Hledání dat řetězce pro libovolnou shodu podřetězců může být na SQL Server nákladná operace. Dotazy ve tvaru Column LIKE '%match%' nemůže používat vyhledávací schopnosti indexu b-stromu, takže procesor dotazu musí použít predikát na každý řádek samostatně. Kromě toho musí každý test správně aplikovat celou sadu komplikovaných pravidel řazení. Když zkombinujeme všechny tyto faktory dohromady, není žádným překvapením, že tyto typy vyhledávání mohou být náročné na zdroje a pomalé.
Fulltextové vyhledávání je výkonný nástroj pro lingvistické porovnávání a novější Statistické sémantické vyhledávání je skvělé pro vyhledávání dokumentů s podobným významem. Ale někdy opravdu potřebujete najít řetězce, které obsahují konkrétní podřetězec – podřetězec, který ani nemusí být slovo, v žádném jazyce.
Pokud hledaná data nejsou velká nebo požadavky na dobu odezvy nejsou kritické, použijte LIKE '%match%' může být vhodným řešením. Ale při zvláštní příležitosti, kdy potřeba superrychlého vyhledávání překonává všechny ostatní úvahy (včetně úložného prostoru), můžete zvážit vlastní řešení pomocí n-gramů. Specifickou variantou prozkoumanou v tomto článku je tříznakový trigram.
Vyhledávání pomocí zástupných znaků pomocí trigramů
Základní myšlenka trigramového vyhledávání je celkem jednoduchá:
- Přetrvávají tříznakové podřetězce (trigramy) cílových dat.
- Rozdělte hledané výrazy do trigramů.
- Přiřaďte vyhledávací trigramy k uloženým trigramům (hledání rovnosti)
- Protněte kvalifikované řádky a najděte řetězce, které odpovídají všem trigramům
- Použijte původní filtr vyhledávání na výrazně omezenou křižovatku
Projdeme si příklad, abychom přesně viděli, jak to všechno funguje a jaké jsou kompromisy.
Vzorová tabulka a data
Skript níže vytvoří ukázkovou tabulku a naplní ji milionem řádků řetězcových dat. Každý řetězec je dlouhý 20 znaků, přičemž prvních 10 znaků je číselných. Zbývajících 10 znaků je směsí čísel a písmen od A do F, vygenerovaných pomocí NEWID() . Na těchto ukázkových datech není nic zvláštního; technika trigramu je docela obecná.
-- Testovací tabulkaCREATE TABLE dbo.Příklad ( id celé číslo IDENTITA NENÍ NULL, řetězec char(20) NOT NULL, OMEZENÍ [PK dbo.Příklad (id)] PRIMÁRNÍ KLÍČ SE SLUSTROVANÝM (id));GO-- 1 milion rowsINSERT dbo.Příklad WITH (TABLOCKX) (řetězec)SELECT TOP (1 * 1000 * 1000) -- 10 numerických znaků REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), ' 0') + -- plus 10 smíšených číselných + [A-F] znaků VPRAVO(NEWID(), 10)OD master.dbo.spt_values JAKO SV1CROSS JOIN master.dbo.spt_values JAKO SV2OPTION (MAXDOP 1);
Trvá to přibližně 3 sekundy vytvořit a naplnit data na mém skromném notebooku. Data jsou pseudonáhodná, ale pro informaci budou vypadat nějak takto:
Ukázka dat
Generování trigramů
Následující inline funkce generuje odlišné alfanumerické trigramy z daného vstupního řetězce:
