V mém posledním příspěvku jsme viděli, jak dotaz obsahující skalární agregát může být transformován optimalizátorem do efektivnější podoby. Pro připomenutí, zde je opět schéma:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Volby plánu
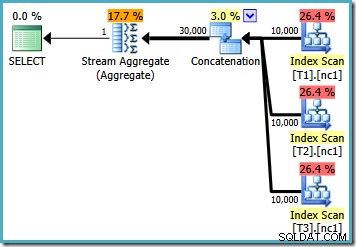
S 10 000 řádky v každé ze základních tabulek přichází optimalizátor s jednoduchým plánem, který vypočítá maximum načtením všech 30 000 řádků do agregace:
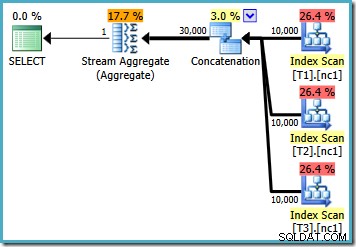
S 50 000 řádky v každé tabulce stráví optimalizátor problémem trochu více času a najde chytřejší plán. Přečte pouze horní řádek (v sestupném pořadí) z každého indexu a poté vypočítá maximum pouze z těchto 3 řádků:
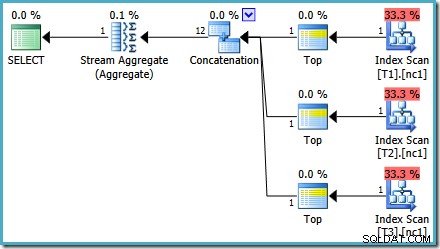
Chyba Optimalizátoru
Možná si na tom odhadu všimnete něčeho trochu zvláštního plán. Operátor Concatenation přečte jeden řádek ze tří tabulek a nějakým způsobem vytvoří dvanáct řádků! Toto je chyba způsobená chybou v odhadu mohutnosti, kterou jsem nahlásil v květnu 2011. Stále není opravena od SQL Server 2014 CTP 1 (i když je použit nový odhad mohutnosti), ale doufám, že bude vyřešena pro konečné vydání.
Chcete-li vidět, jak k chybě dochází, připomeňte si, že jedna z alternativ plánu, kterou optimalizátor zvažoval pro případ 50 000 řádků, má pod operátorem Zřetězení částečné agregace:
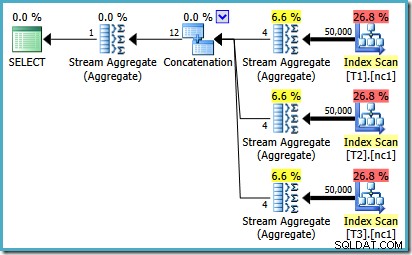
Je to odhad mohutnosti pro tyto částečné MAX agregáty, které jsou na vině. Odhadují čtyři řádky, kde je výsledek zaručeně jeden řádek. Můžete vidět jiné číslo než čtyři – záleží na tom, kolik logických procesorů má optimalizátor k dispozici v době kompilace plánu (další podrobnosti viz odkaz na chybu výše).
Optimalizátor později nahradí dílčí agregace operátory Top (1), které správně přepočítají odhad mohutnosti. Je smutné, že operátor zřetězení stále odráží odhady pro nahrazené dílčí agregáty (3 * 4 =12). Výsledkem je, že skončíme se zřetězením, které přečte 3 řádky a vytvoří 12.
Použití TOP místo MAX
Když se znovu podíváme na plán 50 000 řádků, zdá se, že největším zlepšením, které optimalizátor našel, je použití operátorů Top (1) namísto čtení všech řádků a výpočtu maximální hodnoty pomocí hrubé síly. Co se stane, když zkusíme něco podobného a přepíšeme dotaz explicitně pomocí Top?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Plán provádění nového dotazu je:
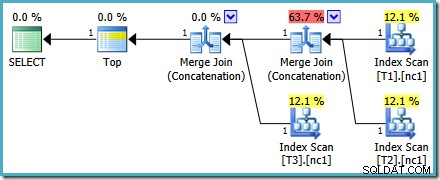
Tento plán je zcela odlišný od plánu zvoleného optimalizátorem pro MAX dotaz. Obsahuje tři uspořádané indexové skeny, dvě slučovací spojení běžící v režimu zřetězení a jeden top operátor. Tento nový plán dotazů má některé zajímavé funkce, které stojí za to prozkoumat trochu podrobněji.
