwi
Je to plán v dávkovém režimu! To je docela působivé.
Zde jsou čísla výkonu, která jsem získal pro tento test na mém počítači:
Čas CPU =7812 ms, uplynulý čas =7876 ms.Tabulka 'CS'. Počet skenování 2, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, logické čtení 44, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Tabulka 'CS'. Segment má hodnotu 2, segment přeskočen 0.
Ověřte si také, že pokud potřebujete vrátit čísla uspořádaná podle n, řešení zachovává pořadí vzhledem k rn – alespoň při použití konstant jako vstupů – a vyhnete se tak explicitnímu řazení v plánu. Zde je kód pro otestování objednávky:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Získáte stejný plán jako na obrázku 3, a tedy podobná čísla výkonu:
Čas CPU =7765 ms, uplynulý čas =7822 ms.Tabulka 'CS'. Počet skenování 2, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, logické čtení 44, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Tabulka 'CS'. Segment má hodnotu 2, segment přeskočen 0.
To je důležitá stránka řešení.
Změna metodologie testování
Výkon Paulova řešení je slušným zlepšením jak uplynulého času, tak CPU ve srovnání se dvěma předchozími řešeními, ale nezdá se, že by šlo o dramatičtější zlepšení, které by se dalo očekávat od plánu v dávkovém režimu. Možná nám něco chybí?
Zkusme analyzovat doby provádění operátorů pohledem na skutečný plán provádění v SSMS, jak je znázorněno na obrázku 4.
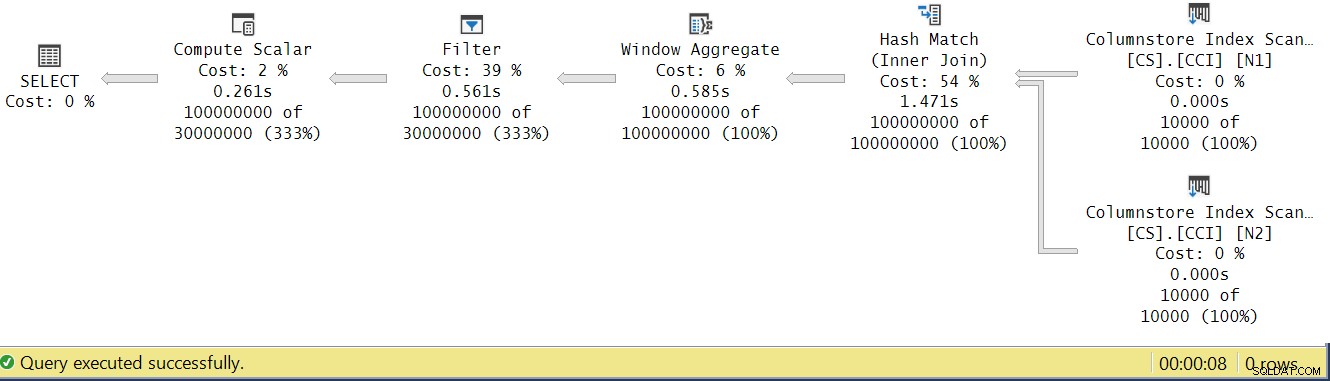 Obrázek 4:Doba provádění operátora pro funkci dbo.GetNums_SQLkiwi
Obrázek 4:Doba provádění operátora pro funkci dbo.GetNums_SQLkiwi
V Paulově článku o analýze časů provádění operátorů vysvětluje, že v dávkovém režimu každý operátor hlásí svůj vlastní čas provádění. Pokud sečtete časy provádění všech operátorů v tomto skutečném plánu, dostanete 2,878 sekund, ale provedení plánu trvalo 7,876. Zdá se, že chybí 5 sekund doby provedení. Odpověď na to spočívá v technice testování, kterou používáme, s přiřazením proměnných. Připomeňme, že jsme se rozhodli použít tuto techniku, abychom odstranili potřebu posílat všechny řádky ze serveru volajícímu a abychom se vyhnuli I/O, které by byly zapojeny do zápisu výsledku do tabulky. Zdálo se to jako ideální volba. Skutečná cena přiřazení proměnné je však v tomto plánu skryta a samozřejmě se provádí v režimu řádků. Záhada vyřešena.
