Každý databázový architekt, který navrhuje databázi MySQL, čelí problému výběru správného úložiště. Aplikace obvykle používá pouze jeden engine:MyISAM nebo InnoDB . Ale zkusme být trochu flexibilnější a představme si, jak lze použít různé úložné moduly.
Počáteční datový model
Začněme tím, že vytvoříme zjednodušený datový model pro systém CRM (řízení vztahů se zákazníky), který použijeme k ilustraci tohoto bodu. Návrh bude pokrývat hlavní funkce CRM:prodejní data, definice produktů a informace pro analýzu. Neobsahuje podrobnosti běžně používané v systémech CRM.
Jak vidíte, tento datový model obsahuje tabulky, které ukládají transakční informace zvané sale a sale_item . Když zákazník něco koupí, aplikace vytvoří nový řádek v sale stůl. Každý zakoupený produkt se projeví v sale_item stůl. Související tabulka sale_status , slouží k ukládání možných stavů (tj. nevyřízeno, dokončeno atd.).
product tabulka ukládá informace o zboží. Definuje každý produkt a jeho základní deskriptory. V podrobnějším diagramu bych přidal další tabulky pro zpracování specifikace produktu a kategorizace. Ale pro naše současné potřeby to není nutné.
Tabulka zákazníků uchovává údaje o klientech. Je nedílnou součástí každého CRM systému a obvykle sleduje individuální aktivitu všech uživatelů. Je zřejmé, že má často opravdu podrobné informace. Ale jak jsem poznamenal, tyto podrobnosti teď nepotřebujeme.
log tabulka ukládá, co každý zákazník udělal v rámci aplikace. A report_sales tabulka je navržena pro využití datové analýzy.
Dále popíšu úložné stroje MySQL, které by mohly být v tomto návrhu použity. A později probereme, který motor je vhodný pro každý typ stolu.
Přehled úložiště MySQL
Úložný modul je softwarový modul, který MySQL používá k vytváření, čtení nebo aktualizaci dat z databáze. Nedoporučuje se náhodně vybírat engine, ale mnoho vývojářů s radostí používá buď MyISAM nebo InnoDB, i když jsou k dispozici i jiné možnosti. Každý motor má své klady a zápory a správný výběr motoru závisí na několika faktorech. Pojďme se podívat na nejoblíbenější motory.
- MyISAM má dlouhou historii s MySQL. Před vydáním 5.5 to byl výchozí engine pro databáze MySQL. MyISAM nepodporuje transakce a má pouze zamykání na úrovni tabulky. Většinou se používá pro aplikace náročné na čtení.
- InnoDB je obecné úložiště, které vyvažuje vysokou spolehlivost a dobrý výkon. Podporuje transakce, zamykání na úrovni řádků, zotavení po havárii a řízení souběžnosti více verzí. Poskytuje také omezení referenční integrity cizího klíče.
- Paměť motor ukládá všechna data do paměti RAM. Lze jej použít pro ukládání referencí vyhledávání.
- Další modul, CSV , uchovává data v textových souborech s hodnotami oddělenými čárkami. Tento formát se většinou používá pro integraci s jinými systémy.
- Sloučit je dobrou volbou pro systémy vykazování, například v datových skladech. Umožňuje logické seskupení sady identických tabulek MyISAM, na které lze také odkazovat jako na jeden objekt.
- Archivovat je optimalizován pro vysokorychlostní vkládání. Ukládá informace v kompaktních, neindexovaných tabulkách a nepodporuje transakce. Archivační úložiště je ideální pro uchovávání velkého množství málokdy odkazovaných historických nebo archivovaných dat.
- Federated engine nabízí možnost oddělit servery MySQL nebo vytvořit jednu logickou databázi z mnoha fyzických serverů. V lokálních tabulkách nejsou uložena žádná data a dotazy jsou automaticky prováděny ve vzdálených (federovaných) tabulkách.
- Blackhole motor funguje jako „černá díra“, která přijímá data, ale neukládá je. Všechny výběry vrátí prázdnou datovou sadu.
- Příklad motoru se používá k ukázce, jak vyvíjet nové úložiště.
Toto není úplný seznam úložišť. MySQL 5.x podporuje devět z nich přímo z krabice a desítky dalších vyvinutých komunitou MySQL. Další podrobnosti o úložištích lze nalézt v oficiální dokumentaci MySQL.