Analýza plánu
První řádek (v sestupném pořadí indexu) se načte z neshlukovaného indexu každé tabulky a použije se spojení Merge Join pracující v režimu zřetězení. Přestože operátor Merge Join neprovádí spojení v normálním slova smyslu, algoritmus zpracování tohoto operátora lze snadno přizpůsobit pro zřetězení jeho vstupů namísto použití kritérií spojení.
Výhodou použití tohoto operátoru v novém plánu je, že sloučení zřetězení zachovává pořadí řazení napříč svými vstupy. Naproti tomu běžný operátor Concatenation čte ze svých vstupů postupně. Níže uvedený diagram ukazuje rozdíl (kliknutím rozbalíte):
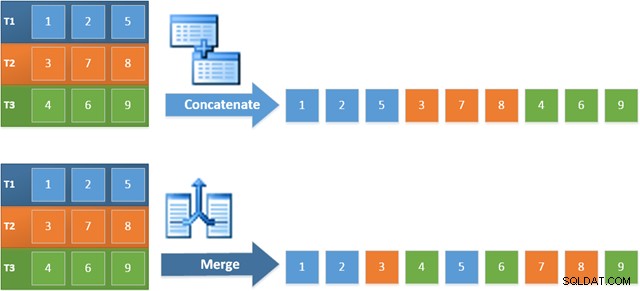
Chování funkce Merge Concatenation zachovávající pořadí znamená, že první řádek vytvořený operátorem Merge nejvíce vlevo v novém plánu je zaručeně řádkem s nejvyšší hodnotou ve sloupci c1 ve všech třech tabulkách. Přesněji řečeno, plán funguje následovně:
- Jeden řádek se čte z každé tabulky (v sestupném pořadí indexu); a
- Každé sloučení provede jeden test abyste viděli, který z jeho vstupních řádků má vyšší hodnotu
Zdá se, že jde o velmi efektivní strategii, takže se může zdát zvláštní, že optimalizátor má hodnotu MAX plán má odhadované náklady na méně než polovinu nového plánu. Důvodem je do značné míry to, že se předpokládá, že slučovací zřetězení zachovávající pořadí je dražší než jednoduché zřetězení. Optimalizátor si neuvědomuje, že každé sloučení může vždy vidět maximálně jeden řádek, a v důsledku toho nadhodnocuje své náklady.
Další problémy s kalkulací
Přísně vzato zde neporovnáváme jablka s jablky, protože dva plány jsou pro různé dotazy. Porovnávat náklady, jako je toto, není obecně platné, ačkoli SSMS to přesně dělá tím, že zobrazuje procenta nákladů pro různé výpisy v dávce. Ale to jsem odbočil.
Pokud se podíváte na nový plán v SSMS namísto SQL Sentry Plan Explorer, uvidíte něco takového:
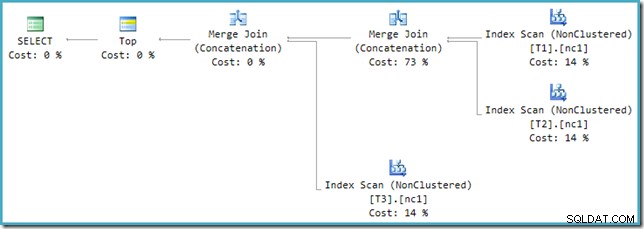
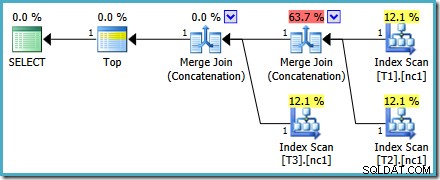
Jeden z operátorů Merge Join Concatenation má odhadované náklady 73 %, zatímco druhý (operující na přesně stejném počtu řádků) nestojí vůbec nic. Dalším znakem toho, že je zde něco špatně, je to, že procenta nákladů operátora v tomto plánu nejsou v součtu 100 %.
