Odpověď bude samozřejmě „to záleží“, ale na základě testování tohoto konce...
Za předpokladu
- 1 milion produktů
productmá seskupený index naproduct_id- Většina produktů (pokud ne všechny) má odpovídající informace v
product_codestůl - Ideální indexy obsažené v
product_codepro oba dotazy.
PIVOT verze v ideálním případě potřebuje index product_code(product_id, type) INCLUDE (code) zatímco JOIN verze v ideálním případě potřebuje index product_code(type,product_id) INCLUDE (code)
Pokud jsou na místě, uveďte níže uvedené plány
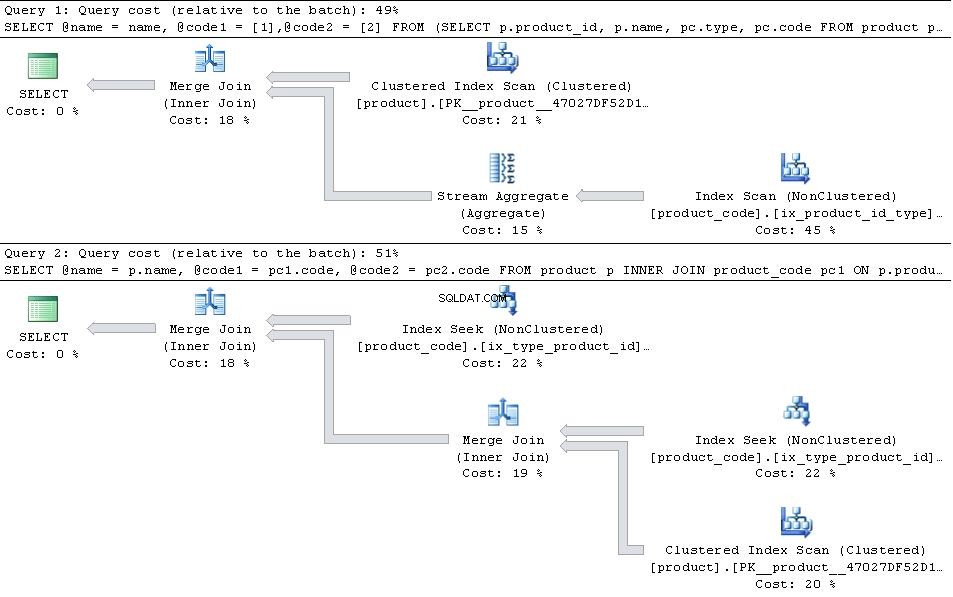
poté JOIN verze je efektivnější.
V případě, že type 1 a type 2 jsou jediné types v tabulce pak PIVOT verze má mírně náskok, pokud jde o počet přečtení, protože nemusí hledat product_code dvakrát, ale to je více než vyváženo dodatečnou režií operátora agregátu streamů
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
PŘIPOJIT SE
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Pokud existují další type záznamy jiné než 1 a 2 JOIN verze zvýší svou výhodu, protože pouze sloučí spojení v příslušných sekcích type,product_id index, zatímco PIVOT plán používá product_id, type a tak by musel prohledat další type řádky, které se prolínají s 1 a 2 řádky.