Toto je druhá část pětidílné série, která se hluboce ponoří do způsobu spouštění paralelních plánů v režimu řádků SQL Server. Na konci první části jsme vytvořili kontext nula pro nadřazený úkol. Tento kontext obsahuje celý strom spustitelných operátorů, ale ty ještě nejsou připraveny na iterativní spouštěcí model stroje pro zpracování dotazů.
Opakované spouštění
SQL Server provádí dotaz prostřednictvím procesu známého jako kontrola dotazů . Inicializace plánu začíná v kořenovém adresáři dotazovacím procesorem voláním Open na kořenovém uzlu. Open volání procházejí stromem iterátorů a rekurzivně volají Open na každé dítě, dokud se neotevře celý strom.
Proces vracení řádků výsledků je také rekurzivní, spouští jej dotazovací procesor, který volá GetRow u kořene. Každé kořenové volání vrací řádek po druhém. Dotazový procesor pokračuje ve volání GetRow na kořenovém uzlu, dokud nebudou k dispozici žádné další řádky. Spouštění se ukončí závěrečným rekurzivním Close volání. Toto uspořádání umožňuje procesoru dotazů inicializovat, spouštět a zavírat libovolný plán voláním stejných metod rozhraní přímo v kořenovém adresáři.
Pro transformaci stromu spustitelných operátorů na strom vhodný pro zpracování řádek po řádku přidává SQL Server skenování dotazů obal každému operátorovi. skenování dotazů objekt poskytuje Open , GetRow a Close metody potřebné pro iterativní provádění.
Objekt kontroly dotazu také uchovává informace o stavu a zpřístupňuje další metody specifické pro operátora potřebné během provádění. Například objekt skenování dotazu pro operátor Start-Up Filter (CQScanStartupFilterNew ) zpřístupňuje následující metody:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Další metody pro tento iterátor se většinou používají v plánech kurzoru.
Inicializace kontroly dotazů
Proces zalamování se nazývá inicializace kontroly dotazů . Provádí se voláním z procesoru dotazů na CQueryScan::InitQScanRoot . Nadřazený úkol provádí tento proces pro celý plán (obsaženo v kontextu provádění nula). Proces překladu je sám o sobě rekurzivní povahy, začíná u kořene a pokračuje ve stromu.
Během tohoto procesu je každý operátor zodpovědný za inicializaci svých vlastních dat a vytvoření jakýchkoli runtime zdrojů potřebuje to. To může zahrnovat vytváření dalších objektů mimo dotazovací procesor, například struktury potřebné pro komunikaci s modulem úložiště pro načítání dat z trvalého úložiště.
Připomenutí prováděcího plánu s přidanými čísly uzlů (kliknutím zvětšíte):
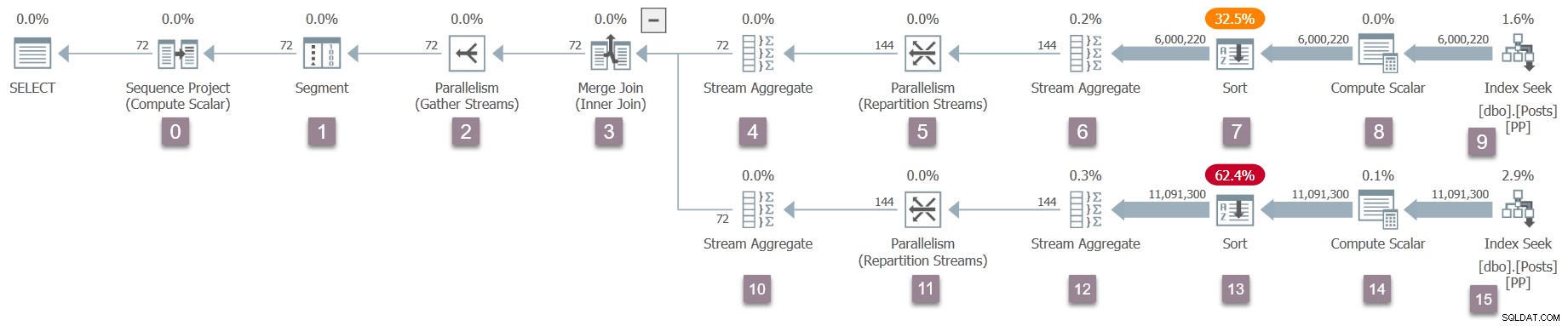
Operátor v kořenovém adresáři (uzel 0) stromu spustitelného plánu je sekvenční projekt . Je reprezentován třídou s názvem CXteSeqProject . Jako obvykle zde začíná rekurzivní transformace.