Optimizer versus Execution Engine
Problém spočívá v nekompatibilitě mezi optimalizátorem a prováděcím jádrem. V optimalizátoru mohou mít Union a Union All 2 nebo více vstupů. V prováděcím jádru může pouze operátor Concatenation přijmout 2 nebo více vstupy; Merge Join vyžaduje přesně dva vstupy, i když jsou nakonfigurovány tak, aby prováděly spíše zřetězení než spojení.
K vyřešení této nekompatibility je použito přepsání po optimalizaci, které převede výstupní strom optimalizátoru do podoby, kterou zvládne prováděcí modul. Pokud je pomocí Sloučení implementována Unie nebo Unie All s více než dvěma vstupy, je zapotřebí řetězec operátorů. Se třemi vstupy do Union All v tomto případě jsou zapotřebí dvě Slučovací unie:
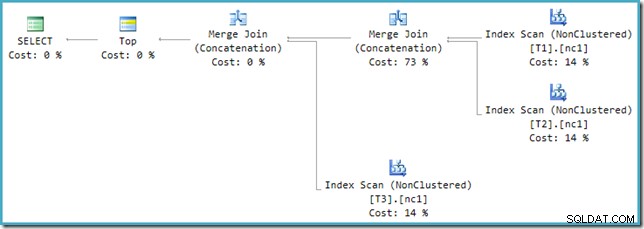
Můžeme vidět výstupní strom optimalizátoru (se třemi vstupy do fyzického sloučení) pomocí příznaku trasování 8607:
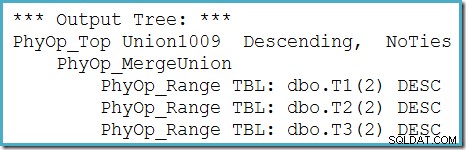
Neúplná oprava
Bohužel přepis po optimalizaci není dokonale implementován. Dělá to trochu nepořádek v kalkulacích. Když problémy zaokrouhlíme stranou, náklady plánu se zvyšují až o 114 %, přičemž dalších 14 % pochází ze vstupu do zvláštního zřetězení spojení sloučení generovaného přepsáním:
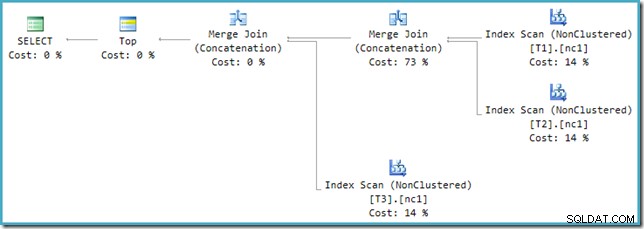
Sloučení zcela vpravo v tomto plánu je původní operátor ve výstupním stromu optimalizátoru. Jsou jí přiděleny plné náklady na provoz Union All. Další sloučení je přidáno přepsáním a získává nulové náklady.
Ať už se na to podíváme jakkoli (a existují různé problémy, které ovlivňují pravidelné zřetězení), čísla vypadají podivně. Průzkumník plánů dělá, co je v jeho silách, aby obešel nefunkční informace v plánu XML tím, že alespoň zajistí, že součet čísel bude 100 %:
Tento konkrétní problém s kalkulací je opraven v SQL Server 2014 CTP 1:
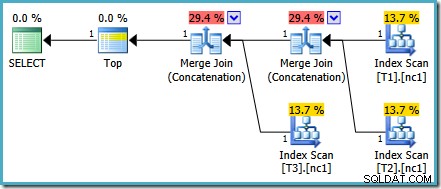
Náklady na slučovací zřetězení jsou nyní rovnoměrně rozděleny mezi oba operátory a procenta tvoří 100 %. Protože základní XML bylo opraveno, SSMS také dokáže zobrazovat stejná čísla.