--- Generování trigramů z řetězceCREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))RETURNS tableWITH SCHEMABINDINGAS RETURN WITH N16 AS ( SELECT V.v FROM ( VALUES (0),(0),(0),(0) ),(0),(0),(0),(0), (0),(0),(0),(0),(0),(0),(0),(0) ) AS V (v)), -- Tabulka čísel (256) Nums AS ( SELECT n =ROW_NUMBER() OVER (ORDER BY A.v) FROM N16 AS A CROSS JOIN N16 AS B ), Trigrams AS ( -- Každý 3znakový podřetězec VYBERTE VRCHNÍ PŘÍPAD (PŘÍPAD, KDYŽ DÉLKA(@řetězec)> 2 THEN DÉLKA(@řetězec) - 2 ELSE 0 KONEC) trigram =PODŘETĚZEC(@řetězec, N.n, 3) FROM Nums AS N ORDER BY N.n ) -- Odstraňte duplikáty a zajistěte všechny tři znaky jsou alfanumerické VYBERTE DISTINCT T.trigram FROM Trigramy AS T WHERE -- Porovnání binárního řazení so r anges fungují podle očekávání T.trigram COLLATE Latin1_General_BIN2 NENÍ JAKO '%[^A-Z0-9a-z]%';
Jako příklad jeho použití lze uvést následující volání:
SELECT GT.trigramFROM dbo.GenerateTrigrams('SQLperformance.com') AS GT; Vytváří následující trigramy:

Trigramy SQLperformance.com
Prováděcí plán je v tomto případě docela přímý překlad T-SQL:
- Generování řádků (příčné spojení konstantních skenů)
- Číslování řádků (projekt segmentů a sekvencí)
- Omezení potřebného počtu na základě délky řetězce (nahoře)
- Odstraňte trigramy s nealfanumerickými znaky (filtr)
- Odstranění duplikátů (rozlišné řazení)

Plán pro generování trigramů
Načítání trigramů
Dalším krokem je zachování trigramů pro ukázková data. Trigramy budou uloženy v nové tabulce, naplněné pomocí inline funkce, kterou jsme právě vytvořili:
-- Trigramy pro příklad tableCREATE TABLE dbo.ExampleTrigrams( id integer NOT NULL, trigram char(3) NOT NULL);GO-- Generate trigramsINSERT dbo.ExampleTrigrams WITH (TABLOCKX) (id, trigram)SELECT E.id, GT.trigramFROM dbo.Example AS ECROSS APPLY dbo.GenerateTrigrams(E.string) AS GT;
To trvá přibližně 20 sekund spustit na mé instanci notebooku SQL Server 2016. Tento konkrétní běh vyprodukoval 17 937 972 řádků trigramů pro 1 milion řádků testovacích dat o 20 znacích. Prováděcí plán v podstatě ukazuje funkční plán vyhodnocovaný pro každý řádek tabulky Příklad:
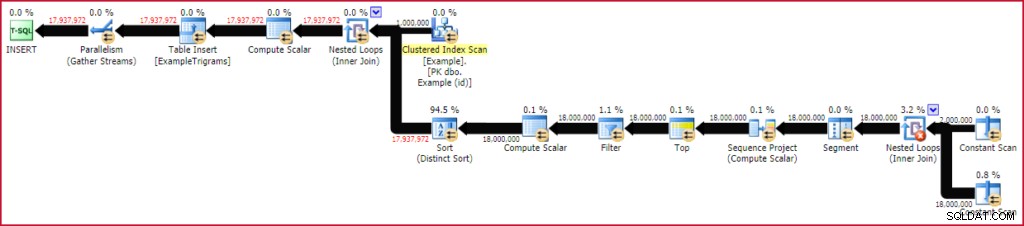
Vyplnění tabulky trigramů
Protože tento test byl proveden na serveru SQL Server 2016 (načítání tabulky haldy, pod úrovní kompatibility databáze 130 a s TABLOCK nápověda), plán těží z paralelní vložky. Řádky jsou rozděleny mezi vlákna pomocí paralelního prohledávání tabulky Příklad a poté zůstávají ve stejném vláknu (žádné výměny při přerozdělování).
Operátor řazení může vypadat trochu impozantně, ale čísla ukazují celkový počet seřazených řádků ve všech iteracích spojení vnořené smyčky. Ve skutečnosti existuje milion samostatných druhů, každý po 18 řádcích. Při stupni paralelismu čtyři (v mém případě dvě jádra s hypervláknem) v jednu chvíli probíhají maximálně čtyři drobné druhy a každá instance řazení může znovu používat paměť. To vysvětluje, proč je maximální využití paměti tohoto spouštěcího plánu pouhých 136 kB (ačkoli bylo přiděleno 2 152 kB).