Obálky skenování dotazů
Jak již bylo zmíněno, CXteSeqProject objekt není vybaven k účasti na iterativní kontrole dotazů proces — nemá požadovaný Open , GetRow a Close metody. Procesor dotazů potřebuje obal kolem spustitelného operátoru, aby poskytoval toto rozhraní.
Chcete-li získat tento obal skenování dotazů, nadřazená úloha zavolá CXteSeqProject::QScanGet vrátit objekt typu CQScanSeqProjectNew . Propojená mapa dříve vytvořených operátorů je aktualizováno tak, aby odkazovalo na nový objekt kontroly dotazu, a jeho metody iterátoru jsou propojeny s kořenem plánu.
Podřízeným projektem sekvenčního projektu je segment operátor (uzel 1). Volání CXteSegment::QScanGet vrátí objekt obálky dotazu typu CQScanSegmentNew . Propojená mapa se znovu aktualizuje a ukazatele funkcí iterátoru se připojí ke skenování dotazu projektu nadřazené sekvence.
Polovina výměny
Dalším operátorem je výměna sběrných proudů (uzel 2). Volání CXteExchange::QScanGet vrátí CQScanExchangeNew jak už možná očekáváte.
Toto je první operátor ve stromu, který potřebuje provést významnou extra inicializaci. Vytváří stranu spotřebitele výměny prostřednictvím CXTransport::CreateConsumerPart . Tím se vytvoří port (CXPort ) — datová struktura ve sdílené paměti používaná pro synchronizaci a výměnu dat — a roura (CXPipe ) pro přepravu paketů. Všimněte si, že výrobce strana burzy není vytvořena v tuto chvíli. Máme jen poloviční výměnu!
Další balení
Proces nastavení kontroly procesoru dotazů pak pokračuje připojením ke sloučení (uzel 3). Nebudu vždy opakovat QScanGet a CQScan* volání od tohoto bodu, ale řídí se zavedeným vzorem.
Sloučení spojení má dvě potomky. Nastavení kontroly dotazů pokračuje jako dříve s vnějším (horním) vstupem — agregátem proudu (uzel 4), pak přerozdělení streamuje výměnu (uzel 5). Přerozdělovací toky opět vytvářejí pouze spotřebitelskou stranu výměny, ale tentokrát jsou vytvořeny dvě roury, protože DOP jsou dvě. Spotřebitelská strana tohoto typu výměny má připojení DOP ke svému nadřazenému operátorovi (jedno na vlákno).
Dále máme další agregát streamů (uzel 6) a třídění (uzel 7). Řazení má potomka, který není viditelný v plánech provádění – sada řádků úložiště, která se používá k implementaci přelévání do tempdb . Očekávaný CQScanSortNew je proto doprovázeno potomkem CQScanRowsetNew ve vnitřním stromu. Není vidět ve výstupu showplanu.
I/O profilování a odložené operace
Řazení Operátor je také prvním, který jsme zatím inicializovali a který může být zodpovědný za I/O . Za předpokladu, že si provedení vyžádalo I/O profilovací data (např. vyžádáním „skutečného“ plánu), řazení vytvoří objekt pro záznam těchto runtime profilovacích dat přes CProfileInfo::AllocProfileIO .
Dalším operátorem je výpočetní skalár (uzel 8), nazývaný projekt vnitřně. Volání nastavení skenování dotazů do CXteProject::QScanGet ne vrátit objekt kontroly dotazu, protože výpočty provedené tímto výpočetním skalárem jsou odloženy na první nadřazený operátor, který potřebuje výsledek. V tomto plánu je daný operátor. Třídění provede veškerou práci přiřazenou výpočetnímu skaláru, takže projekt v uzlu 8 netvoří součást stromu skenování dotazů. Výpočetní skalár skutečně není spuštěn za běhu. Další podrobnosti o odložených výpočetních skalárech najdete v části Compute Scalars, Expressions and Execution Plan Performance.
Paralelní skenování
Konečným operátorem po výpočetním skaláru na této větvi plánu je hledání indexu (CXteRange ) v uzlu 9. Tím vznikne očekávaný operátor skenování dotazu (CQScanRangeNew ), ale také vyžaduje složitou sekvenci inicializací pro připojení k modulu úložiště a usnadnění paralelního skenování indexu.
Stačí pokrýt zvýraznění, inicializovat hledání indexu:
- Vytvoří objekt profilování pro I/O (
CProfileInfo::AllocProfileIO). - Vytvoří paralelní sadu řádků skenování dotazů (
CQScanRowsetNew::ParallelGetRowset). - Nastaví synchronizaci objekt ke koordinaci runtime paralelního skenování rozsahu (
CQScanRangeNew::GetSyncInfo). - Vytvoří kurzor tabulky úložiště a deskriptor transakce pouze pro čtení .
