Indexy zvyšují rychlost v SQL databázích. Mohou být seskupené nebo neshlukované. Ale co to znamená a kde byste měli každý použít?
Znám ten pocit. Byl jsem tam. Začátečníci jsou často zmateni, který index použít pro které sloupce. I odborníci však musí tuto otázku před rozhodnutím důkladně promyslet a různé situace vyžadují různá rozhodnutí. Jak uvidíte později, existují dotazy, kde bude seskupený index svítit ve srovnání s indexem bez seskupení a naopak.
Nejprve však musíme každého z nich poznat. Pokud hledáte stejné informace, dnes je váš šťastný den.
Tento článek vám řekne, co tyto indexy jsou a kdy je použít. Samozřejmostí budou ukázky kódu, které si můžete vyzkoušet v praxi. Takže si vezměte brambůrky nebo pizzu a trochu sody nebo kávy a připravte se ponořit se do této poutavé cesty.
Jste připraveni?
Co je seskupený index
Clusterový index je index, který definuje fyzické pořadí řazení řádků v tabulce nebo pohledu.
Chcete-li to vidět ve skutečné podobě, vezměme si Zaměstnanec tabulky v AdventureWorks2017 databáze.
Primární klíč je také klastrovaný index a klíč je založen na BusinessEntityID sloupec. Když na této tabulce provedete SELECT bez ORDER BY, uvidíte, že je seřazená podle primárního klíče.
Vyzkoušejte si to sami pomocí kódu níže:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Nyní se podívejte na výsledek na obrázku 1:
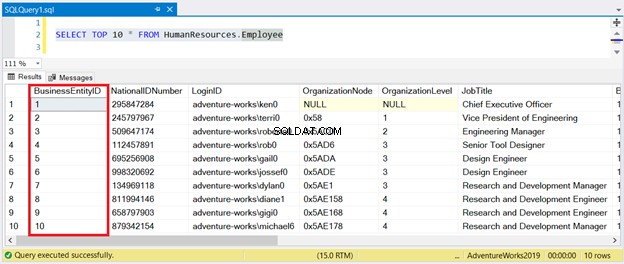
Jak vidíte, sadu výsledků nemusíte třídit pomocí BusinessEntityID . Klastrovaný index se o to postará.
Na rozdíl od neklastrovaných indexů můžete mít pouze 1 seskupený index na tabulku. Co kdybychom to zkusili na Zaměstnanci stůl?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Máme podobnou chybu níže:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Kdy použít seskupený index?
Sloupec je nejlepším kandidátem na seskupený index, pokud platí jedna z následujících podmínek:
- Používá se ve velkém počtu dotazů v klauzuli WHERE a spojeních.
- Bude použit jako cizí klíč k jiné tabulce a nakonec ke spojení.
- Jedinečné hodnoty sloupců.
- Hodnota se s menší pravděpodobností změní.
- Tento sloupec se používá k dotazování na rozsah hodnot. Operátory jako>, <,>=, <=nebo BETWEEN se používají se sloupcem v klauzuli WHERE.
Ale seskupené indexy nejsou dobré, pokud sloupec nebo sloupce
- často měnit
- jsou široké klávesy nebo kombinace sloupců s velkou klávesou.
Příklady
Seskupené indexy lze vytvořit pomocí kódu T-SQL nebo jakéhokoli nástroje GUI serveru SQL Server. Můžete to udělat v T-SQL po vytvoření tabulky takto:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Nebo to můžete udělat pomocí ALTER TABLE po vytvoření tabulky bez seskupeného indexu:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Dalším způsobem je použití CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Další alternativou je použití nástroje SQL Server, jako je SQL Server Management Studio nebo dbForge Studio pro SQL Server.
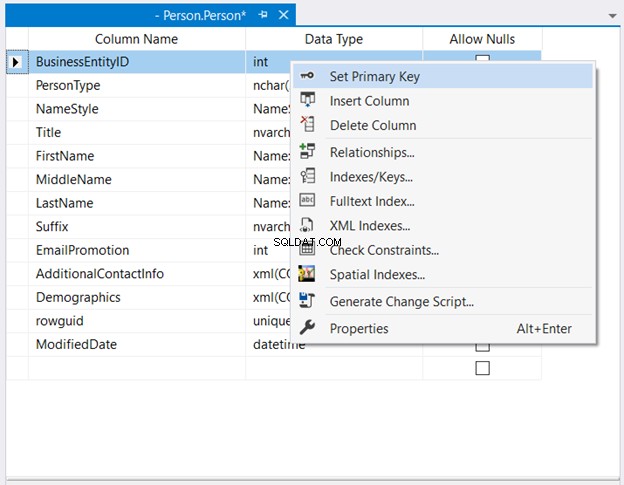
V Průzkumníku objektů , rozbalte databázi a uzly tabulky. Poté klikněte pravým tlačítkem na požadovanou tabulku a vyberte Návrh . Nakonec klikněte pravým tlačítkem na sloupec, který chcete použít jako primární klíč> Nastavit primární klíč> Uložte změny do tabulky.