Aktualizace návrhu datového modelu
Podívejte se znovu na náš datový model. Je zřejmé, že různé tabulky budou použity různými způsoby. sale tabulka musí podporovat transakce. Na druhou stranu log a report_sales tabulky tuto funkci nevyžadují. Hlavním posláním log tabulka ukládá data s maximální účinností. Rychlé vyhledání je hlavním požadavkem pro report_sales stůl.
Mějme na paměti výše uvedené body a upravme naše schéma databáze. Ve Vertabelo můžete nastavit „Storage engine“ v Vlastnosti tabulky panel. Podívejte se prosím na obrázky níže.

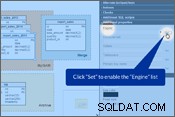
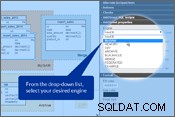
Nastavení úložiště
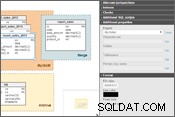
Pojďme se tedy podívat na aktualizovaný návrh databáze.
Zadal jsem moduly úložiště pro existující tabulky a reorganizoval report_sales stůl. Jak vidíte, tabulky jsou rozděleny do tří skupin:
- Tabulky transakcí, které se používají s hlavní aplikací
- Tabulky přehledů pro analýzu BI
- Tabulka protokolu pro ukládání veškeré aktivity uživatele
Promluvme si o všech zvlášť.
Tabulky transakcí
Tyto tabulky obsahují data zadaná uživateli během každodenních rutinních operací. V našem případě by to byly informace o prodeji, jako například:
- který zaměstnanec provedl prodej
- kdo produkt zakoupil
- co se prodalo
- kolik to stojí
Ve většině případů je InnoDB nejlepším řešením pro transakční tabulky. Tento modul úložiště podporuje zamykání řádků a někteří uživatelé jsou schopni spolupracovat. Stejně tak InnoDB umožňuje použití transakcí a cizích klíčů. Ale, jak víte, tyto výhody nejsou zadarmo; engine může provádět vybrané příkazy pomaleji než MyISAM a ukládat data s nižší účinností než Archive.
Všechny výše popsané motory mají určitou ochranu, takže vývojáři nemusí pro každou operaci psát složité funkce vrácení. V typické prodejní aplikaci je zachování konzistence dat důležitější než možné problémy s výkonem.
Tabulky přehledů
V novém designu jsem jeden stůl rozdělil na pár menších stolků. To šetří námahu, když přijde čas na správu dat a provádění údržby tabulek a indexů. Umožňuje nám také vytvořit tabulku MERGE sale_report pro kombinování dalších tabulek přehledů. Výsledkem je, že nástroj BI stále načítá data z jedné velké tabulky (pro účely analýzy), ale máme tu výhodu, že pracujeme s menšími tabulkami.
Report_sale_{year} tabulky jsou tabulky MyISAM. Tento modul úložiště nepodporuje transakce a může uzamknout pouze tabulku jako celek. Protože se MyISAM nestará o tyto složité položky, provádí operace manipulace s daty rychle. Díky své struktuře souborů čte toto úložiště data rychleji než populárnější InnoDB.
Tabulka protokolu
Archive storage engine je dobrou volbou pro ukládání dat protokolu. Dokáže rychle vkládat řádky a komprimovat uložená data. Uchovávání informací o aktivitách uživatelů má velké výhody. Archiv má však určitá omezení. Nepodporuje operace aktualizace a načítá data pomalu. Ale v tabulce protokolu jsou popsané výhody důležitější než nevýhody.
Integrace úložných modulů
Každý systém musí být integrován s vnějším životem. U aplikací to mohou být uživatelé, kteří naplňují referenční a transakční tabulky. Mohou to být služby a integrace přes REST, SOAP, WCF nebo něco podobného. A v neposlední řadě to může být integrace databáze.
MySQL a Oracle vyvinuly dva opravdu užitečné nástroje pro ukládání dat:Federated a CSV . První, federovaný , by měl být použit pro načítání dat z externí databáze MySQL. Druhý modul úložiště, CSV , umožňuje databázím ukládat záznamy ve formátu CSV a číst soubory oddělené čárkami ve vysílání bez jakéhokoli dalšího úsilí.
Jak vidíte, používání různých modulů úložiště pro různé účely poskytuje vaší databázi větší flexibilitu. Pokud se databázový architekt rozhodne po zvážení všech pro a proti, pak může být výsledek opravdu působivý.
Máte zkušenosti s používáním různých úložišť při návrhu databází? Rád bych viděl vaše tipy a návrhy. Podělte se o ně v sekci komentářů.