- Otevře nadřazenou sadu řádků pro čtení (přístup k HoBt a převzetí potřebných zámků).
- Nastaví časový limit uzamčení.
- Nastaví předběžné načítání (včetně souvisejících vyrovnávacích pamětí).
Přidání operátorů profilování v režimu řádků
Nyní jsme dosáhli úrovně listu této větve plánu (hledání indexu nemá potomka). Poté, co jste právě vytvořili objekt kontroly dotazu pro vyhledávání indexu, dalším krokem je zabalit kontrolu dotazu s třídou profilování (za předpokladu, že jsme požadovali skutečný plán). To se provádí voláním sqlmin!PqsWrapQScan . Všimněte si, že profilery se přidávají po vytvoření skenování dotazů, když začínáme stoupat stromem iterátoru.
PqsWrapQScan vytvoří nového operátora profilování jako rodič vyhledávání indexu prostřednictvím volání CProfileInfo::GetOrCreateProfileInfo . Operátor profilování (CQScanProfileNew ) má obvyklé metody rozhraní pro skenování dotazů. Kromě shromažďování údajů potřebných pro skutečné plány jsou data profilování také vystavena prostřednictvím sys.dm_exec_query_profiles DMV .
Dotaz na DMV v tomto přesném okamžiku pro aktuální relaci ukazuje, že existuje pouze jeden operátor plánu (uzel 9) (to znamená, že je jediný zabalený profilerem):

Tento snímek obrazovky ukazuje kompletní sadu výsledků z DMV v aktuálním okamžiku (nebyl upraven).
Další, CQScanProfileNew volá rozhraní API čítače výkonu dotazů (KERNEL32!QueryPerformanceCounterStub ) poskytované operačním systémem k zaznamenání prvního a posledního aktivního času profilovaného operátora:

Čas poslední aktivity budou aktualizovány pomocí rozhraní API čítače výkonu dotazů při každém spuštění kódu pro daný iterátor.
Profiler poté nastaví odhadovaný počet řádků v tomto bodě plánu (CProfileInfo::SetCardExpectedRows ), který zohledňuje jakýkoli cíl řádku (CXte::CardGetRowGoal ). Protože se jedná o paralelní plán, vydělí výsledek počtem vláken (CXte::FGetRowGoalDefinedForOneThread ) a uloží výsledek v kontextu provádění.
Odhadovaný počet řádků není viditelný přes DMV v tomto okamžiku, protože nadřazená úloha tento operátor neprovede. Místo toho bude odhad na vlákno vystaven později v kontextech paralelního provádění (které ještě nebyly vytvořeny). Číslo na vlákno je však uloženo v profilovači nadřazeného úkolu – pouze není viditelné prostřednictvím DMV.
Příjemný název operátora plánu („Index Seek“) se pak nastaví pomocí volání CXteRange::GetPhysicalOp :

Předtím jste si možná všimli, že dotazování DMV ukázalo jméno jako „???“. Toto je trvalý název zobrazovaný pro neviditelné operátory (např. předběžné načtení vnořených smyček, dávkové řazení), které nemají definovaný popisný název.
Nakonec indexujte metadata a aktuální I/O statistiky pro zalomené hledání indexu se přidávají pomocí volání CQScanRowsetNew::GetIoCounters :

Čítače jsou v tuto chvíli nulové, ale budou aktualizovány, když hledání indexu provede I/O během dokončeného provádění plánu.
Další zpracování skenování dotazů
S operátorem profilování vytvořeným pro hledání indexu se zpracování skenování dotazu přesune zpět ve stromu do nadřazeného třídění (uzel 7).
Třídění provádí následující inicializační úlohy:
- Zaregistruje využití paměti pomocí dotazu správce paměti (
CQryMemManager::RegisterMemUsage) - Vypočítá paměť potřebnou pro vstup řazení (
CQScanIndexSortNew::CbufInputMemory) a výstup (CQScanSortNew::CbufOutputMemory). - Třídicí tabulka je vytvořen spolu s přidruženou sadou řádků úložiště (
sqlmin!RowsetSorted). - Samostatná systémová transakce (není ohraničena uživatelskou transakcí) je vytvořena pro alokace disků pro třídění, spolu s falešnou pracovní tabulkou (
sqlmin!CreateFakeWorkTable). - Výrazová služba je inicializována (
sqlTsEs!CEsRuntime::Startup), aby operátor řazení provedl výpočty odloženy z výpočetního skaláru. - Předběžné načtení pro všechny běhy řazení přelité do tempdb se poté vytvoří pomocí (
CPrefetchMgr::SetupPrefetch).
