Tento blog je stručnou prezentací o Jenkinsovi a ukazuje vám, jak tento nástroj používat, aby vám pomohl s některými z vašich každodenních úkolů správy a správy PostgreSQL.
O Jenkinsovi
Jenkins je open source software pro automatizaci. Je vyvinut v jazyce Java a je jedním z nejoblíbenějších nástrojů pro nepřetržitou integraci (CI) a nepřetržité doručování (CD).
V roce 2010, po akvizici Sun Microsystems společností Oracle, byl software „Hudson“ ve sporu s komunitou open source. Tento spor se stal základem pro spuštění projektu Jenkins.
V současnosti jsou „Hudson“ (veřejná licence Eclipse) a „Jenkins“ (licence MIT) dva aktivní a nezávislé projekty s velmi podobným účelem.
Jenkins má tisíce pluginů, které můžete použít k urychlení vývojové fáze prostřednictvím automatizace pro celý životní cyklus vývoje; sestavování, dokumentování, testování, balení, fáze a nasazení.
Co Jenkins dělá?
Ačkoli hlavním využitím Jenkins by mohla být nepřetržitá integrace (CI) a nepřetržité doručování (CD), tento otevřený zdroj má sadu funkcí a lze jej používat bez jakéhokoli závazku nebo závislosti na CI nebo CD, takže Jenkins představuje některé zajímavé funkce pro prozkoumat:
- Plánování úloh období (místo použití tradičního crontab )
- Sledování úloh, jejich protokolů a aktivit pomocí přehledného zobrazení (protože mají možnost seskupování)
- Údržbu pracovních míst lze provádět snadno; za předpokladu, že Jenkins má pro to sadu možností
- Nastavení a plánování instalace softwaru (pomocí Puppet) ve stejném hostiteli nebo v jiném.
- Publikování přehledů a zasílání e-mailových upozornění
Spouštění úloh PostgreSQL v Jenkins
Vývojář PostgreSQL nebo správce databáze musí každý den dělat tři běžné úkoly:
- Plánování a provádění skriptů PostgreSQL
- Provedení procesu PostgreSQL složeného ze tří nebo více skriptů
- Nepřetržitá integrace (CI) pro vývoj PL/pgSQL
Pro provedení těchto příkladů se předpokládá, že servery Jenkins a PostgreSQL (alespoň verze 9.5) jsou nainstalovány a fungují správně.
Plánování a spouštění skriptu PostgreSQL
Ve většině případů implementace denních (nebo periodicky) skriptů PostgreSQL pro provádění obvyklé úlohy, jako je...
- Generování záloh
- Otestujte obnovení zálohy
- Provedení dotazu pro účely vytváření přehledů
- Vyčištění a archivace souborů protokolu
- Volání procedury PL/pgSQL k vyčištění tabulek
t je definováno na crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shJako crontab není nejlepší uživatelsky přívětivý nástroj pro správu tohoto druhu plánování, lze jej provést na Jenkins s následujícími výhodami...
- Velmi přívětivé rozhraní pro sledování jejich postupu a aktuálního stavu
- Protokoly jsou okamžitě k dispozici a pro přístup k nim není třeba žádné zvláštní povolení
- Úlohu lze místo toho provést ručně na Jenkinsovi, aby bylo zajištěno plánování
- U některých typů úloh není třeba definovat uživatele a hesla v souborech s prostým textem, protože Jenkins to dělá bezpečným způsobem.
- Úlohy lze definovat jako spouštění rozhraní API
Takže by mohlo být dobrým řešením migrovat úlohy související s úlohami PostgreSQL na Jenkins místo crontab.
Na druhou stranu většina administrátorů a vývojářů databází má silné dovednosti ve skriptovacích jazycích a bylo by pro ně snadné vyvinout malá rozhraní, která by se s těmito skripty vypořádala, aby implementovali automatizované procesy s cílem zlepšit jejich úkoly. Pamatujte však, že Jenkins s největší pravděpodobností již má sadu funkcí, které to umožňují, a tyto funkce mohou usnadnit život vývojářům, kteří se je rozhodnou používat.