Tabulka trigramů obsahuje jeden řádek pro každý odlišný trigram v každém řádku zdrojové tabulky (identifikováno pomocí id ):
Ukázka trigramové tabulky
Nyní vytváříme seskupený index b-stromu pro podporu vyhledávání shod trigramů:
-- Index hledání trigramůVYTVOŘTE UNIKÁTNÍ CLUSTERED INDEX [CUQ dbo.ExampleTrigrams (trigram, id)]ON dbo.ExampleTrigrams (trigram, id)WITH (DATA_COMPRESSION =ROW);
To trvá přibližně 45 sekund , i když něco z toho je způsobeno přeléváním řazení (moje instance je omezena na 4 GB paměti). Instance s více dostupnou pamětí by pravděpodobně mohla dokončit sestavení minimálně protokolovaného paralelního indexu o něco rychleji.
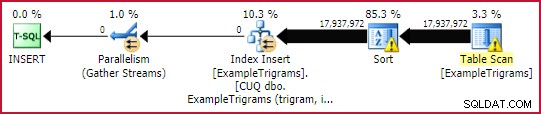
Plán vytváření indexu
Všimněte si, že index je určen jako jedinečný (pomocí obou sloupců v klíči). Mohli jsme vytvořit nejedinečný seskupený index na samotném trigramu, ale SQL Server by stejně přidal 4bajtové uniquifikátory do téměř všech řádků. Jakmile zohledníme, že uniquifikátory jsou uloženy v části řádku s proměnnou délkou (s přidruženou režií), dává větší smysl zahrnout id v klíči a hotovo.
Komprese řádků je určena, protože užitečně snižuje velikost tabulky trigramů z 277 MB na 190 MB (pro srovnání, tabulka Příklad má 32 MB). Pokud alespoň nepoužíváte SQL Server 2016 SP1 (kde byla komprese dat dostupná pro všechny edice), můžete v případě potřeby klauzuli o komprimaci vynechat.
Jako konečnou optimalizaci také vytvoříme indexovaný pohled na tabulku trigramů, aby bylo možné rychle a snadno najít, které trigramy se v datech vyskytují nejčastěji a které nejméně. Tento krok lze vynechat, ale je doporučen pro výkon.
-- Selektivita každého trigramu (optimalizace výkonu)CREATE VIEW dbo.ExampleTrigramCountsWITH SCHEMABINDINGASSELECT ET.trigram, cnt =COUNT_BIG(*)FROM dbo.ExampleTrigrams AS ETGROUP BYSTER ET.trigram;GO-- Zhmotnění viewCREATE UNIQUE CUQ dbo.ExampleTrigramCounts (trigram)]ON dbo.ExampleTrigramCounts (trigram);

Plán budovy s indexovaným zobrazením
Dokončení trvá jen několik sekund. Velikost materializovaného pohledu je malá, pouhých 104 kB .
