Před několika týdny jsem začal konfigurovat demo prostředí s několika konfiguracemi AlwaysOn Availability Groups. Měl jsem cluster WSFC s 5 uzly – každý uzel měl samostatnou pojmenovanou instanci SQL Server 2012 a byly zde také dvě instance clusteru s podporou převzetí služeb při selhání (FCI), které byly nastaveny nad těmito uzly. Rychlý diagram:
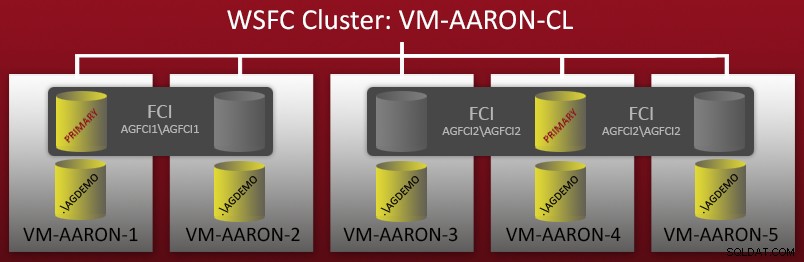
Takže můžete vidět, že existuje 5 samostatných pojmenovaných instancí (.\AGDEMO na každém uzlu) a poté dva FCI – jeden s možnými vlastníky VM-AARON-1 a VM-AARON-2 (AGFCI1\AGFCI1 ) a poté jeden s možnými vlastníky VM-AARON-3, VM-AARON-4 a VM-AARON-5 (AGFCI2\AGFCI2 ). Ruční vytváření diagramů by muselo být podstatně složitější (o tom později), takže se tomu ze zřejmých důvodů vyhnu. V podstatě bylo požadováno mít více typů konfigurací AG:
- Primární na FCI s replikou na jedné nebo více samostatných instancích
- Primární na FCI s replikou na jiném FCI
- Primární na samostatné instanci s replikou na jednom nebo více FCI
- Primární na samostatné instanci s replikou na jedné nebo více samostatných instancích
- Primární na samostatné instanci s replikami na samostatných instancích i FCI
A pak kombinace (kde je to možné) synchronního vs. asynchronního potvrzení, ručního vs. automatického převzetí služeb při selhání a sekundárních položek pouze pro čtení. Existují určitá technická omezení, která by omezovala zde možné permutace, například:
- Manuální převzetí služeb při selhání je nutné u každé repliky, která je na FCI
- Žádný uzel WSFC nemůže hostit – ani být možným vlastníkem – více instancí, ať už samostatných nebo klastrovaných, které jsou součástí stejné skupiny dostupnosti. Zobrazí se tato chybová zpráva:Nepodařilo se vytvořit, připojit se nebo přidat repliku do skupiny dostupnosti 'MyGroup', protože uzel 'VM-AARON-1' je možným vlastníkem pro repliku 'AGFCI1\AGFCI1' i 'VM-AARON-1\ AGDEMO'. Pokud je jedna replika instancí clusteru s podporou převzetí služeb při selhání, odeberte překrývající se uzel od jeho možných vlastníků a zkuste to znovu. (Microsoft SQL Server, chyba:19405)
Většina scénářů, které jsem se snažil znázornit, není praktická ve scénářích reálného světa, ale jsou z velké části a teoreticky možné . Pokud jste to dosud neuhádli, toto prostředí se nastavuje výslovně za účelem testování nových funkcí kolem skupin dostupnosti, které plánujeme nabídnout v budoucí verzi SQL Sentry. Některé z těchto technologií jsme nahlédli během naší keynote s Fusion-io na nedávné konferenci SQL Intersection v Las Vegas.
Překážka č. 1
Nastavení skupin dostupnosti pomocí průvodce v SSMS je docela snadné. Pokud například nemáte heterogenní cesty k souborům. Průvodce má ověření, které zajišťuje, že na všech replikách existují stejná data a cesty protokolu. To může být nepříjemné, pokud používáte výchozí datovou cestu pro dvě různé pojmenované instance nebo pokud máte různé konfigurace písmen jednotky (což se často stává, když se jedná o FCI).
Kontrola kompatibility umístění databázového souboru na sekundární replice vedla k chybě. (Microsoft.SqlServer.Management.HadrTasks)Na instanci serveru, která hostí sekundární repliku VM-AARON-1\AGDEMO, neexistují následující umístění složek:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Nyní by mělo být samozřejmé, že tento scénář nechcete nastavit v žádném prostředí, které musí obstát ve zkoušce času. Věci půjdou na jih velmi rychle, pokud například později přidáte nový soubor do jedné z databází. Ale pokud jde o testovací / demo prostředí, proof of concept nebo prostředí, u kterého očekáváte, že bude stabilní po značnou dobu, nezoufejte:stále to můžete udělat bez průvodce.