Pro definování provádění skriptu je tedy nutné vytvořit novou úlohu výběrem možnosti „Nová položka“.
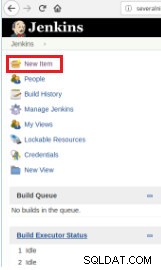 Obrázek 1 – "Nová položka" za účelem definování úlohy pro spuštění skriptu PostgreSQL
Obrázek 1 – "Nová položka" za účelem definování úlohy pro spuštění skriptu PostgreSQL Poté po jeho pojmenování vyberte typ „Projekty FreeStyle“ a klikněte na OK.
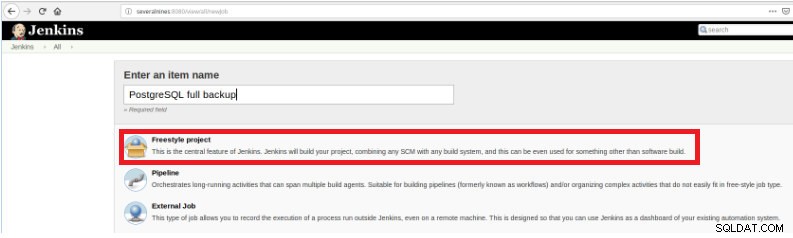 Obrázek 2 – Výběr typu zakázky (položky)
Obrázek 2 – Výběr typu zakázky (položky) Pro dokončení vytváření této nové úlohy musí být v sekci „Sestavit“ vybrána možnost „Spustit skript“ a v poli příkazového řádku cesta a parametrizace skriptu, který bude spuštěn:
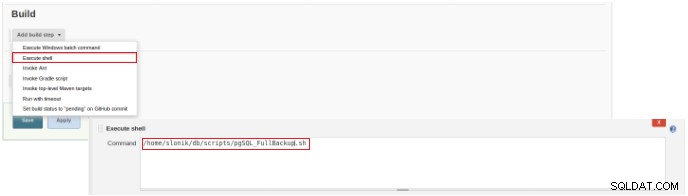 Obrázek 3 – Specifikace příkazu, který se má provést
Obrázek 3 – Specifikace příkazu, který se má provést Pro tento druh úlohy je vhodné ověřit oprávnění skriptu, protože musí být nastaveno alespoň spuštění pro skupinu, do které soubor patří, a pro všechny.
V tomto příkladu skript query.sh má oprávnění číst a spouštět pro všechny, číst a spouštět oprávnění pro skupinu a číst, zapisovat a spouštět pro uživatele:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Tento skript má velmi jednoduchou sadu příkazů, v podstatě pouze volá obslužný program psql za účelem provádění dotazů:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datProvádění procesu PostgreSQL složeného ze tří nebo více skriptů
V tomto příkladu popíšu, co potřebujete ke spuštění tří různých skriptů, abyste skryli citlivá data, a proto budeme postupovat podle níže uvedených kroků...