Vyhledávání trigramů
Zadaný vyhledávací řetězec (např. '%find%this%' ), náš přístup bude:
- Vygenerujte kompletní sadu trigramů pro hledaný řetězec
- Použijte indexované zobrazení k nalezení tří nejselektivnějších trigramů
- Najděte ID odpovídající všem dostupným trigramům
- Načíst řetězce podle id
- Použijte úplný filtr na řádky kvalifikované pro trigram
Hledání selektivních trigramů
První dva kroky jsou docela jednoduché. Již máme funkci pro generování trigramů pro libovolný řetězec. Nalezení nejselektivnějšího z těchto trigramů lze dosáhnout připojením k indexovanému zobrazení. Následující kód zabalí implementaci pro naši ukázkovou tabulku do jiné vložené funkce. Uspořádá tři nejselektivnější trigramy do jedné řady pro pozdější snadné použití:
-- Nejselektivnější trigramy pro hledaný řetězec-- Vždy vrátí řádek (NULL, pokud nebyly nalezeny žádné trigramy)CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255))RETURNS tableWITH SCHEMABINDING ASRETURN SELECT -- Pivot trigram1 =MAX( CASE WHEN BT.rn =1 THEN BT.trigram END), trigram2 =MAX(CASE WHEN BT.rn =2 THEN BT.trigram END), trigram3 =MAX(CASE WHEN BT.rn =3 THEN BT.trigram END) OD ( -- Vygenerujte trigramy pro hledaný řetězec -- a vyberte tři nejselektivnější SELECT TOP (3) rn =ROW_NUMBER() OVER ( ORDER BY ETC.cnt ASC), GT.trigram FROM dbo.GenerateTrigrams(@string) AS GT PŘIPOJTE SE k dbo.ExampleTrigramCounts AS ETC S (NOEXPAND) NA ETC.trigram =GT.trigram ORDER BY ETC.cnt ASC ) AS BT;
Jako příklad:
VYBERTE EGBT.trigram1, EGBT.trigram2, EGBT.trigram3 FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT; vrací (pro moje ukázková data):
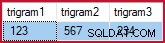
Vybrané trigramy
Prováděcí plán je:
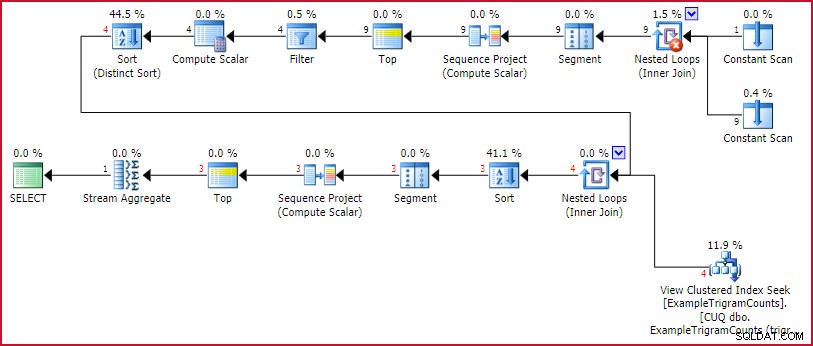
Plán realizace GetBestTrigrams
Toto je známý plán generování trigramů z dřívějška, po kterém následuje vyhledání v indexovaném zobrazení pro každý trigram, seřazení podle počtu shod, očíslování řádků (Sequence Project), omezení sady na tři řádky (Top) a poté otočení výsledek (Stream Aggregate).
Nalezení ID odpovídajících všem trigramům
Dalším krokem je najít ID řádků tabulky příkladů, která odpovídají všem nenulovým trigramům načteným předchozí fází. Vráska je v tom, že můžeme mít k dispozici nula, jeden, dva nebo tři trigramy. Následující implementace zabalí nezbytnou logiku do vícepříkazové funkce a vrátí kvalifikující ID v proměnné tabulky:
-- Vrátí ID příkladů odpovídající všem poskytnutým (nenulovým) trigramůmVYTVOŘENÍ FUNKCE dbo.Example_GetTrigramMatchIDs( @Trigram1 char(3), @Trigram2 char(3), @Trigram3 char(3))RETURNS @IDs tabulka (ID celé číslo PRIMÁRNÍ KLÍČ) SE SCHEMABINDING ASBEGIN IF @Trigram1 NENÍ NULL BEGIN IF @Trigram2 NENÍ NULL BEGIN IF @Trigram3 NENÍ NULL BEGIN -- 3 dostupné trigramy VLOŽTE @IDs (id) VYBERTE ET1.id Z dbo.Příklad1 WHERE JAKO 1ET .trigram =@Trigram1 INTERSECT SELECT ET2.id FROM dbo.ExampleTrigrams AS ET2 WHERE ET2.trigram =@Trigram2 INTERSECT SELECT ET3.id FROM dbo.ExampleTrigrams AS ET3 WHERE ET3.trigram =@TRIGE JO OPTION); KONEC; ELSE BEGIN -- 2 dostupné trigramy INSERT @IDs (id) SELECT ET1.id FROM dbo.ExampleTrigrams AS ET1 WHERE ET1.trigram =@Trigram1 INTERSECT SELECT ET2.id FROM dbo.ExampleTrigrams AS ET2 WHERE =ET2.trigram OP SLOUČIT PŘIPOJIT); KONEC; KONEC; ELSE BEGIN -- 1 trigram dostupný INSERT @IDs (id) SELECT ET1.id FROM dbo.ExampleTrigrams AS ET1 WHERE ET1.trigram =@Trigram1; KONEC; KONEC; RETURN;END;
Odhadovaný plán provádění této funkce ukazuje strategii:
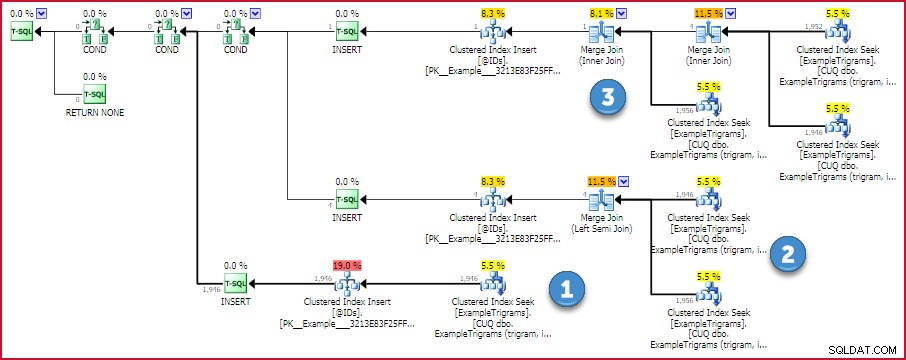
Plán ID shody Trigram
Pokud je k dispozici jeden trigram, provede se jedno vyhledávání do tabulky trigramů. V opačném případě se provedou dvě nebo tři hledání a najde se průnik id pomocí efektivního sloučení (sloučení) typu one-to-many. V tomto plánu nejsou žádní operátoři, kteří by spotřebovávali paměť, takže neexistuje žádná šance na hašování nebo přelévání.
Pokračujeme v hledání příkladu a můžeme najít ID odpovídající dostupným trigramům použitím nové funkce:
VYBERTE EGTMID.id Z dbo.Example_GetBestTrigrams('%1234%5678%') JAKO POUŽIJETE EGBTCROSS dbo.Example_GetTrigramMatchIDs (EGBT.trigram1, EGBT.trigram2, EGBT.trigram3;
Vrátí sadu podobnou následujícímu: 
Odpovídající ID
Aktuální plán (po provedení) pro novou funkci ukazuje tvar plánu se třemi použitými trigramovými vstupy:
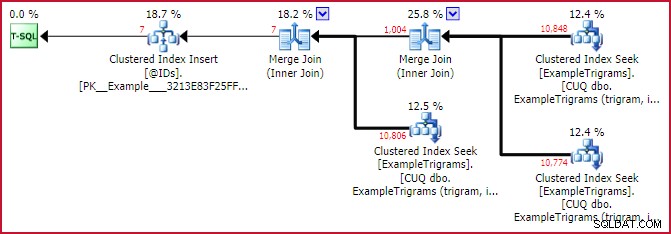
Plán shody skutečných ID
To docela dobře ukazuje sílu trigramového párování. Přestože každý ze tří trigramů identifikuje přibližně 11 000 řádků v tabulce Příklad, první průsečík tuto sadu zmenší na 1 004 řádků a druhý průsečík ji zmenší na pouhých 7 .
Kompletní implementace vyhledávání trigramů
Nyní, když máme ID odpovídající trigramům, můžeme vyhledat odpovídající řádky v tabulce Příklad. Stále musíme použít původní podmínku vyhledávání jako poslední kontrolu, protože trigramy mohou generovat falešně pozitivní (ale ne falešně negativní). Posledním problémem, který je třeba vyřešit, je, že předchozí fáze možná nenalezly žádné trigramy. To může být například proto, že hledaný řetězec obsahuje příliš málo informací. Vyhledávací řetězec '%FF%' nelze použít vyhledávání trigramů, protože dva znaky nestačí k vytvoření jediného trigramu. Abychom tento scénář zvládli elegantně, naše vyhledávání tuto podmínku detekuje a vrátí se k netrigramovému vyhledávání.
