V mém předchozím příspěvku o přírůstkové statistice, nové funkci v SQL Server 2014, jsem ukázal, jak mohou pomoci zkrátit dobu trvání úlohy údržby. Je to proto, že statistiky lze aktualizovat na úrovni oddílu a změny sloučit do hlavního histogramu pro tabulku. Také jsem si všiml, že Query Optimizer nepoužívá tyto statistiky na úrovni oddílu při generování plánů dotazů, což může být něco, co lidé očekávali. Neexistuje žádná dokumentace, která by uváděla, že přírůstkové statistiky budou nebo nebudou použity Optimalizátorem dotazů. Tak jak to víš? Musíte to otestovat. :-)
Nastavení
Nastavení pro tento test bude podobné jako v posledním příspěvku, ale s menším množstvím dat. Upozorňujeme, že výchozí velikosti jsou pro datové soubory menší a skript se načte pouze v několika milionech řádků dat:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Když vytvoříme seskupený index pro dbo.Orders, vytvoříme jej bez STATISTICS_INCREMENTAL povolena, takže začneme s tradiční rozdělenou tabulkou bez přírůstkových statistik:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Dále načteme asi 4 miliony řádků, což na mém počítači zabere necelou minutu:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Po načtení dat aktualizujeme statistiky pomocí FULLSCAN (takže můžeme vytvořit konzistentní histogram pro testy) a poté ověříme, jaká data máme v každém oddílu:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Data v každém oddílu po načtení dat
Data v každém oddílu po načtení dat
Většina dat je v oddílu 2015, ale jsou zde také data za roky 2012, 2013 a 2014. A pokud zkontrolujeme výstup z nezdokumentovaného DMV sys.dm_db_stats_properties_internal , vidíme, že neexistují žádné statistiky na úrovni oddílu:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal výstup zobrazující pouze jednu statistiku pro dbo.Orders