Je zřejmé, že na konci dne je dobrý test testem, který adekvátně odráží vaše produkční využití řešení. Pokud obvykle zapisujete data do tabulky, potřebujete, aby to odrážel váš test. Pokud pošlete výsledek volajícímu, potřebujete, aby to odrážel váš test. V každém případě se zdá, že přiřazení proměnné představuje velkou část doby provádění v našem testu a je nepravděpodobné, že by představovalo typické produkční použití funkce. Paul navrhl, že namísto přiřazení proměnných by test mohl použít jednoduchý agregát jako MAX na vrácený číselný sloupec (n/rn/op). Operátor agregátu může využívat dávkové zpracování, takže plán nebude zahrnovat konverzi z dávkového do řádkového režimu v důsledku jeho použití a jeho příspěvek k celkové době běhu by měl být poměrně malý a známý.
Pojďme tedy znovu otestovat všechna tři řešení uvedená v tomto článku. Zde je kód pro testování funkce dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Pro tento test mám plán zobrazený na obrázku 5.
 Obrázek 5:Plán funkce dbo.GetNumsAlanCharlieItzikBatch s agregací
Obrázek 5:Plán funkce dbo.GetNumsAlanCharlieItzikBatch s agregací
Zde jsou čísla výkonu, která jsem získal pro tento test:
Čas CPU =8469 ms, uplynulý čas =8733 ms.logické čtení 0
Všimněte si, že doba běhu klesla z 10,025 sekund pomocí techniky přiřazení proměnných na 8,733 pomocí techniky agregace. To je něco málo přes sekundu doby provádění, kterou zde můžeme připsat přiřazení proměnné.
Zde je kód pro testování funkce dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Pro tento test mám plán zobrazený na obrázku 6.
 Obrázek 6:Plán pro dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 s funkcí agregace
Obrázek 6:Plán pro dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 s funkcí agregace
Zde jsou čísla výkonu, která jsem získal pro tento test:
Čas CPU =7031 ms, uplynulý čas =7053 ms.Tabulka 'NullBits102400'. Počet skenů 2, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, logické čtení 8, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Tabulka 'NullBits102400'. Segment má hodnotu 2, segment přeskočen 0.
Všimněte si, že doba běhu klesla z 9,813 sekund pomocí techniky přiřazení proměnné na 7,053 pomocí techniky agregace. To je něco přes dvě sekundy doby provádění, kterou zde můžeme připsat přiřazení proměnné.
A zde je kód pro testování Paulova řešení:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Pro tento test mám plán zobrazený na obrázku 7.
 Obrázek 7:Plán funkce dbo.GetNums_SQLkiwi s agregací
Obrázek 7:Plán funkce dbo.GetNums_SQLkiwi s agregací
A teď k tomu velkému okamžiku. Pro tento test jsem získal následující čísla výkonu:
Čas CPU =3125 ms, uplynulý čas =3149 ms.Tabulka 'CS'. Počet skenování 2, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, logické čtení 44, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Tabulka 'CS'. Segment má hodnotu 2, segment přeskočen 0.
Doba běhu klesla z 7,822 sekund na 3,149 sekund! Podívejme se na doby provádění operátorů ve skutečném plánu v SSMS, jak je znázorněno na obrázku 8.