Následující konečná inline funkce implementuje požadovanou logiku:
-- Implementace vyhledáváníVYTVOŘIT FUNKCI dbo.Example_TrigramSearch( @Search varchar(255))VRÁTÍ tabulkuWITH SCHEMABINDINGASRETURN SELECT Result.string FROM dbo.Example_GetBestTrigrams(@Search) AS GBT CROSS APPLY ( -- Trigram search E. řetězec FROM dbo.Example_GetTrigramMatchIDs (GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID JOIN dbo.Příklad AS E ON E.id =MID.id WHERE -- Nalezen alespoň jeden trigram GBT.trigram1 NENÍ NULL A EKlíčovým prvkem je vnější odkaz na
GBT.trigram1na obou stranáchUNION ALL. Ty se převádějí na Filtry se spouštěcími výrazy v prováděcím plánu. Spouštěcí filtr spustí svůj podstrom pouze v případě, že se jeho podmínka vyhodnotí jako pravdivá. Čistým efektem je, že bude provedena pouze jedna část spojení, vše v závislosti na tom, zda jsme našli trigram nebo ne. Příslušná část prováděcího plánu je: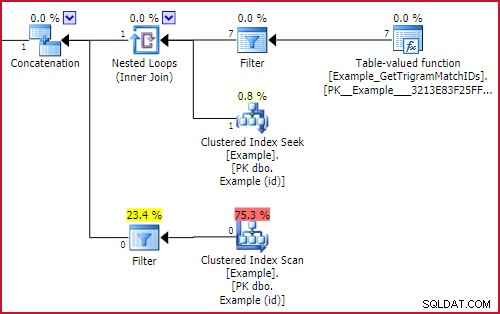
Efekt spouštěcího filtru
Buď
Example_GetTrigramMatchIDsbude provedena funkce (a výsledky vyhledány v příkladu pomocí hledání na id), nebo skenování sdruženého indexu příkladu se zbytkovýmLIKEpredikát poběží, ale ne obojí.Výkon
Následující kód testuje výkon trigramového vyhledávání proti ekvivalentnímu
LIKE:SET STATISTICS XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); SELECT F2.stringFROM dbo.Příklad AS F2WHERE F2.string LIKE '%1234%5678%'OPTION (MAXDOP 1); SELECT ElapsedMS =DATEDIFF(MILLISEKOND, @S, SYSUTCDATETIME());GOSET STATISTICS XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); SELECT ETS.stringFROM dbo.Example_TrigramSearch('%1234%5678%') AS ETS; SELECT ElapsedMS =DATEDIFF(MILISECOND, @S, SYSUTCDATETIME());Oba vytvářejí stejný výsledný řádek (řádky), ale
LIKEdotaz běží 2100 ms , zatímco hledání trigramu trvá 15 ms .Je možný ještě lepší výkon. Obecně se výkon zlepšuje, když se trigramy stávají selektivnějšími a jejich počet je nižší (pod maximem tří v této implementaci). Například:
SET STATISTICS XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); SELECT ETS.stringFROM dbo.Example_TrigramSearch('%BEEF%') AS ETS; SELECT ElapsedMS =DATEDIFF(MILISECOND, @S, SYSUTCDATETIME());Toto vyhledávání vrátilo 111 řádků do mřížky SSMS za 4 ms .
LIKEekvivalent běžel 1950 ms .Udržování trigramů
Pokud je cílová tabulka statická, zjevně není problém udržovat synchronizaci základní tabulky a související tabulky trigramů. Podobně, pokud není vyžadováno, aby výsledky vyhledávání byly vždy zcela aktuální, může dobře fungovat plánované obnovení tabulky (tabulek) trigramů.