Bohužel, aby se přidala urážka ke zranění, průvodce vás nenechá naskriptovat. Chybu ověření nemůžete přejít a neexistuje žádný Script tlačítko:
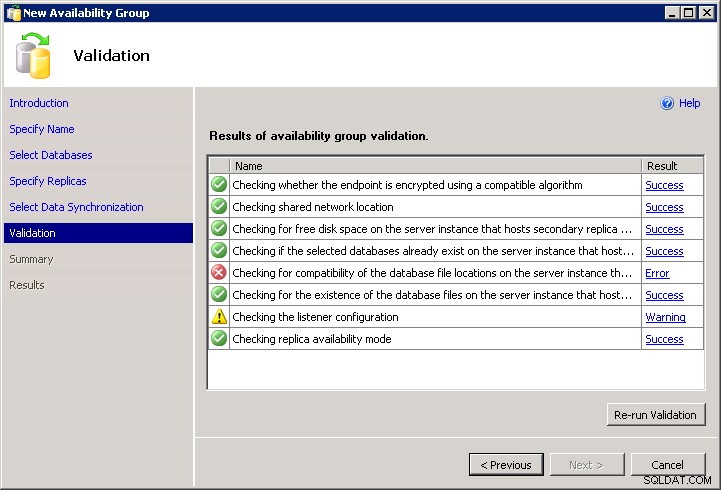
To znamená, že jej musíte nakódovat sami (protože DDL za vás neprovádí žádné „užitečné“ ověření). Pokud máte další instance, kde existují stejné cesty, můžete to provést pomocí stejného průvodce, přes ověřovací obrazovku a kliknutím na Script místo Finish a změňte název (názvy) serveru a přidejte pomocí WITH MOVE možnosti pro počáteční obnovení. Nebo můžete napsat svůj vlastní od začátku, něco takového (skript předpokládá, že již máte nakonfigurované koncové body a oprávnění a všechny instance mají povolenou funkci Skupiny dostupnosti):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Překážka č. 2
Pokud máte více instancí na stejném serveru, můžete zjistit, že obě instance nemohou sdílet port 5022 pro svůj koncový bod zrcadlení databáze (což je stejný koncový bod, který používají skupiny dostupnosti). To znamená, že budete muset zrušit a znovu vytvořit koncový bod, abyste jej místo toho nastavili na dostupný port.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Nyní bych mohl zadat instanci s koncovým bodem na ServerName:5023 .
Překážka č. 3
Jakmile jsem to však udělal, když jsem se dostal k poslednímu kroku výše uvedeného skriptu, přesně po 48 sekundách – pokaždé – se mi zobrazila tato neužitečná chybová zpráva:
Msg 35250, Level 16, State 7, Line 2Připojení k primární replice není aktivní. Příkaz nelze zpracovat.
To mě přimělo pronásledovat všechny druhy potenciálních problémů – například kontrolovat brány firewall a SQL Server Configuration Manager, zda neobsahují nic, co by blokovalo porty mezi instancemi. Nada. V protokolu chyb SQL Serveru jsem našel různé chyby:
Pokus o přihlášení k databázi Mirroring se nezdařil s chybou:'Navázání spojení se nezdařilo. Neexistuje žádný kompatibilní šifrovací algoritmus. Stav 22.'.Pokus o přihlášení k databázi Mirroring se nezdařil s chybou:'Navázání spojení se nezdařilo. Volání OS se nezdařilo:(80090303) 0x80090303 (Zadaný cíl je neznámý nebo nedostupný). Stav 66.'.
Při pokusu o navázání připojení k replikě dostupnosti 'VM-AARON-1\AGDEMO' s id [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0] vypršel časový limit připojení. Buď existuje problém se sítí nebo firewallem, nebo adresa koncového bodu poskytnutá pro repliku není koncovým bodem zrcadlení databáze instance hostitelského serveru.
Ukázalo se (a díky Thomasi Stringerovi (@SQLife)), že tento problém byl způsoben kombinací příznaků:(a) Kerberos nebyl správně nastaven a (b) šifrovací algoritmus pro hadr_endpoint, který jsem vytvořil, je výchozí. na RC4. To by bylo v pořádku, kdyby všechny samostatné instance také používaly RC4, ale nepoužívaly. Stručně řečeno, upustil jsem a znovu vytvořil koncové body znovu , ve všech případech. Protože se jednalo o laboratorní prostředí a podporu Kerberos jsem ve skutečnosti nepotřeboval (a protože jsem do těchto problémů již investoval dost času, takže jsem nechtěl řešit problémy s Kerberos také), nastavil jsem všechny koncové body pro použití Negotiate AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) nedávno také blogoval o podobném problému.)
Nyní se mi konečně podařilo vytvořit skupiny dostupnosti se všemi různými požadavky, které jsem měl, mezi uzly s heterogenními cestami k souborům a s využitím více instancí na stejném uzlu (jen ne ve stejné skupině). Zde je pohled na to, jak bude vypadat jedno z našich zobrazení AlwaysOn Management (kliknutím zvětšíte pro mnohem lepší přehled):
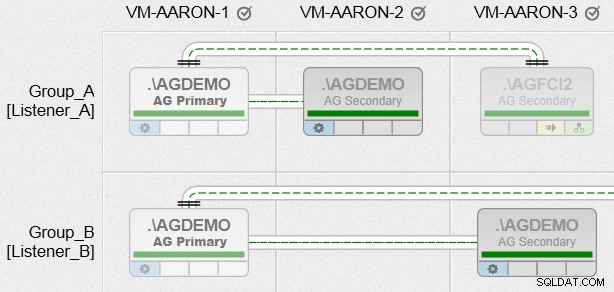
Teď je to jen trochu škádlení a je to zcela záměrné. V nadcházejících týdnech budu blogovat více o této funkci!
Závěr
Když se dostatečně dlouho díváte na problém, můžete přehlédnout některé docela zřejmé věci. V tomto případě byly některé zjevné problémy skryté v některých vyloženě neintuitivních chybových zprávách. Chci poděkovat Joe Sackovi (@JosephSack), Allanovi Hirtovi (@SQLHA) a Thomasi Stringerovi (@SQLife) za to, že se vzdali všeho, aby pomohli členovi komunity v nouzi.