Tak jsme tu. Téměř dvě desetiletí do 21. století a potřeba většího výpočetního výkonu je stále problémem. Technologické společnosti buší na chodník, aby se s tímto masivním problémem vypořádaly přímo. Hardwaroví inženýři našli řešení změnou způsobu, jakým navrhují a vyrábějí centrální procesorovou jednotku (CPU) počítače. Nyní obsahují více jader, což umožňuje souběžnost. Vývojáři softwaru zase upravili způsob psaní programů, aby se přizpůsobili této změně hardwaru.
Komunita PostgreSQL plně využila těchto vícejádrových CPU ke zlepšení výkonu dotazů. Pouhou aktualizací na verzi 9.6 nebo vyšší můžete využít funkci zvanou paralelismus dotazů k provádění různých operací. Rozděluje úkoly na menší části a každý úkol rozkládá na více jader CPU. Každé jádro může zpracovávat úkoly současně. Vzhledem k hardwarovým omezením je to jediný způsob, jak zlepšit výkon počítače v budoucnosti.
Před použitím funkce paralelismu v databázi PostgreSQL je nezbytné rozpoznat, jak dělá dotaz paralelním. Budete moci ladit a řešit jakékoli problémy, které nastanou.
Jak funguje paralelismus dotazů?
Chcete-li lépe porozumět tomu, jak se paralelismus provádí, je dobré začít na úrovni klienta. Pro přístup k PostgreSQL musí klient odeslat požadavek na připojení na databázový server s názvem postmaster. Postmaster dokončí autentizaci a poté pro každé připojení vytvoří nový serverový proces. Je také zodpovědný za vytvoření oblasti sdílené paměti, která obsahuje oblast vyrovnávacích pamětí. Oblast vyrovnávací paměti dohlíží na přenos dat mezi sdílenou pamětí a úložištěm. Proto ve chvíli, kdy je navázáno spojení, zásobník vyrovnávací paměti přenese data a umožní paralelismus dotazů.
Není nutné, aby byly všechny dotazy paralelní. Existují případy, kdy je potřeba jen malé množství dat a může je rychle zpracovat pouze jedno jádro. Tato funkce se používá pouze v případě, že dokončení dotazu zabere značné množství času. Optimalizátor databáze určuje, zda se má provést paralelismus. Pokud je to nutné, databáze použije další část paměti nazývanou dynamická sdílená paměť (DSM). To umožňuje vedoucímu procesu a paralelním pracovním procesům rozdělit dotaz mezi více jader a shromáždit příslušná data.