sys.dm_db_stats_properties_internal výstup zobrazující pouze jednu statistiku pro dbo.Orders
Test
Testování vyžaduje jednoduchý dotaz, pomocí kterého můžeme ověřit, že dojde k odstranění oddílu, a také zkontrolovat odhady založené na statistikách. Dotaz nevrací žádná data, ale to nevadí, zajímá nás, co si optimalizátor myslel vrátí se na základě statistik:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
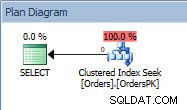 Plán dotazů pro příkaz SELECT
Plán dotazů pro příkaz SELECT
Plán má Clustered Index Seek, a pokud zkontrolujeme vlastnosti, uvidíme, že odhadoval 4000 řádků a přistupoval k oddílu 5, který obsahuje data za rok 2014.
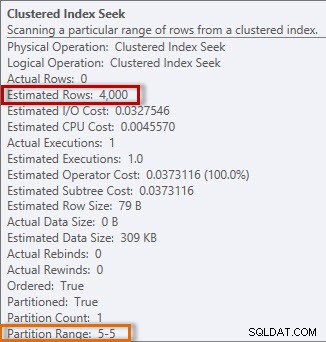 Odhadované a skutečné informace z Clustered Index Seek
Odhadované a skutečné informace z Clustered Index Seek
Pokud se podíváme na histogram pro tabulku dbo.Orders, konkrétně v oblasti dat dubna 2014, vidíme, že pro 2014-04-01 není žádný krok, takže optimalizátor odhadne počet řádků pro toto datum pomocí kroku pro 2014-04-24, kde AVG_RANGE_ROWS je 4000 (pro libovolnou hodnotu mezi 2014-02-14 a 2014-04-23 včetně, optimalizátor odhadne, že bude vráceno 4000 řádků).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
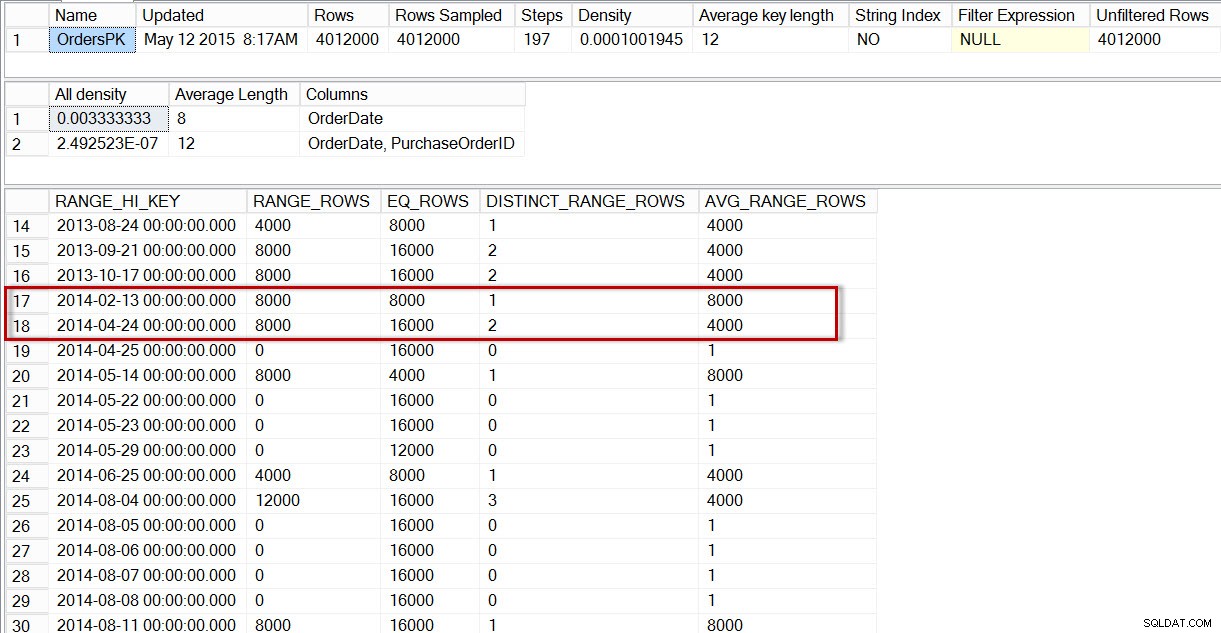 Distribuce v histogramu dbo.Orders
Distribuce v histogramu dbo.Orders
Odhad a plán jsou zcela očekávané. Povolme přírůstkové statistiky a uvidíme, co získáme.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Pokud znovu spustíme dotaz proti sys.dm_db_stats_properties_internal , můžeme vidět přírůstkové statistiky:
 sys.dm_db_stats_properties_internal zobrazující informace o přírůstkových statistikách
sys.dm_db_stats_properties_internal zobrazující informace o přírůstkových statistikách
