"Ale na našem vývojovém serveru to běželo dobře!"
Kolikrát jsem to slyšel, když se tu a tam vyskytly problémy s výkonem dotazu SQL? Sám jsem to tenkrát řekl. Předpokládal jsem, že dotaz spuštěný za méně než sekundu bude na produkčních serverech fungovat dobře. Ale mýlil jsem se.
Dokážete se ztotožnit s touto zkušeností? Pokud jste dnes z jakéhokoli důvodu na této lodi, tento příspěvek je pro vás. Poskytne vám lepší metriku pro doladění výkonu vašich dotazů SQL. Budeme hovořit o třech nejkritičtějších číslech ve STATISTICS IO.
Jako příklad použijeme vzorovou databázi AdventureWorks.
Než začnete spouštět dotazy níže, zapněte STATISTICS IO. Zde je návod, jak to udělat v okně dotazu:
USE AdventureWorks
GO
SET STATISTICS IO ONJakmile spustíte dotaz se STATISTICS IO ON, objeví se různé zprávy. Můžete je vidět na kartě Zprávy v okně dotazu v SQL Server Management Studio (viz obrázek 1):
Nyní, když jsme skončili s krátkým úvodem, pojďme se ponořit hlouběji.
1. Vysoké logické čtení
Prvním bodem v našem seznamu je nejčastější viník – vysoké logické čtení.
Logická čtení jsou počet stránek přečtených z mezipaměti dat. Jedna stránka má velikost 8 kB. Datová mezipaměť na druhé straně odkazuje na RAM používanou SQL Serverem.
Logická čtení jsou zásadní pro ladění výkonu. Tento faktor definuje, kolik SQL Server potřebuje k vytvoření požadované sady výsledků. Jediná věc, kterou je třeba si zapamatovat, je tedy:čím vyšší jsou logická čtení, tím déle potřebuje SQL Server fungovat. Znamená to, že váš dotaz bude pomalejší. Snižte počet logických čtení a zvýšíte výkon dotazů.
Ale proč používat logické čtení místo uplynulého času?
- Uplynulá doba závisí na dalších věcech provedených serverem, nejen na vašem dotazu samotném.
- Uplynulý čas se může změnit z vývojového serveru na produkční server. K tomu dochází, když mají oba servery různé kapacity a konfigurace hardwaru a softwaru.
Spoléháte-li se na uplynulý čas, budete si říkat:"Ale na našem vývojovém serveru to běželo dobře!" dříve nebo později.
Proč používat logické čtení místo fyzického čtení?
- Fyzická čtení představují počet stránek přečtených z disků do mezipaměti dat (v paměti). Jakmile jsou stránky potřebné v dotazu v mezipaměti dat, není třeba je znovu číst z disků.
- Když je stejný dotaz spuštěn znovu, fyzické čtení bude nulové.
Logická čtení jsou logickou volbou pro doladění výkonu dotazů SQL.
Abyste to viděli v praxi, pojďme na příklad.
Příklad logického čtení
Předpokládejme, že potřebujete získat seznam zákazníků s objednávkami odeslanými loni 11. července 2011. Níže najdete velmi jednoduchý dotaz:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'je to přímočaré. Tento dotaz bude mít následující výstup:

Potom zkontrolujte výsledek STATISTICS IO tohoto dotazu:

Výstup zobrazuje logická čtení každé ze čtyř tabulek použitých v dotazu. Celkem je součet logických čtení 729. Můžete také vidět fyzické čtení s celkovým součtem 21. Zkuste však znovu spustit dotaz a bude nula.
Podívejte se blíže na logické čtení SalesOrderHeader . Zajímá vás, proč má 689 logických čtení? Možná vás napadlo prohlédnout si níže uvedený plán provádění dotazu:
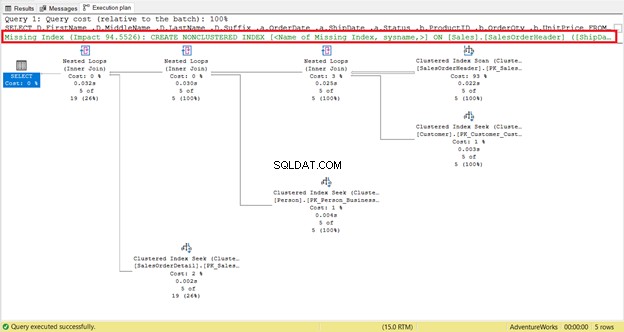
Za prvé, v SalesOrderHeader došlo ke skenování indexu s 93% náklady. Co by se mohlo stát? Předpokládejme, že jste zkontrolovali jeho vlastnosti:
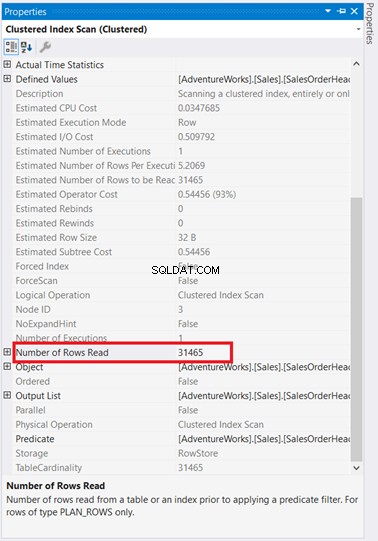
Páni! Bylo vráceno 31 465 přečtených řádků pouze pro 5 řádků? Je to absurdní!
Snížení počtu logických čtení
Zmenšit těch 31 465 přečtených řádků není tak těžké. SQL Server nám již napověděl. Pokračujte následujícím způsobem:
KROK 1:Postupujte podle doporučení serveru SQL Server a přidejte chybějící index
Všimli jste si chybějícího doporučení indexu v plánu provádění (obrázek 4)? Vyřeší to problém?
Existuje jeden způsob, jak to zjistit:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Spusťte dotaz znovu a podívejte se na změny v logických čteních STATISTICS IO.

Jak můžete vidět ve STATISTICS IO (obrázek 6), došlo k obrovskému poklesu logických čtení z 689 na 17. Nové celkové logické čtení je 57, což je výrazné zlepšení oproti 729 logickým čtením. Ale pro jistotu si znovu prohlédněme plán provádění.
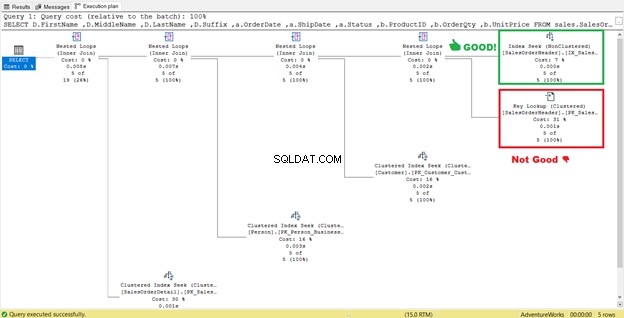
Vypadá to, že došlo ke zlepšení plánu, což má za následek snížení logického čtení. Skenování indexu je nyní hledáním indexu. SQL Server již nebude muset kontrolovat řádek po řádku, aby získal záznamy s Shipdate=’07/11/2011′ . Ale v tom plánu stále něco číhá a není to správné.
Potřebujete krok 2.
KROK 2:Změňte index a přidejte do zahrnutých sloupců:Datum objednávky, Stav a ID zákazníka
Vidíte operátora vyhledávání klíčů v plánu provádění (obrázek 7)? Znamená to, že vytvořený neklastrovaný index nestačí – dotazovací procesor musí znovu použít seskupený index.
Pojďme zkontrolovat jeho vlastnosti.
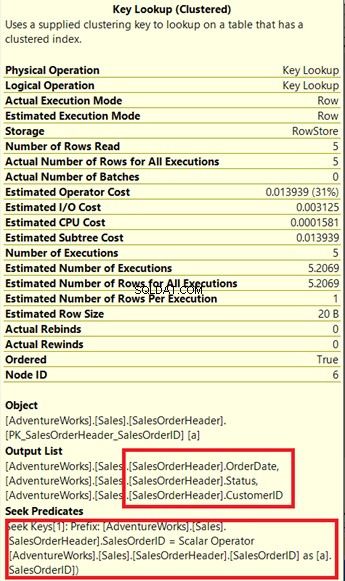
Všimněte si přiloženého pole pod Seznamem výstupů . Stává se, že potřebujeme Datum objednávky , Stav a CustomerID ve výsledkové sadě. K získání těchto hodnot použil procesor dotazů seskupený index (viz Hledat predikáty ), abyste se dostali ke stolu.
Musíme odstranit to vyhledávání klíčů. Řešením je zahrnout Datum objednávky , Stav a CustomerID sloupců do indexu vytvořeného dříve.
- Klikněte pravým tlačítkem na IX_SalesOrderHeader_ShipDate v SSMS.
- Vyberte Vlastnosti .
- Klikněte na Zahrnuté sloupce tab.
- Přidejte Datum objednávky , Stav a CustomerID .
- Klikněte na tlačítko OK .
Po opětovném vytvoření indexu spusťte dotaz znovu. Odebere to Vyhledávání klíčů a omezit logické čtení?