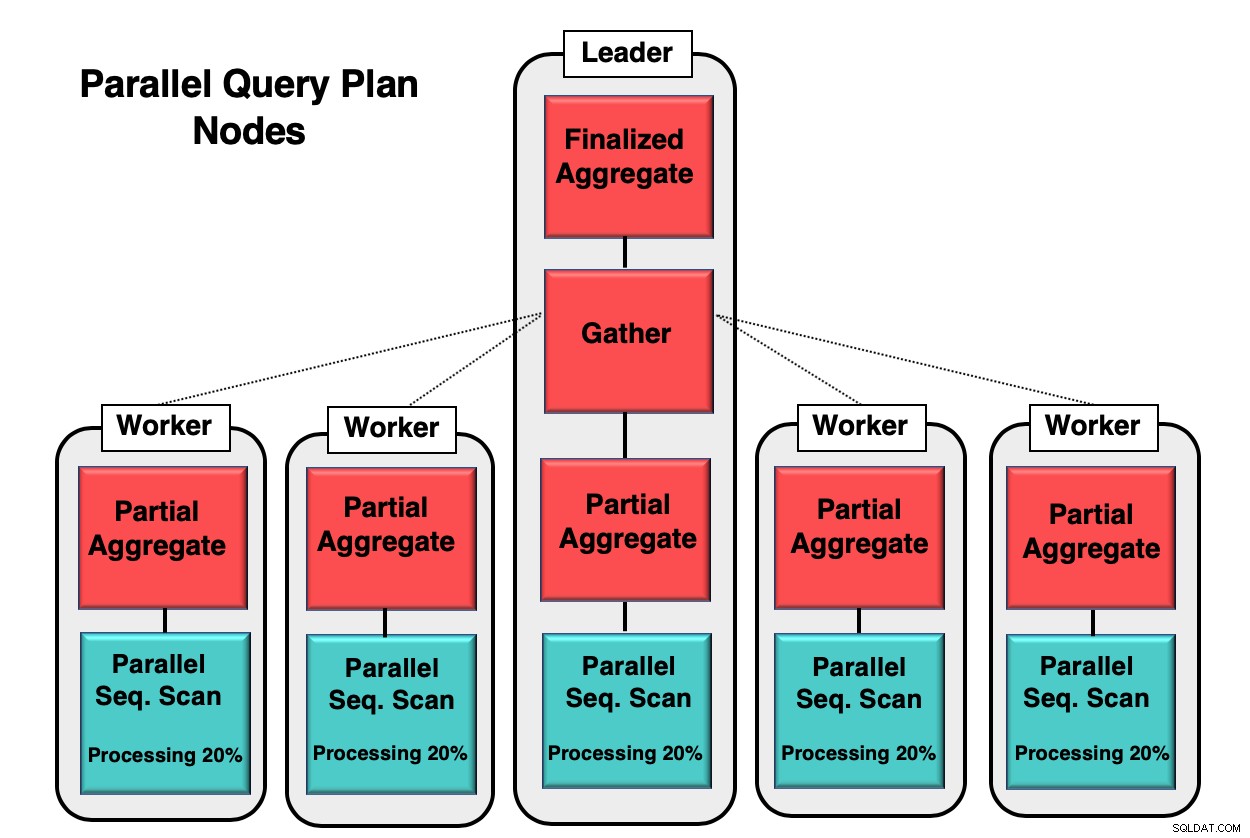
Obrázek 1 ukazuje příklad toho, jak probíhá paralelismus uvnitř databáze. Vedoucí proces spustí počáteční dotaz, zatímco jednotlivé pracovní procesy zahájí kopii stejného procesu. Částečný agregovaný uzel neboli jádro CPU je zodpovědný za implementaci paralelního sekvenčního skenování databázové tabulky.
V tomto případě každý uzel sekvenčního skenování zpracovává 20 % dat v blocích o velikosti 8 kb. Tyto stejné uzly mohou koordinovat svou činnost pomocí techniky zvané paralelní vědomí. Každý uzel má plnou znalost o tom, jaká data již byla zpracována a která data je třeba pro dokončení dotazu naskenovat v tabulce. Jakmile jsou n-tice shromážděny v plném rozsahu, jsou odeslány do shromažďovacího uzlu ke kompilaci a finalizaci.
Paralelní operace
Různé typy dotazů lze použít k načtení dat z databáze za účelem vytvoření sad výsledků. Zde jsou konkrétní operace, které vám dávají možnost efektivně využít více jader.
Sekvenční skenování
Tato operace čte data v tabulce od začátku do konce, aby shromáždila data. Rovnoměrně rozděluje zátěž mezi více jader, aby se zvýšila rychlost zpracování dotazů. Je si vědom každé aktivity jader, takže je snazší určit, zda byl dokončen celý dotaz. Uzel shromažďování pak obdrží data extrahovaná na základě dotazu.
Agregace
Standardní operace, která bere velké množství dat a zhušťuje je do menšího počtu řádků. To se děje během paralelního zpracování pouze extrahováním z tabulky nebo indexů příslušných informací na základě dotazu. Provedení průměru konkrétních dat je vynikajícím příkladem agregace.
Hash Join
Technika, která se používá ke spojení dat mezi dvěma tabulkami. Je to nejrychlejší spojovací algoritmus, který se obvykle provádí s malým stolem a velkým stolem. Nejprve vytvoříte hashovací tabulku a načtete do ní všechna data z jedné tabulky. Poté můžete skenovat všechna data z hash a druhé tabulky pomocí paralelního sekvenčního skenování. Každá n-tice, která je extrahována ze skenování, je porovnána s hashovací tabulkou, aby se zjistilo, zda existuje shoda. Pokud je identifikována shoda, data se spojí. S vydáním PostgreSQL 11 zabere použití paralelismu k dokončení spojení hash asi jednu třetinu předchozího času zpracování.