Nakonec je skenování dotazu na řazení zabaleno operátorem profilování (včetně I/O), jak jsme viděli u hledání indexu:

Všimněte si, že výpočetní skalár (uzel 8) chybí z DMV. Je to proto, že jeho práce je odložena na třídění, není součástí stromu kontroly dotazů, a proto nemá žádný obalový profiler objektu.
Přesun nahoru k nadřazenému prvku řazení, agregaci proudu Operátor skenování dotazu (uzel 6) inicializuje své výrazy a čítače za běhu (např. aktuální počet řádků skupiny). Agregát streamu je zabalen s operátorem profilování, který zaznamenává jeho počáteční časy:

výměna proudů nadřazené přerozdělení (uzel 5) je zabalen profilerem (nezapomeňte, že v tuto chvíli existuje pouze spotřebitelská strana této výměny):

Totéž se provádí pro jeho nadřazený agregát streamů (uzel 4), který je také inicializován, jak bylo popsáno dříve:

Zpracování skenování dotazu se vrátí k nadřazenému sloučení spojení (uzel 3), ale ještě jej neinicializuje. Místo toho se přesuneme po vnitřní (spodní) straně slučovacího spojení a provedeme stejné podrobné úkoly pro tyto operátory (uzly 10 až 15) jako pro horní (vnější) větev:
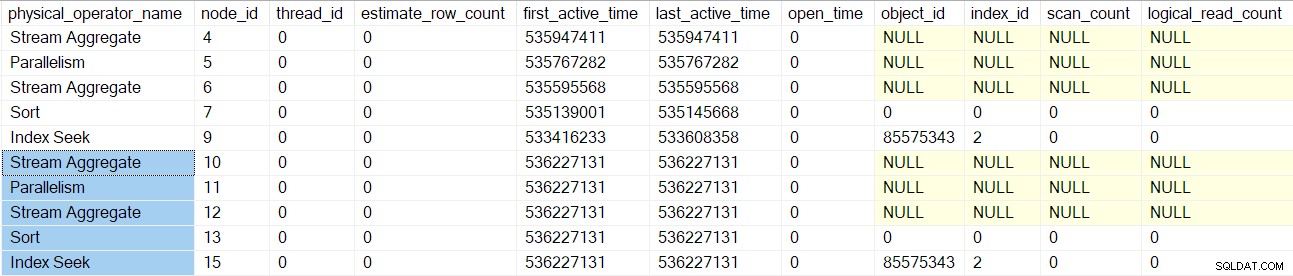
Jakmile jsou tyto operátory zpracovány, sloučení spojení kontrola dotazů je vytvořena, inicializována a zabalena s objektem profilování. To zahrnuje I/O čítače, protože mnoho-mnoho slučovacího spojení používá pracovní tabulku (i když aktuální slučovací spojení je jeden-mnoho):
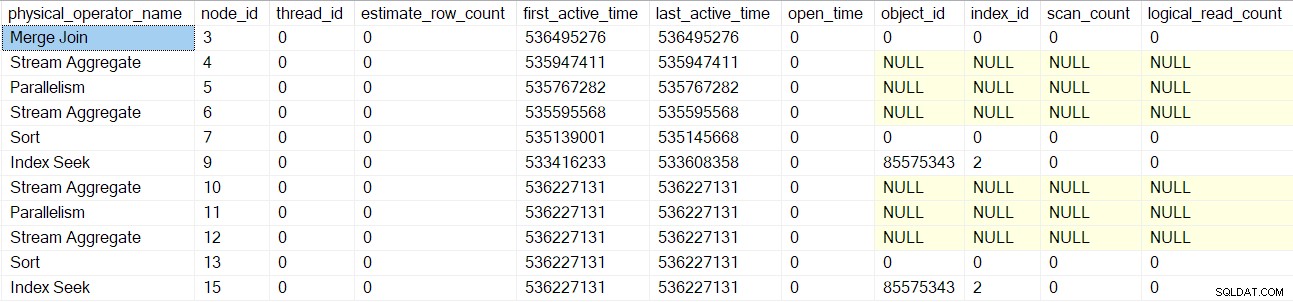
Stejný proces se použije pro výměnu nadřazených shromažďovacích proudů (uzel 2) pouze spotřebitelská strana, segment (uzel 1) a sekvenční projekt (uzel 0) operátory. Nebudu je podrobně popisovat.