Jinak můžeme použít některé docela jednoduché spouštěče, abychom udrželi data vyhledávání trigramů synchronizovaná se základními řetězci. Obecnou myšlenkou je generovat trigramy pro odstraněné a vložené řádky a poté je podle potřeby přidat nebo odstranit v tabulce trigramů. Níže uvedené spouštěče vložení, aktualizace a odstranění ukazují tuto myšlenku v praxi:
-- Udržovat trigramy po příkladu insertsCREATE TRIGGER MaintainTrigrams_AION dbo.ExampleAFTER INSERTASBEGIN IF @@ROWCOUNT =0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML')> 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Vložit související trigramy INSERT dbo.ExampleTrigrams (id, trigram) SELECT INS.id, GT.trigram FROM Vloženo JAKO INS CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;END;-- Udržovat trigramy po příkladu deleteCREATE TRIGGER MaintainTrigrams_ADON dbo.ExampleAFTER DELETEASBEGIN IF @@ROWCOUNT =0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML')> 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Smazané související trigramy DELETE ET WITH (SERIALIZABLE) Z Delete AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram =GT.trigram AND ET.id =DEL.id; KONEC;-- Udržovat trigramy po aktualizacích příkladuCREATE TRIGGER MaintainTrigrams_AUON dbo.ExampleAFTER UPDATEASBEGIN IF @@ROWCOUNT =0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML')> 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Smazané související trigramy DELETE ET WITH (SERIALIZABLE) Z Delete AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram =GT.trigram AND ET.id =DEL.id; -- Vložit související trigramy INSERT dbo.ExampleTrigrams (id, trigram) SELECT INS.id, GT.trigram FROM Vloženo JAKO INS CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;END;Spouštěče jsou docela efektivní a zvládnou změny v jednom i více řádcích (včetně více akcí dostupných při použití
MERGEprohlášení). Indexovaný pohled na tabulku trigramů bude automaticky udržován SQL Serverem, aniž bychom museli psát jakýkoli spouštěcí kód.Operace spouštění
Jako příklad spusťte příkaz k odstranění libovolného řádku z tabulky Příklad:
-- Jeden řádek deleteDELETE TOP (1) dbo.Example;Plán provádění po spuštění (skutečného) obsahuje záznam pro spouštěč po odstranění:
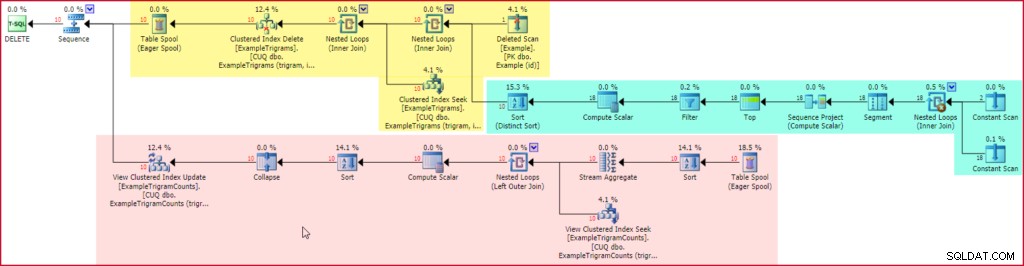
Smazat plán provádění spouštěče
Žlutá část plánu čte řádky z smazaných pesudo-table, vygeneruje trigramy pro každý odstraněný řetězec příkladu (pomocí známého plánu zvýrazněného zeleně), poté vyhledá a smaže související položky tabulky trigramů. Poslední část plánu, zobrazená červeně, je automaticky přidána serverem SQL, aby byl indexovaný pohled aktuální.