Nyní znovu spusťte náš dotaz dbo.Orders a spustíme DBCC FREEPROCCACHE nejprve se plně ujistěte, že plán není znovu použit:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Dostáváme stejný plán a stejný odhad:
Plán dotazů pro příkaz SELECT
Odhadované a skutečné informace z Clustered Index Seek
Pokud zkontrolujeme hlavní histogram pro dbo.Orders, uvidíme téměř stejný histogram jako předtím:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogram pro dbo.Orders po povolení přírůstkových statistik
Histogram pro dbo.Orders po povolení přírůstkových statistik
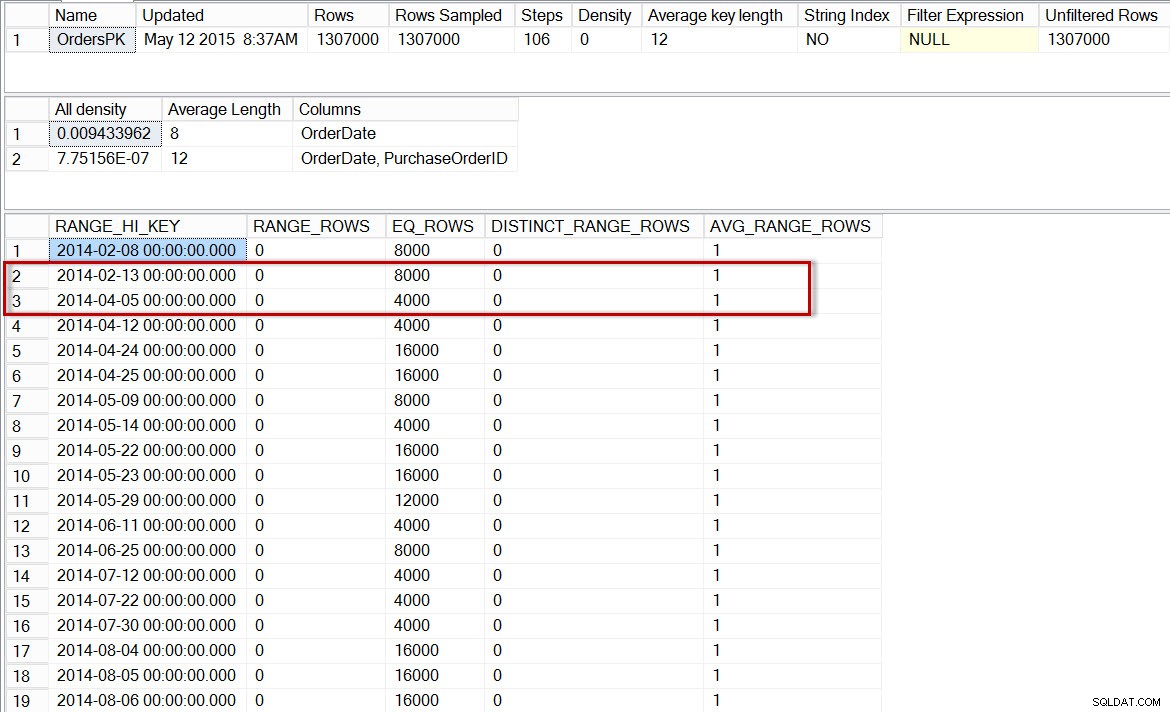
Nyní zkontrolujeme histogram pro oddíl s daty z roku 2014 (můžeme to provést pomocí nezdokumentovaného příznaku trasování 2309, který umožňuje zadat číslo oddílu jako další argument pro DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogram pro oddíl dbo.Orders pro rok 2014 po povolení přírůstkových statistik
Zde vidíme, že opět neexistuje žádný krok pro 2014-04-01, ale je zde 0 RANGE_ROWS mezi 2014-02-13 a 2014-04-05, s AVG_RANGE_ROWS z 1. Pokud by optimalizátor používal histogram pro statistiku na úrovni oddílu, pak by odhad počtu řádků pro 2014-04-01 byl 1.
Poznámka:Oddíl identifikovaný jako použitý v plánu dotazů je 5, ale všimnete si, že DBCC SHOW_STATISTICS statement references partition 6. Předpokladem je nekonzistence ve statistických metadatech (běžná chyba typu off-by-one, pravděpodobně kvůli počítání založenému na 0 vs. na 1), která může, ale nemusí být v budoucnu opravena. Pochopte, že příznak trasování není v současné době zdokumentován a že se nedoporučuje používat v produkčním prostředí.
Shrnutí
Přidání přírůstkových statistik ve verzi SQL Server 2014 je krokem správným směrem pro lepší odhady mohutnosti pro dělené tabulky. Jak jsme však ukázali, současná hodnota přírůstkové statistiky je omezena na zkrácené doby údržby, protože tyto přírůstkové statistiky zatím Optimalizátor dotazů nepoužívá.