- Importujte data ze souborů
- Připravte data k maskování
- Záloha databáze s maskovanými daty
Takže pro definování této nové zakázky je nutné vybrat možnost „Nová položka“ na hlavní stránce Jenkins a poté, po přiřazení názvu, musí být vybrána možnost „Pipeline“:
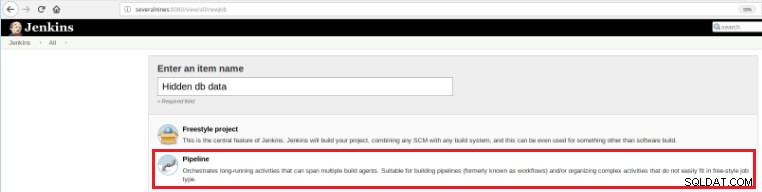 Obrázek 5 – Položka potrubí v Jenkins
Obrázek 5 – Položka potrubí v Jenkins Jakmile je úloha uložena v sekci „Pipeline“, na kartě „Pokročilé možnosti projektu“ musí být pole „Definice“ nastaveno na „Skript potrubí“, jak je znázorněno níže:
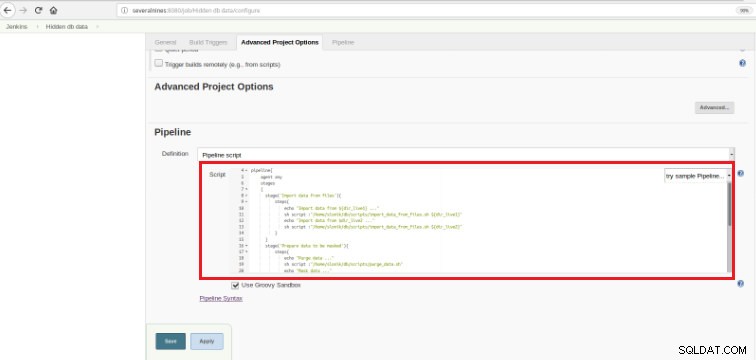 Obrázek 6 – Groovy skript v sekci kanálu
Obrázek 6 – Groovy skript v sekci kanálu Jak jsem zmínil na začátku kapitoly, použitý skript Groovy se skládá ze tří fází, to znamená tří odlišných částí (fází), jak je uvedeno v následujícím skriptu:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy je objektově orientovaný programovací jazyk kompatibilní se syntaxí Java pro platformu Java. Je to jak statický, tak dynamický jazyk s funkcemi podobnými těm z Pythonu, Ruby, Perlu a Smalltalku.
Je snadné to pochopit, protože tento druh skriptu je založen na několika příkazech…
Fáze
Znamená 3 procesy, které budou provedeny:„Importovat data ze souborů“, „Připravit data k maskování“
a „Zálohování databáze s maskovanými daty“.
Krok
„Krok“ (často nazývaný „krok sestavení“) je jediný úkol, který je součástí sekvence. Každá fáze se může skládat z několika kroků. V tomto příkladu má první fáze dva kroky.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Data jsou importována ze dvou různých zdrojů.
V předchozím příkladu je důležité poznamenat, že na začátku jsou definovány dvě proměnné s globálním rozsahem:
dir_live1
dir_live2Skripty použité v těchto třech krocích volají psql , pg_restore a pg_dump nástroje.
Jakmile je úloha definována, je čas ji provést a k tomu stačí kliknout na možnost „Vytvořit nyní“:
 Obrázek 7 – Prováděcí úloha
Obrázek 7 – Prováděcí úloha Po zahájení sestavování je možné ověřit jeho průběh.
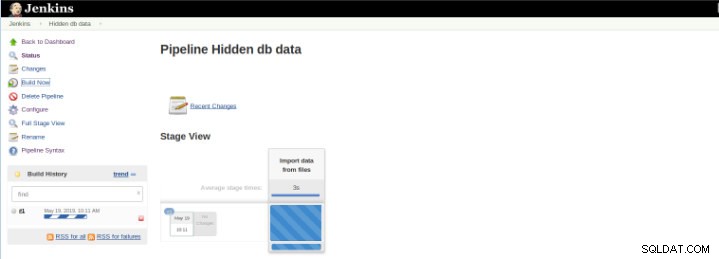 Obrázek 8 – Spuštění „Build“
Obrázek 8 – Spuštění „Build“ Zásuvný modul Pipeline Stage View obsahuje rozšířenou vizualizaci historie sestavení Pipeline na stránce indexu projektu toku pod Stage View. Toto zobrazení je vytvořeno, jakmile jsou úkoly dokončeny a každý úkol je reprezentován sloupcem zleva doprava a je možné zobrazit a porovnat uplynulý čas pro provádění služeb (známé jako Build in Jenkins).
Jakmile skončí provádění (také nazývané Build), je možné získat další podrobnosti kliknutím na dokončené vlákno (červené pole).