Fungovalo to! Od 17 logických čtení dolů na 2 (obrázek 9).
A Vyhledání klíčů ?
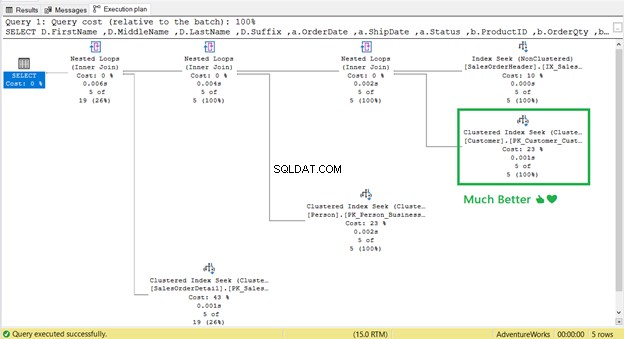
Je to pryč! Hledání seskupeného indexu nahradil Key Lookup.
Stávka s sebou
Takže, co jsme se naučili?
Jedním z primárních způsobů, jak omezit logické čtení a zlepšit výkon dotazů SQL, je vytvořit vhodný index. Má to ale háček. V našem příkladu to omezilo logické čtení. Někdy bude opak pravdou. Může také ovlivnit výkon dalších souvisejících dotazů.
Po vytvoření indexu proto vždy zkontrolujte STATISTICS IO a plán provádění.
2. High Lob Logical Reads
Je to v podstatě stejné jako bod #1, ale bude se zabývat datovými typy text , ntext , obrázek , varchar (max. ), nvarchar (max. ), varbinární (max. ), nebo columnstore indexové stránky.
Podívejme se na příklad:generování logických čtení lob.
Příklad logických čtení Lob
Předpokládejme, že chcete na webové stránce zobrazit produkt s jeho cenou, barvou, miniaturou a větším obrázkem. Proto přijdete s počátečním dotazem, jak je znázorněno níže:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorPoté jej spustíte a uvidíte výstup jako ten níže:

Protože jste tak výkonně smýšlející chlap (nebo dívka), okamžitě zkontrolujete STATISTICS IO. Tady to je:

Cítíte se jako nějaká špína v očích. 665 logických čtení? To nemůžete přijmout. Nemluvě o 194 logických přečtení každého z ProductPhoto a ProductProductPhoto tabulky. Opravdu si myslíte, že tento dotaz potřebuje nějaké změny.
Snížení počtu logických čtení Lob
Předchozí dotaz měl vráceno 97 řádků. Všech 97 kol. Myslíte si, že je dobré toto zobrazovat na webové stránce?
Index může pomoci, ale proč nejprve nezjednodušit dotaz? Tímto způsobem si můžete vybrat, co SQL Server vrátí. Můžete snížit počet logických čtení.
- Přidejte filtr pro podkategorii produktu a nechte zákazníka vybrat. Pak to zahrňte do klauzule WHERE.
- Odeberte Podkategorii produktu protože přidáte filtr pro podkategorii produktu.
- Odeberte Velkou fotku sloupec. Dotazujte se, když uživatel vybere konkrétní produkt.
- Používejte stránkování. Zákazník nebude moci zobrazit všech 97 kol najednou.
Na základě těchto výše popsaných operací změníme dotaz následovně:
- Odeberte ProductSubcategory a Velká fotografie sloupců ze sady výsledků.
- Použijte OFFSET a FETCH k přizpůsobení stránkování v dotazu. Dotaz pouze na 10 produktů najednou.
- Přidejte ID podkategorie produktu v doložce WHERE na základě výběru zákazníka.
- Odeberte Podkategorii produktu sloupec v klauzuli ORDER BY.
Dotaz bude nyní podobný tomuto:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Zlepší se po provedených změnách logická čtení? STATISTICS IO nyní hlásí:

Fotografie produktu tabulka má nyní 0 logických čtení – od 665 logických čtení až po žádné. To je určité zlepšení.
Také s sebou
Jedním ze způsobů, jak omezit logické čtení lob, je přepsat dotaz, aby se zjednodušil.
Odstraňte nepotřebné sloupce a snižte vrácené řádky na nejméně požadované. V případě potřeby použijte pro stránkování OFFSET a FETCH.
Chcete-li zajistit, aby změny dotazu zlepšily logické čtení lob a výkon dotazu SQL, vždy zkontrolujte STATISTICS IO.
3. Vysoká logická čtení pracovní tabulky/pracovního souboru
Konečně, je to logické čtení Worktable a Pracovní soubor . Ale jaké jsou tyto tabulky? Proč se zobrazují, když je ve svém dotazu nepoužíváte?
Máte Pracovní stůl a Pracovní soubor zobrazení ve STATISTICS IO znamená, že SQL Server potřebuje mnohem více práce, aby získal požadované výsledky. Uchýlí se k použití dočasných tabulek v tempdb , konkrétně Pracovní stoly a Pracovní soubory . Není nutně škodlivé mít je ve výstupu STATISTICS IO, pokud jsou logické čtení nulové a nezpůsobuje to potíže serveru.
Tyto tabulky se mohou objevit, pokud existuje mimo jiné ORDER BY, GROUP BY, CROSS JOIN nebo DISTINCT.
Příklad logického čtení Worktable/Workfile
Předpokládejme, že potřebujete dotazovat všechny obchody bez prodeje určitých produktů.
Nejprve přijdete s následujícím:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDTento dotaz vrátil 3649 řádků:
Podívejme se, co říká STATISTICS IO:

Stojí za zmínku, že Pracovní stůl logická čtení jsou 7128. Celková logická čtení jsou 8853. Pokud zkontrolujete plán provádění, uvidíte spoustu paralelismů, shod hash, spoolů a prohledávání indexů.
Snížení počtu logických čtení pracovních tabulek/pracovních souborů
Nemohl jsem sestavit jediný příkaz SELECT s uspokojivým výsledkem. Jedinou možností je tedy rozdělit příkaz SELECT na více dotazů. Viz níže:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsJe o několik řádků delší a používá dočasné tabulky. Nyní se podívejme, co odhaluje STATISTICS IO:
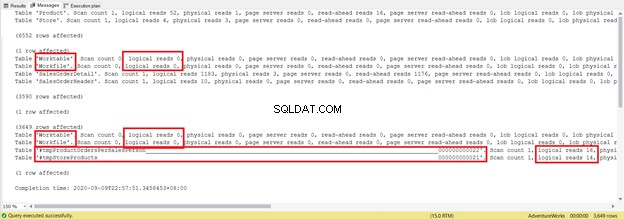
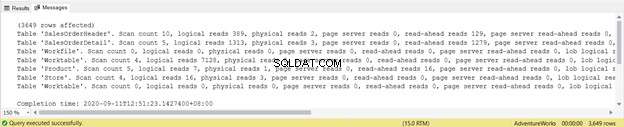
Zkuste se nezaměřovat na délku této statistické zprávy – je to jen frustrující. Místo toho přidejte logické čtení z každé tabulky.
Z celkových 1279 je to významný pokles, protože to bylo 8853 logických čtení z jediného příkazu SELECT.
Do dočasných tabulek jsme nepřidali žádný index. Možná budete jeden potřebovat, pokud do SalesOrderHeader přidáte mnohem více záznamů a SalesOrderDetail . Ale rozumíte tomu.
Také s sebou
Někdy se 1 příkaz SELECT jeví jako dobrý. V zákulisí je však opak pravdou. Pracovní stoly a Pracovní soubory s vysokým logickým čtením zpoždění vašeho dotazu SQL.
Pokud vás nenapadá jiný způsob, jak rekonstruovat dotaz a indexy jsou k ničemu, zkuste přístup „rozděl a panuj“. Pracovní stoly a Pracovní soubory se stále může objevit na kartě Zpráva SSMS, ale logická čtení budou nulová. Celkový výsledek tedy bude méně logický.
Sečteno a podtrženo ve výkonu SQL Query a STATISTICS IO
Co je na těchto 3 odporných I/O statistikách důležité?
Rozdíl ve výkonu SQL dotazu bude jako noc a den, pokud budete věnovat pozornost těmto číslům a snížíte je. Uvedli jsme pouze některé způsoby, jak omezit logické čtení, jako:
- vytvoření vhodných indexů;
- zjednodušení dotazů – odstranění nepotřebných sloupců a minimalizace sady výsledků;
- rozdělení dotazu na více dotazů.
Existuje více jako aktualizace statistik, defragmentace indexů a nastavení správného FILLFACTORU. Můžete k tomu přidat více v sekci komentářů?
Pokud se vám tento příspěvek líbí, sdílejte ho se svými oblíbenými sociálními médii.