Profily dotazů DMV nyní hlásí úplnou sadu uzlů skenování dotazů zabalených do profileru:
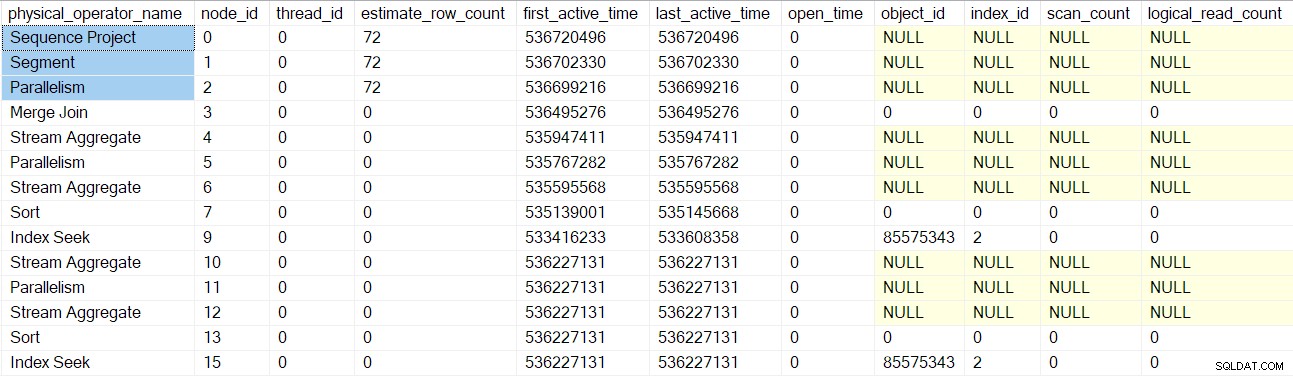
Všimněte si, že spotřebitel sekvenčního projektu, segmentu a sběru datových proudů má odhadovaný počet řádků, protože tyto operátory bude spouštět nadřazený úkol , nikoli pomocí dalších paralelních úloh (viz CXte::FGetRowGoalDefinedForOneThread dříve). Nadřazená úloha nemá žádnou práci v paralelních větvích, takže koncept odhadovaného počtu řádků má smysl pouze pro další úlohy.
Výše uvedené hodnoty aktivního času jsou poněkud zkreslené, protože jsem potřeboval zastavit provádění a pořídit snímky obrazovky DMV v každém kroku. Samostatné provedení (bez umělých zpoždění zavedených použitím debuggeru) přineslo následující načasování:
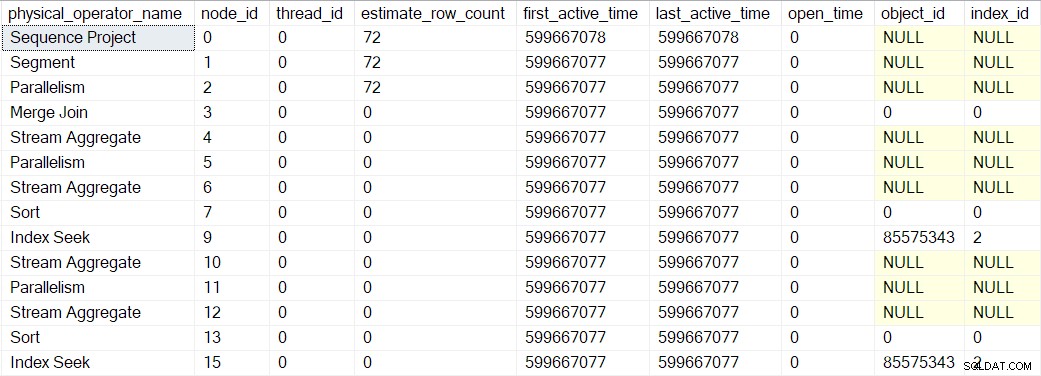
Strom je vytvořen ve stejném pořadí, jaké bylo popsáno výše, ale proces je tak rychlý, že trvá pouze 1 mikrosekundu rozdíl mezi aktivním časem prvního zabaleného operátora (hledání indexu v uzlu 9) a posledním (sekvenční projekt v uzlu 0).
Konec 2. části
Může to znít, jako bychom udělali hodně práce, ale nezapomeňte, že jsme vytvořili pouze strom kontroly dotazů pro nadřazený úkol a burzy mají pouze spotřebitelskou stranu (zatím žádný výrobce). Náš paralelní plán má také pouze jedno vlákno (jak je znázorněno na posledním snímku obrazovky). Ve 3. části budou vytvořeny naše první další paralelní úlohy.