Sloučit připojení
Pokud optimalizátor zjistí, že hašovací spojení překročí kapacitu paměti, provede místo toho slučovací spojení. Proces zahrnuje procházení dvou seřazených seznamů současně a spojování stejných prvků. Pokud se položky neshodují, data nebudou spojena.
Připojení vnořené smyčky
Tato operace se používá, když jste museli spojit dvě tabulky obsahující různé programovací jazyky, jako je Quick Basic, Python atd. Každá tabulka je skenována a zpracovávána pomocí více jader. Pokud se data shodují, jsou odeslána do sběrného uzlu, aby se připojili. Indexy jsou také skenovány, což je důvod, proč tento proces obsahuje více smyček pro načtení dat. V průměru bude dokončení spojení pomocí paralelního procesu trvat pouze jednu třetinu času.
Skenování indexu B-stromu
Tato operace prohledává strom seřazených dat, aby nalezla konkrétní informace. Tento proces trvá déle než typické sekvenční skenování, protože při hledání záznamů se hodně čeká. Práce na skenování příslušných dat je však rozdělena mezi více procesorů.
Bitmapové skenování haldy
Pomocí této operace můžete sloučit více indexů. Nejprve chcete vytvořit ekvivalentní počet bitmap, protože máte indexy. Pokud máte například tři indexy, musíte nejprve vytvořit tři bitmapy. Každá bitmapa načte a zkompiluje n-tice na základě dotazu.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperParalelismus oddílů
Existuje další forma paralelismu, která se může odehrávat v databázi PostgreSQL. Nepochází však ze skenování tabulek a rozdělování úkolů. Data můžete rozdělit nebo rozdělit podle konkrétních hodnot. Můžete například vzít kupující hodnoty a nechat jedno jádro zpracovat data pouze v rámci této hodnoty. Tímto způsobem přesně víte, co každé jádro v daném okamžiku zpracovává.
Hash Partitioning
Tato operace se používá k rozložení řádků tabulky do podtabulek. Opět platí, že dělení je obecně určeno odlišnou hodnotou nebo seznamem hodnot z tabulky. Toto je vynikající metoda, kterou můžete použít, pokud nemáte efektivní techniku správy úložiště na všech svých zařízeních. Chcete-li náhodně distribuovat data, abyste zabránili úzkým místům I/O, budete chtít použít rozdělení.
Připojení podle oddílu
Technika používaná k rozdělení tabulek podle oddílů a jejich spojování pomocí přiřazování podobných oddílů. Můžete mít například velkou tabulku kupujících z celých Spojených států. Nejprve můžete tabulku rozdělit podle různých měst a poté některá města spojit podle regionu v každém státě. Spojení podle oddílů zjednodušuje vaše data a umožňuje manipulaci s tabulkami.
Paralelně nebezpečné
PostgreSQL 11 automaticky spustí paralelismus dotazů, pokud optimalizátor určí, že je to nejrychlejší způsob dokončení dotazu. Čím vyšší verzi PostgreSQL používáte, tím více paralelních schopností bude mít vaše databáze. Bohužel ne všechny dotazy by měly být prováděny paralelně, i když to má schopnost. Typ dotazu, který provádíte, může mít specifická omezení a bude vyžadovat, aby veškeré zpracování dokončilo pouze jedno jádro. To zpomalí výkon vašeho systému, ale zaručí, že přijatá data jsou celistvá.
Aby bylo zajištěno, že vaše dotazy nebudou nikdy ohroženy, vývojáři vytvořili funkci nazvanou paralelní nebezpečný. Optimalizátor databáze a požadavek, aby dotaz nikdy nebyl paralelní, můžete ručně přepsat. Proces paralelismu nebude proveden.
Paralelnost v rámci databáze PostgreSQL je funkce, která se s každou verzí databáze pouze zlepšuje. I když je budoucnost technologie nejistá, zdá se, že používání této funkce zde zůstane.
Pro více informací se můžete podívat na následující...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table