Plán pro vkládací spoušť je velmi podobný. Aktualizace se zpracovávají provedením odstranění následovaného vložením. Spusťte následující skript, abyste viděli tyto plány a ověřili, že pomocí funkce vyhledávání trigramů lze najít nové a aktualizované řádky:
-- Jednořádkový insertINSERT dbo.Příklad (řetězec) VALUES ('SQLPerformance.com'); -- Najděte nový řádekSELECT ETS.stringFROM dbo.Example_TrigramSearch('%perf%') AS ETS; -- Aktualizace jednoho řádku UPDATE TOP (1) dbo. Příklad SET string ='12345678901234567890'; -- Víceřádkový insertINSERT dbo.Příklad WITH (TABLOCKX) (řetězec)SELECT TOP (1000) REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') + RIGHT(NEWID(), 10)OD master.dbo.spt_values AS SV1; -- Víceřádková aktualizaceUPDATE TOP (1000) dbo.Příklad SET string ='12345678901234567890'; -- Vyhledejte aktualizované řádkySELECT ETS.string FROM dbo.Example_TrigramSearch('12345678901234567890') AS ETS;Příklad sloučení
Další skript ukazuje
MERGEpříkaz používaný k vložení, odstranění a aktualizaci tabulky Příklad najednou:-- MERGE demoDECLARE @MergeData tabulka ( id integer UNIQUE CLUSTERED NULL, operace char(3) NOT NULL, string char(20) NULL); INSERT @MergeData (id, operace, řetězec) VALUES (NULL, 'INS', '11223344556677889900'), -- Vložit (1001, 'DEL', NULL), -- Smazat (2002, 'UPD', '000000000000)'000000000000; -- Aktualizujte tabulku DECLARE @Actions ( action$ nvarchar(10) NOT NULL, old_id integer NULL, old_string char(20) NULL, new_id integer NULL, new_string char(20) NULL); SLOUČIT dbo.Příklad JAKO EUSING @MergeData JAKO MD NA MD.id =E.idWHEN MATCHED AND MD.operation ='DEL' THEN DELETEWHEN MATCHED AND MD.operation ='UPD' THEN UPDATE SET E.string =MD.stringWHEN MATCHEN A MD.operation ='INS' POTOM VLOŽTE (řetězec) HODNOTY (MD.string)VÝSTUP $akce, Deleted.id, Deleted.string, Inserted.id, Inserted.stringINTO @Actions (akce$, old_id, old_string, new_id, nový_řetězec); SELECT * FROM @Actions AS A;Výstup zobrazí něco jako:

Výstup akce
Poslední myšlenky
Možná existuje určitý prostor pro urychlení velkých operací mazání a aktualizace přímým odkazováním na ID namísto generování trigramů. Toto zde není implementováno, protože by to vyžadovalo nový neclusterovaný index v tabulce trigramů, čímž by se zdvojnásobil (již významný) použitý úložný prostor. Tabulka trigramů obsahuje jedno celé číslo a
char(3)na řádek; neshlukovaný index na celočíselném sloupci by získalchar(3)sloupec na všech úrovních (s laskavým svolením seskupeného indexu a potřeba, aby indexové klíče byly jedinečné na každé úrovni). Je také třeba zvážit prostor v paměti, protože vyhledávání trigramů funguje nejlépe, když jsou všechna čtení z mezipaměti.Díky dodatečnému indexu by se kaskádová referenční integrita stala možností, ale to je často větší problém, než by stálo za to.
Hledání trigramů není všelék. Dodatečné požadavky na úložiště, složitost implementace a dopad na výkon aktualizací, to vše silně zatěžuje. Tato technika je také nepoužitelná pro vyhledávání, která negenerují žádné trigramy (minimálně 3 znaky). Ačkoli zde uvedená základní implementace dokáže zpracovat mnoho typů vyhledávání (začíná, obsahuje, končí, více zástupnými znaky), nepokrývá všechny možné vyhledávací výrazy, které lze nastavit tak, aby fungovaly s
LIKE. Funguje dobře pro vyhledávací řetězce, které generují trigramy typu AND; více práce je potřeba pro zpracování vyhledávacích řetězců, které vyžadují zpracování typu OR nebo pokročilejší možnosti, jako jsou regulární výrazy.Vše, co je řečeno, pokud vaše aplikace skutečně musí mají rychlé vyhledávání zástupných řetězců, n-gramy jsou něco, co je třeba vážně zvážit.
Související obsah:Jeden způsob, jak získat vyhledávání indexu pro přední %wildcard od Aarona Bertranda.