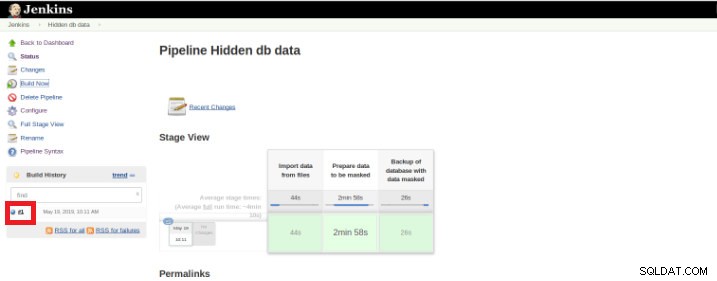 Obrázek 9 – Spuštění „Build“
Obrázek 9 – Spuštění „Build“ a poté ve volbě „Console Output“.
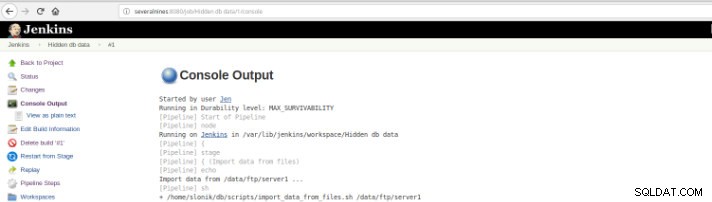 Obrázek 10 – Výstup na konzolu
Obrázek 10 – Výstup na konzolu Předchozí pohledy jsou extrémně užitečné, protože umožňují vnímat dobu běhu vyžadovanou pro každou fázi.
Pipelines, také známý jako workflow, je to plugin, který umožňuje definici životního cyklu aplikace a je to funkce používaná v Jenkins for Continuous delivery (CD). na mysli.
Tento příklad má za cíl skrýt citlivá data, ale určitě existuje mnoho dalších příkladů na denní bázi správce databáze PostgreSQL, které lze spustit na zřetězené úloze.
Pipeline je na Jenkins k dispozici od verze 2.0 a je to neuvěřitelné řešení!

Nepřetržitá integrace (CI) pro vývoj PL/pgSQL
Nepřetržitá integrace pro vývoj databáze není tak snadná jako v jiných programovacích jazycích kvůli datům, která mohou být ztracena, takže není snadné udržet databázi pod kontrolou zdroje a nasadit ji na vyhrazený server, zejména pokud jsou k dispozici skripty. které obsahují příkazy DDL (Data Definition Language) a DML (Data Manipulation Language). Je to proto, že tyto druhy příkazů upravují aktuální stav databáze a na rozdíl od jiných programovacích jazyků zde není třeba kompilovat zdrojový kód.
Na druhou stranu existuje sada databázových příkazů, u kterých je možná průběžná integrace jako u jiných programovacích jazyků.
Tento příklad je založen pouze na vývoji procedur a bude ilustrovat spouštění sady testů (napsaných v Pythonu) Jenkinsem, jakmile jsou skripty PostgreSQL, na kterých je uložen kód následujících funkcí, potvrzeny v úložišti kódu.
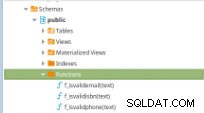 Obrázek 11 – Funkce PLpg/SQL
Obrázek 11 – Funkce PLpg/SQL Tyto funkce jsou jednoduché a jejich obsah má pouze několik logických prvků nebo dotazů v PLpg/SQL nebo plperlu jazyk jako funkce f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Všechny zde prezentované funkce na sobě nezávisí, a tak neexistuje žádná přednost ani v jeho vývoji, ani v jeho nasazení. Vzhledem k tomu, že to bude ověřeno předem, neexistuje žádná závislost na jejich ověření.