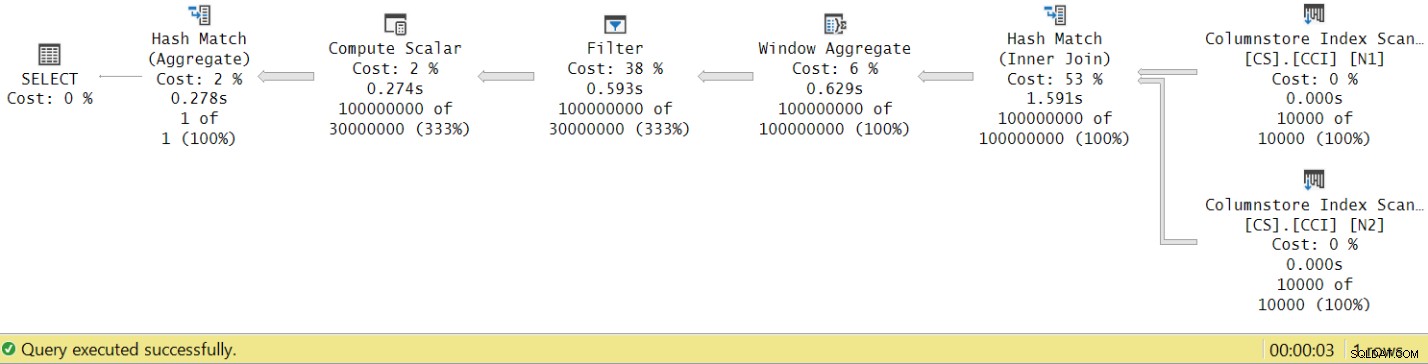 Obrázek 8:Doba provádění operátora pro funkci dbo.GetNums s agregací
Obrázek 8:Doba provádění operátora pro funkci dbo.GetNums s agregací
Pokud nyní shromáždíte doby provádění jednotlivých operátorů, dostanete podobné číslo, jako je celková doba provádění plánu.
Obrázek 9 ukazuje srovnání výkonu z hlediska uplynulého času mezi třemi řešeními pomocí technik přiřazení proměnných a agregovaného testování.
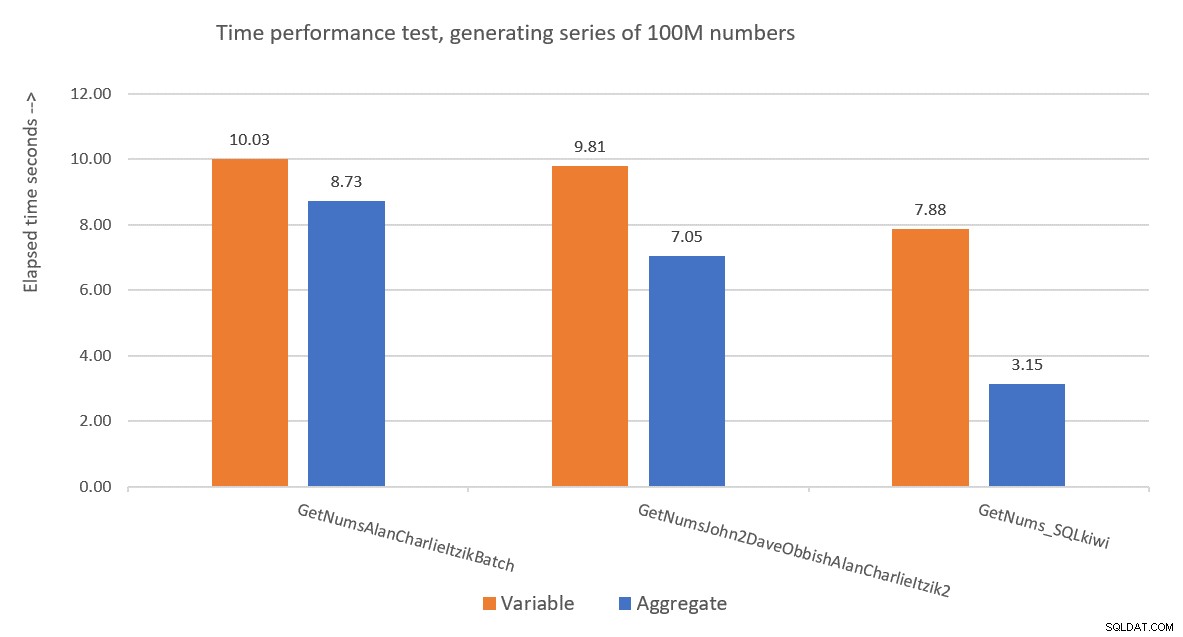 Obrázek 9:Porovnání výkonu
Obrázek 9:Porovnání výkonu
Paulovo řešení je jasným vítězem a to je zvláště patrné při použití techniky agregovaného testování. Jaký působivý výkon!
