Operátory ROLLUP a CUBE se používají k vrácení výsledků agregovaných podle sloupců v klauzuli GROUP BY.
Funkce GROUPING a GROUPING_ID se používají k identifikaci, zda jsou sloupce v seznamu GROUP BY agregovány (pomocí operátorů ROLLUP nebo CUBE) či nikoli.
Mezi funkcemi GROUPING a GROUPING_ID jsou dva hlavní rozdíly.
Jsou následující:
- Funkci GROUPING lze použít na jeden sloupec, zatímco seznam sloupců pro funkci GROUPING_ID musí odpovídat seznamu sloupců v klauzuli GROUP BY.
- Funkce GROUPING označuje, zda je sloupec v seznamu GROUP BY agregován či nikoli. Vrátí 1, pokud je sada výsledků agregována, a 0, pokud sada výsledků není agregována.
Na druhou stranu funkce GROUPING_ID také vrací celé číslo. Po zřetězení výsledků všech funkcí SKUPENÍ však provede převod z binární na desítkové.
V tomto článku na příkladech uvidíme funkce GROUPING a GROUPING_ID v akci.
Příprava některých fiktivních dat
Jako vždy vytvoříme fiktivní data, která použijeme pro příklad, se kterým budeme pracovat v tomto článku.
Spusťte následující skript:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
Ve výše uvedeném skriptu jsme vytvořili databázi s názvem „Společnost“. Následně jsme v rámci firemní databáze vytvořili tabulku „Zaměstnanec“. Nakonec jsme do tabulky Zaměstnanci vložili nějaké fiktivní záznamy.
Funkce SKUPENÍ
Jak bylo uvedeno výše, funkce GROUPING vrátí 1, pokud je sada výsledků agregována, a 0, pokud sada výsledků není agregována.
Podívejte se na následující skript, abyste viděli funkci SKUPENÍ v akci.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
Výše uvedený skript počítá součet platů všech zaměstnanců a zaměstnankyň, které jsou seskupeny nejprve podle sloupce Oddělení a poté podle sloupce Pohlaví. Byly přidány další dva sloupce pro zobrazení výsledku funkce SKUPENÍ aplikované na sloupce Oddělení a Pohlaví.
Operátor ROLLUP se používá k zobrazení součtu platů ve formě celkových a mezisoučtů.
Výstup skriptu výše vypadá takto.
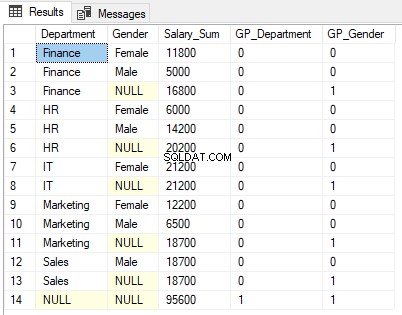
Podívejte se pozorně na výstup. Součet mezd je zobrazen podle pohlaví podle pohlaví oddělení (řádky 1, 2, 4, 5, 7, 9, 10 a 12). Potom se také agreguje pouze podle pohlaví (řádky 3, 6, 8, 11 a 13). Nakonec je na řádku 14 uveden celkový součet platů agregovaných podle oddělení a pohlaví.
1 se zobrazí ve sloupci funkce GROUPING GP_Gender pro řádky, kde jsou výsledky agregovány podle pohlaví, tj. řádky 3, 6, 8, 11 a 13. Je to proto, že sloupec GP_Gender obsahuje výsledek funkce GROUPING aplikované na sloupec Gender.
Podobně řádek 14 obsahuje agregovaný součet všech oddělení a všech sloupců. Proto je vrácena hodnota 1 pro sloupce GP_Department i GP_Gender.
Ve výstupu, kde jsou agregovány výsledky, můžete vidět, že se ve sloupcích Oddělení a Pohlaví zobrazuje NULL. Například na řádku 3 je ve sloupci Pohlaví zobrazena hodnota NULL, protože výsledky jsou agregovány podle sloupce pohlaví, takže neexistuje žádná hodnota sloupce k zobrazení. Nechceme, aby naši uživatelé viděli NULL, lepší slovo by zde mohlo být „Všechny pohlaví“.
K tomu musíme upravit náš skript následovně:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
Pokud ve výše uvedeném skriptu funkce SKUPENÍ použitá na sloupec Oddělení vrátí 1 a ve sloupci Oddělení se zobrazí „Všechna oddělení“. V opačném případě, pokud sloupec Oddělení obsahuje hodnotu NULL, zobrazí se „Neznámé“. Sloupec pohlaví byl upraven stejným způsobem.
Spuštění skriptu výše vrátí následující výsledky:
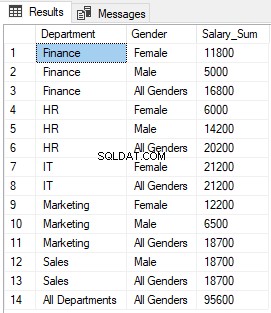
Můžete vidět, že NULL ve sloupcích Oddělení a Pohlaví, kde funkce GROUPING vrací 1, byla nahrazena hodnotami „Všechna oddělení“ a „Všechna pohlaví“.
Funkce GROUPING_ID
Funkce GROUPING_ID zřetězí výstup funkcí GROUPING aplikovaných na všechny sloupce uvedené v klauzuli GROUP BY. Poté provede převod z binárního na desítkové, než vrátí konečný výstup.
Pojďme nejprve zřetězit výstup vrácený funkcí GROUPING aplikovanou na sloupce Oddělení a Pohlaví. Podívejte se na následující skript:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
Na výstupu uvidíte 0s a 1s vrácené funkcí GROUPING spojené dohromady. Výstup vypadá takto:
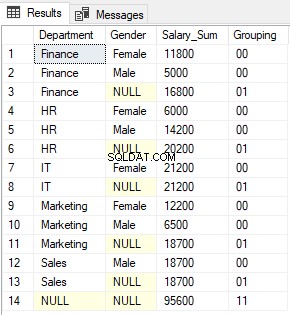
Funkce GROUPING_ID jednoduše vrací dekadický ekvivalent binární hodnoty vytvořené jako výsledek zřetězení hodnot vrácených funkcemi GROUPING.
Spusťte následující skript, abyste viděli funkci GROUPING ID v akci:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
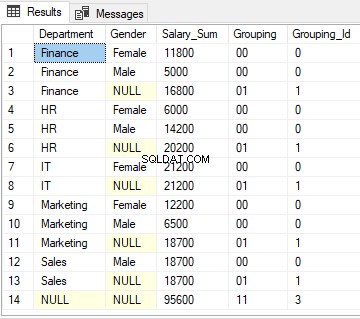
Pro řádek 1 vrátí funkce GROUPING ID 0, protože desítkový ekvivalent „00“ je nula.
Pro řádky 3, 6, 8, 11 a 13 funkce GROUPING_ID vrátí 1, protože desítkový ekvivalent ‚01‘ je 1.
Nakonec pro řádek 14 funkce GROUPIND_ID vrátí 3, protože binární ekvivalent ‚11‘ je 3.
Výstup skriptu výše vypadá takto:
Viz také:
Microsoft:Přehled Grouping_ID
Microsoft:Přehled seskupení
YouTube:Grouping &Grouping_ID