Který plán je lepší?
Pokud dotaz napíšeme pomocí MAX , musíme se spolehnout na to, že se optimalizátor rozhodne provést práci navíc potřebnou k nalezení efektivního plánu. Pokud optimalizátor brzy najde zjevně dostatečně dobrý plán, může vytvořit relativně neefektivní plán, který přečte každý řádek z každé základní tabulky:
Pokud používáte SQL Server 2008 nebo SQL Server 2008 R2, optimalizátor přesto vybere neefektivní plán bez ohledu na počet řádků v základních tabulkách. Následující plán byl vytvořen na SQL Server 2008 R2 s 50 000 řádky:
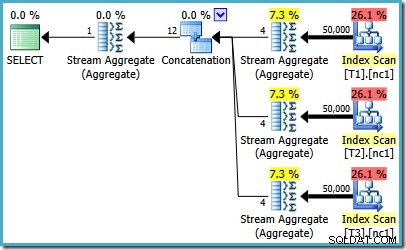
I s 50 miliony řádků v každé tabulce optimalizátor 2008 a 2008 R2 pouze přidává paralelismus, nezavádí top operátory:
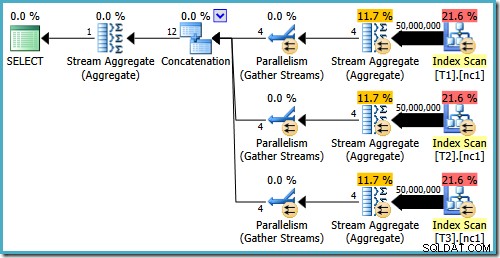
Jak bylo zmíněno v mém předchozím příspěvku, příznak trasování 4199 je nutný k tomu, aby SQL Server 2008 a 2008 R2 vytvořil plán s nejlepšími operátory. SQL Server 2005 a 2012 a novější nevyžadují příznak trasování:
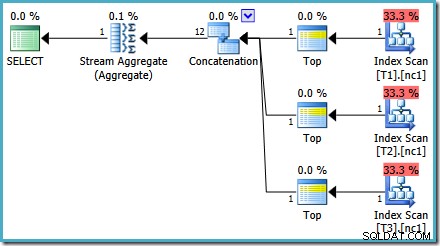
NEJLEPŠÍ s ORDER BY
Jakmile pochopíme, co se děje v předchozích plánech provádění, můžeme se vědomě (a informovaně) rozhodnout přepsat dotaz pomocí explicitního TOP s ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Výsledný plán provádění může mít procenta nákladů, která v některých verzích SQL Server vypadají zvláštně, ale základní plán je správný. Přepis po optimalizaci, který způsobuje, že čísla vypadají lichě, se použije po dokončení optimalizace dotazu, takže si můžeme být jisti, že výběr plánu optimalizátorem nebyl tímto problémem ovlivněn.
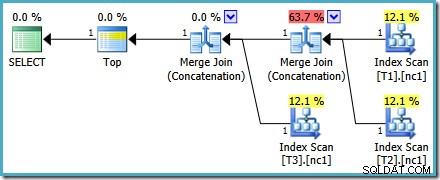
Tento plán se nemění v závislosti na počtu řádků v základní tabulce a ke generování nevyžaduje žádné příznaky trasování. Malou výhodou navíc je, že tento plán najde optimalizátor během první fáze optimalizace na základě nákladů (hledání 0):
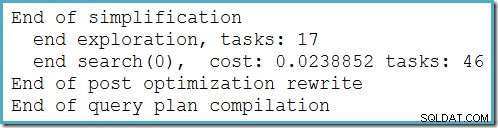
Nejlepší plán vybraný optimalizátorem pro MAX dotaz vyžadoval spuštění dvou fází optimalizace založené na nákladech (hledání 0 a hledat 1).