Dekonstrukce a rekonstrukce Pavlova řešení
Dekonstrukce a následná rekonstrukce Paulova řešení je skvělé cvičení a můžete se při tom hodně naučit. Jak bylo navrženo dříve, doporučuji, abyste si tento proces prošli sami, než budete pokračovat ve čtení.
První volbou, kterou musíte udělat, je technika, kterou byste použili k vygenerování požadovaného potenciálního počtu řádků 4B. Paul se rozhodl použít tabulku columnstore a naplnit ji tolika řádky, jako je druhá odmocnina požadovaného čísla, což znamená 65 536 řádků, takže jediným křížovým spojením získáte požadovaný počet. Možná si myslíte, že s méně než 102 400 řádky byste nezískali komprimovanou skupinu řádků, ale to platí, když tabulku naplníte příkazem INSERT, jako jsme to udělali s tabulkou dbo.NullBits102400. Neplatí to, když vytváříte index columnstore v předvyplněné tabulce. Paul tedy použil příkaz SELECT INTO k vytvoření a naplnění tabulky jako haldy založené na úložišti řádků s 65 536 řádky a poté vytvořil seskupený index columnstore, jehož výsledkem byla komprimovaná skupina řádků.
Další výzvou je zjistit, jak dosáhnout toho, aby bylo křížové spojení zpracováno operátorem dávkového režimu. K tomu potřebujete, aby byl algoritmus spojení hash. Pamatujte, že křížové spojení je optimalizováno pomocí algoritmu vnořených smyček. Nějakým způsobem potřebujete oklamat optimalizátor, aby si myslel, že používáte vnitřní ekvijoin (hash vyžaduje alespoň jeden predikát založený na rovnosti), ale v praxi použijte křížové spojení.
Zřejmým prvním pokusem je použití vnitřního spojení s umělým predikátem spojení, který je vždy pravdivý, například takto:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Tento kód však selže s následující chybou:
Zpráva 8622, úroveň 16, stav 1, řádek 246Procesor dotazu nemohl vytvořit plán dotazu kvůli radám definovaným v tomto dotazu. Znovu odešlete dotaz bez zadání jakýchkoli rad a bez použití SET FORCEPLAN.
Optimalizátor SQL Server rozpozná, že se jedná o umělý predikát vnitřního spojení, zjednoduší vnitřní spojení s křížovým spojením a vytvoří chybu, která říká, že nemůže vyhovět nápovědě k vynucení algoritmu spojení hash.
Aby to vyřešil, vytvořil Paul ve své tabulce dbo.CS sloupec INT NOT NULL (více o tom, proč tato specifikace brzy), nazvaný n1 a naplnil jej 0 ve všech řádcích. Potom použil predikát spojení N2.n1 =N1.n1, čímž efektivně získal návrh 0 =0 ve všech hodnoceních shody, přičemž dodržel minimální požadavky na algoritmus spojení hash.