Aby bylo možné provést sadu ověřovacích skriptů po provedení potvrzení v úložišti kódu, je nutné vytvořit úlohu sestavení (nová položka) v Jenkins:
 Obrázek 12 – Projekt „Freestyle“ pro kontinuální integraci
Obrázek 12 – Projekt „Freestyle“ pro kontinuální integraci Tato nová úloha sestavení by měla být vytvořena jako projekt „Freestyle“ a v sekci „Úložiště zdrojového kódu“ musí být definována adresa URL úložiště a jeho přihlašovací údaje (oranžové pole):
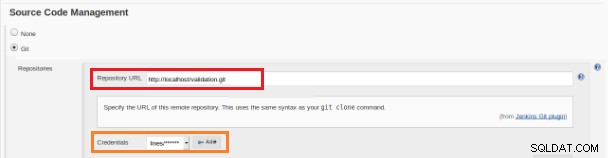 Obrázek 13 – Úložiště zdrojového kódu
Obrázek 13 – Úložiště zdrojového kódu V sekci "Build Triggers" musí být zaškrtnuta možnost "GitHub hook trigger for GITScm polling":
 Obrázek 14 – část „Sestavení spouštěčů“
Obrázek 14 – část „Sestavení spouštěčů“ Nakonec v sekci „Build“ musí být vybrána možnost „Execute Shell“ a v příkazovém poli skripty, které budou provádět validaci vyvinutých funkcí:
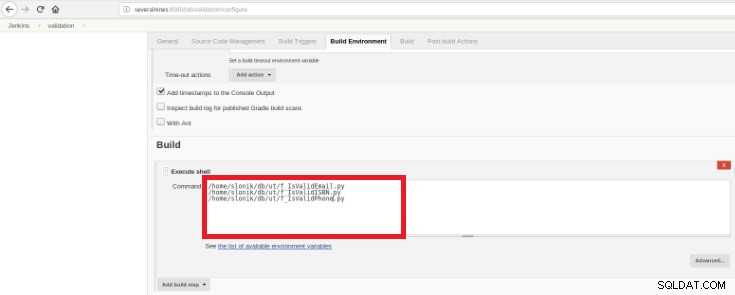 Obrázek 15 – část „Vytvořit prostředí“
Obrázek 15 – část „Vytvořit prostředí“ Účelem je mít jeden ověřovací skript pro každou vyvinutou funkci.
Tento skript Pythonu má jednoduchou sadu příkazů, které budou volat tyto procedury z databáze s některými předdefinovanými očekávanými výsledky:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Tento skript otestuje prezentované PLpg/SQL nebo plperlu funkce a bude spuštěn po každém potvrzení v úložišti kódu, aby se předešlo regresi vývoje.
Po provedení tohoto sestavení úlohy lze ověřit provedení protokolu.
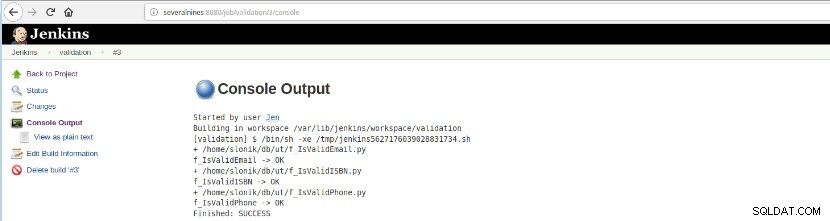 Obrázek 16 – „Výstup konzoly“
Obrázek 16 – „Výstup konzoly“ Tato volba představuje konečný stav:ÚSPĚCH nebo NEPŘESNĚNÍ, pracovní prostor, spuštěné soubory/skript, vytvořené dočasné soubory a chybové zprávy (pro ty neúspěšné)!
Závěr
Stručně řečeno, Jenkins je známý jako skvělý nástroj pro kontinuální integraci (CI) a kontinuální doručování (CD), lze jej však použít pro různé funkce, jako je,
- Plánování úkolů
- Provádění skriptů
- Monitorovací procesy
Pro všechny tyto účely lze u každé popravy (Build on Jenkinsův slovník) analyzovat protokoly a uplynulý čas.
Vzhledem k velkému počtu dostupných pluginů by se mohlo vyhnout nějakému vývoji s konkrétním cílem, pravděpodobně existuje plugin, který dělá přesně to, co hledáte, stačí prohledat centrum aktualizací nebo Spravovat Jenkins>>Spravovat pluginy uvnitř webové aplikace.