Mezi TOP je malý sémantický rozdíl dotaz a původní MAX forma, kterou bych měl zmínit. Pokud žádná z tabulek neobsahuje řádek, původní dotaz vytvoří jeden NULL výsledek. Náhrada TOP (1) dotaz nevytváří za stejných okolností vůbec žádný výstup. Tento rozdíl není v dotazech v reálném světě často důležitý, ale je třeba si ho uvědomit. Můžeme replikovat chování TOP pomocí MAX v SQL Server 2008 a dále přidáním prázdné sady GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Tato změna nemá vliv na prováděcí plány generované pro MAX dotazovat způsobem, který je viditelný pro koncové uživatele.
MAXIMÁLNÍ s Merge Concatenation
Vzhledem k úspěchu spojení Merge Join Concatenation v TOP (1) realizačního plánu, je přirozené se ptát, zda lze stejný optimální plán vygenerovat pro původní MAX dotaz, pokud optimalizátor přinutíme použít sloučit zřetězení místo běžného zřetězení pro UNION ALL operace.
Pro tento účel existuje nápověda k dotazu – MERGE UNION – ale bohužel to funguje správně pouze v SQL Server 2012 a novější. V předchozích verzích UNION nápověda se týká pouze UNION dotazy, nikoli UNION ALL . V SQL Server 2012 a novějších můžeme zkusit toto:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Jsme odměněni plánem, který obsahuje Merge Concatenation. Bohužel to není úplně všechno, v co jsme mohli doufat:
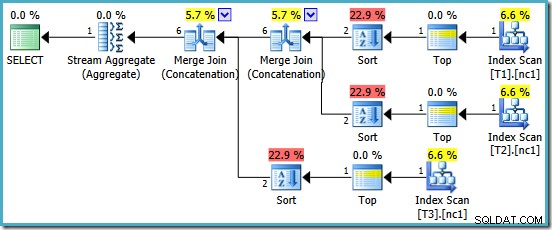
Zajímavými operátory v tomto plánu jsou druhy. Všimněte si odhadu mohutnosti vstupu 1 řádek a odhadu 4 řádků výstupu. Příčina by vám již měla být známá:je to stejná částečná chyba odhadu agregované mohutnosti, o které jsme hovořili dříve.
Přítomnost druhů odhaluje ještě jeden problém s dílčími agregáty. Nejen, že produkují nesprávný odhad mohutnosti, ale také nedokážou zachovat řazení indexu, takže řazení by bylo zbytečné (Merge Concatenation vyžaduje tříděné vstupy). Částečné agregace jsou skalární MAX agregáty, zaručeně produkují jeden řádek, takže otázka objednávání by měla být sporná (existuje jen jeden způsob, jak třídit jeden řádek!)
To je škoda, protože bez těchto druhů by to byl slušný plán provedení. Pokud byly dílčí agregace správně implementovány, a MAX zapsaný pomocí GROUP BY () klauzule, můžeme dokonce doufat, že optimalizátor dokáže zjistit, že tři vrcholy a konečný agregát proudu by mohly být nahrazeny jediným konečným operátorem vrcholu, což by poskytlo přesně stejný plán jako explicitní TOP (1) dotaz. Optimalizátor dnes tuto transformaci neobsahuje a nepředpokládám, že by byl dostatečně často užitečný, aby se jeho zahrnutí v budoucnu vyplatilo.
Poslední slova
Pomocí TOP nebude vždy vhodnější než MIN nebo MAX . V některých případech vytvoří výrazně méně optimální plán. Pointou tohoto příspěvku je, že pochopení transformací aplikovaných optimalizátorem může navrhnout způsoby, jak přepsat původní dotaz, což se může ukázat jako užitečné.