To funguje a vytváří plán v dávkovém režimu:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Pokud jde o důvod, proč má být n1 definováno jako INT NOT NULL; proč zakázat hodnoty NULL a proč nepoužít BIGINT? Důvodem pro tyto volby je vyhnout se zbytkům hašovací sondy (zvláštní filtr, který je aplikován operátorem hašovacího spojení nad rámec původního predikátu spojení), což by mohlo vést ke zbytečným nákladům navíc. Podrobnosti najdete v Paulově článku Join Performance, Implicit Conversions, and Residuals. Zde je část článku, která je pro nás relevantní:
"Pokud je spojení na jednom sloupci zadaném jako tinyint, smallint nebo integer a pokud jsou oba sloupce omezeny tak, aby NEBYLY NULL, hashovací funkce je "dokonalá" - což znamená, že neexistuje žádná šance na kolizi hash a procesor dotazu nemusí znovu kontrolovat hodnoty, aby se ujistil, že se skutečně shodují.Upozorňujeme, že tato optimalizace se nevztahuje na velké sloupce."
Chcete-li zkontrolovat tento aspekt, vytvořte další tabulku s názvem dbo.CS2 se sloupcem n1 s možnou hodnotou null:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Nejprve otestujeme dotaz proti dbo.CS (kde n1 je definováno jako INT NOT NULL), vygeneruje se 4B čísel základních řádků ve sloupci nazvaném rn a použije se na sloupec agregát MAX:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Porovnáme plán pro tento dotaz s plánem pro podobný dotaz proti dbo.CS2 (kde n1 je definováno jako INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Plány pro oba dotazy jsou zobrazeny na obrázku 10.
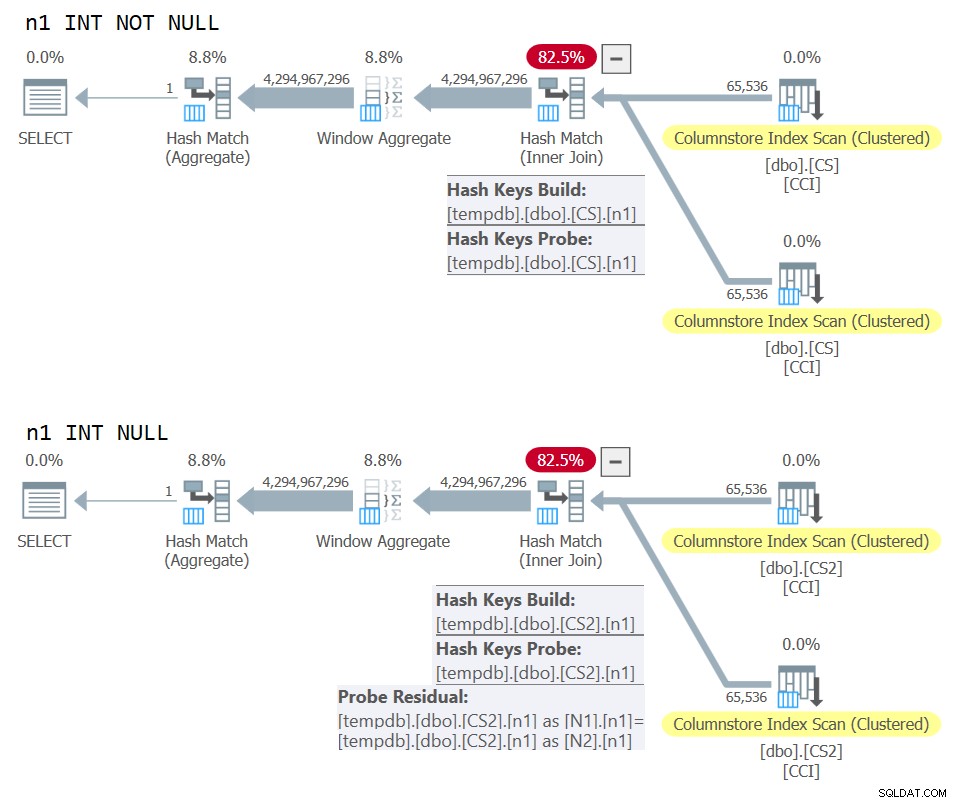 Obrázek 10:Porovnání plánu pro klíč spojení NOT NULL vs NULL
Obrázek 10:Porovnání plánu pro klíč spojení NOT NULL vs NULL
Můžete jasně vidět další reziduum sondy, které je aplikováno ve druhém plánu, ale ne v prvním.
Na mém počítači byl dotaz na dbo.CS dokončen za 91 sekund a dotaz na dbo.CS2 byl dokončen za 92 sekund. V Paulově článku uvádí 11% rozdíl ve prospěch případu NOT NULL pro příklad, který použil.
BTW, ti z vás s bystrým pohledem si jistě všimli použití ORDER BY @@TRANCOUNT jako specifikace objednávky funkce ROW_NUMBER. Pokud jste si pozorně přečetli Paulovy vložené komentáře v jeho řešení, zmiňuje, že použití funkce @@TRANCOUNT je inhibitor paralelismu, zatímco použití @@SPID nikoli. Takže můžete použít @@TRANCOUNT jako konstantu doby běhu ve specifikaci objednávky, když chcete vynutit sériový plán, a @@SPID, když nechcete.
Jak již bylo zmíněno, spuštění dotazu proti dbo.CS na mém počítači trvalo 91 sekund. V tomto okamžiku by mohlo být zajímavé otestovat stejný kód se skutečným křížovým spojením a nechat optimalizátor použít algoritmus spojení vnořených smyček v režimu řádků:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Dokončení tohoto kódu na mém počítači trvalo 104 sekund. Díky spojení hash v dávkovém režimu tedy dosáhneme značného zlepšení výkonu.
Naším dalším problémem je skutečnost, že při použití TOP k filtrování požadovaného počtu řádků získáte plán s operátorem Top v režimu řádků. Zde je pokus o implementaci funkce dbo.GetNums_SQLkiwi s TOP filtrem:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Pojďme otestovat funkci:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Pro tento test mám plán zobrazený na obrázku 11.
 Obrázek 11:Plán s TOP filtrem
Obrázek 11:Plán s TOP filtrem
Všimněte si, že operátor Top je jediný v plánu, který používá zpracování v režimu řádků.
Získal jsem následující časové statistiky pro toto provedení:
Čas CPU =6078 ms, uplynulý čas =6071 ms.Největší část doby běhu v tomto plánu stráví horní operátor v režimu řádků a skutečnost, že plán musí projít převodem v režimu dávky na řádky a zpět.
Naším úkolem je vymyslet alternativu filtrování v dávkovém režimu k TOP režimu řádků. Predikátové filtry, jako jsou ty aplikované s klauzulí WHERE, mohou být potenciálně zpracovány pomocí dávkového zpracování.
Paulův přístup spočíval v zavedení druhého sloupce typu INT (viz vložený komentář „stejně je vše normalizováno na 64 bitů v režimu columnstore/batch“ ) zavolal n2 do tabulky dbo.CS a naplnil ji celočíselnou sekvencí 1 až 65 536. V kódu řešení použil dva predikátové filtry. Jedním z nich je hrubý filtr ve vnitřním dotazu s predikáty zahrnujícími sloupec n2 z obou stran spojení. Tento hrubý filtr může mít za následek některé falešně pozitivní výsledky. Zde je první zjednodušující pokus o takový filtr:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Se vstupy 1 a 100 000 000 jako @nízká a @vysoká nezískáte žádné falešné poplachy. Ale zkuste to s 1 a 100 000 001 a nějaké dostanete. Získáte sekvenci 100 020 001 čísel namísto 100 000 001.
K odstranění falešných poplachů přidal Paul druhý, přesný filtr zahrnující sloupec rn ve vnějším dotazu. Zde je první zjednodušující pokus o tak přesný filtr:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Upravme definici funkce tak, aby používala výše uvedené predikátové filtry namísto TOP, vezměte 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Pojďme otestovat funkci:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Pro tento test mám plán zobrazený na obrázku 12.
 Obrázek 12:Plán s filtrem WHERE, vezměte 1
Obrázek 12:Plán s filtrem WHERE, vezměte 1
Bohužel, něco se zjevně pokazilo. SQL Server převedl náš predikátový filtr obsahující sloupec rn na filtr založený na TOP a optimalizoval jej pomocí operátoru Top – což je přesně to, čemu jsme se snažili vyhnout. Aby se přidalo urážka ke zranění, optimalizátor se také rozhodl použít pro spojení algoritmus vnořených smyček.
Dokončení tohoto kódu na mém počítači trvalo 18,8 sekund. Nevypadá dobře.
Pokud jde o spojení vnořených smyček, je to něco, o co bychom se mohli snadno postarat pomocí nápovědy pro spojení ve vnitřním dotazu. Abychom viděli dopad na výkon, zde je test s nápovědou k dotazu s vynuceným hashovacím spojením použitým v samotném testovacím dotazu:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Doba běhu se zkrátí na 13,2 sekundy.
Stále máme problém s převodem filtru WHERE proti rn na filtr TOP. Pokusme se pochopit, jak se to stalo. Ve vnějším dotazu jsme použili následující filtr:
WHERE N.rn < @high - @low + 2
Pamatujte, že rn představuje nezmanipulovaný výraz založený na ROW_NUMBER. Filtr založený na takovém nemanipulovaném výrazu, který je v daném rozsahu, je často optimalizován pomocí operátoru Top, což je pro nás špatná zpráva kvůli použití zpracování v režimu řádků.
Pavlovým řešením bylo použít ekvivalentní predikát, ale takový, který aplikuje manipulaci na rn, jako je tento:
WHERE @low - 2 + N.rn < @high
Filtrování výrazu, který přidává manipulaci k výrazu založenému na ROW_NUMBER, zabrání převodu filtru založeného na predikátu na filtr založený na TOP. To je skvělé!
Upravme definici funkce tak, aby používala výše uvedený predikát WHERE, vezměme 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Otestujte funkci znovu, bez zvláštních rad nebo čehokoli:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Přirozeně získává plán v dávkovém režimu s algoritmem hašovacího spojení a bez top operátora, což má za následek dobu provedení 3,177 sekundy. Vypadá dobře.
Dalším krokem je zkontrolovat, zda řešení dobře zpracovává špatné vstupy. Zkusme to se zápornou deltou:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
Toto spuštění se nezdaří s následující chybou.
Zpráva 3623, úroveň 16, stav 1, řádek 436Došlo k neplatné operaci s pohyblivou řádovou čárkou.
Selhání je způsobeno pokusem o použití druhé odmocniny záporného čísla.
Pavlovo řešení zahrnovalo dva dodatky. Jedním z nich je přidat následující predikát do klauzule WHERE vnitřního dotazu:
@high >= @low
Tento filtr umí víc, než se na první pohled zdá. Pokud jste pozorně četli Paulovy komentáře, můžete najít tuto část:
„Snažte se vyhnout SQRT na záporných číslech a povolte zjednodušení na jediné konstantní skenování, pokud @nízká> @vysoká (s literály). Žádné spouštěcí filtry v dávkovém režimu.“Zajímavou částí je zde možnost použití konstantního skenování s konstantami jako vstupy. Brzy se k tomu dostanu.
Dalším doplňkem je použití funkce IIF na vstupní výraz funkce SQRT. To se provádí, abychom se vyhnuli zápornému vstupu při použití nekonstant jako vstupů do naší funkce čísel a v případě, že se optimalizátor rozhodne zpracovat predikát zahrnující SQRT před predikátem @high>=@low.
Před přidáním IIF vypadal predikát zahrnující N1.n2 například takto:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Zkuste to:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Závěr
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.