Obrázek 2 níže ukazuje umístění BusinessEntityID je nastaven jako primární klíč.
Kromě vytváření klastrovaného indexu s jedním sloupcem můžete použít více sloupců. Viz příklad v T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Po vytvoření tohoto seskupeného indexu Osoba tabulka bude fyzicky řazena podle Příjmení , Jméno a MiddleName .
Jednou z výhod tohoto přístupu je lepší výkon dotazů na základě názvu. Kromě toho seřadí výsledky podle názvu bez zadání ORDER BY. Všimněte si však, že pokud se název změní, bude nutné tabulku přeskupit. I když se to nestane každý den, dopad může být obrovský, pokud je stůl velmi velký.
Co je neshlukovaný index
Neklastrovaný index je index s klíčem a ukazatelem na řádky nebo klíče seskupeného indexu. Tento index lze použít pro tabulky i pohledy.
Na rozdíl od seskupených indexů je zde struktura oddělená od tabulky. Protože je samostatný, potřebuje ukazatel na řádky tabulky, který se také nazývá lokátor řádků. Každý záznam v indexu bez klastrů tedy obsahuje lokátor a hodnotu klíče.
Neklastrované indexy fyzicky netřídí tabulku na základě klíče.
Indexové klíče pro indexy bez klastrů mají maximální velikost 1700 bajtů. Tento limit můžete obejít přidáním zahrnutých sloupců. Tato metoda je dobrá, pokud váš dotaz potřebuje pokrýt více sloupců bez zvětšení velikosti klíče.
Můžete také vytvořit filtrované indexy bez klastrů. To sníží náklady na údržbu indexu a úložiště a zároveň zlepší výkon dotazů.
Kdy použít neshlukovaný index?
Sloupec nebo sloupce jsou vhodnými kandidáty pro indexy bez klastrů, pokud platí následující:
- Sloupec nebo sloupce se používají v klauzuli WHERE nebo spojení.
- Dotaz nevrátí velkou sadu výsledků.
- Je potřeba přesná shoda v klauzuli WHERE pomocí operátoru rovnosti.
Příklady
Tento příkaz vytvoří jedinečný, neseskupený index v Zaměstnanec tabulka:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Kromě tabulky můžete pro zobrazení vytvořit index bez klastrů:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Další běžné otázky a uspokojivé odpovědi
Jaké jsou rozdíly mezi seskupeným a neshlukovaným indexem?
Z toho, co jste viděli dříve, si již můžete vytvořit představu o tom, jak se liší seskupené a neseskupené indexy. Ale pojďme to mít na stole pro snadnou orientaci.
| Informace | Shlukovaný index | Neshlukovaný index |
| Platí pro | Tabulky a zobrazení | Tabulky a zobrazení |
| Povoleno pro tabulku | 1 | 999 |
| Velikost klíče | 900 bajtů | 1700 bajtů |
| Sloupce na klíč indexu | 32 | 32 |
| Dobré pro | Dotazy na rozsah (>,<,>=, <=, BETWEEN) | Přesné shody (=) |
| Neklíčové zahrnuté sloupce | Není povoleno | Povoleno |
| Filtrovat s podmínkou | Není povoleno | Povoleno |
Měly by být primární klíče seskupený nebo neshlukovaný index?
Primární klíč je omezení. Jakmile ze sloupce uděláte primární klíč, automaticky se z něj vytvoří seskupený index, pokud již neexistuje existující seskupený index.
Nepleťte si primární klíč s seskupeným indexem! Primárním klíčem může být také seskupený indexový klíč. Klastrovaný indexový klíč však může být jiný sloupec než primární klíč.
Vezměme si další příklad. V části Osoba tabulka AdventureWorks201 7, máme BusinessEntityID primární klíč. Je to také seskupený indexový klíč. Tento seskupený index můžete zrušit. Poté vytvořte seskupený index založený na Příjmení , Jméno a Prostřední jméno . Primárním klíčem je stále BusinessEntityID sloupec.
Ale měly by být vaše primární klíče vždy seskupené?
Záleží. Znovu se vraťte k otázce, kdy použít seskupený index.
Pokud se sloupec nebo sloupce objeví v klauzuli WHERE ve velkém množství dotazů, je to kandidát na seskupený index. Dalším aspektem je však to, jak široký je seskupený indexový klíč. Příliš široký – a velikost každého neseskupeného indexu se zvýší, pokud existují. Pamatujte, že indexy bez klastrů také používají klíč seskupeného indexu jako ukazatel. Udržujte svůj seskupený indexový klíč co nejužší.
Pokud velký počet dotazů používá primární klíč v klauzuli WHERE, ponechte jej také jako seskupený indexový klíč. Pokud ne, vytvořte svůj primární klíč jako index bez klastrů.
Ale co když si stále nejste jisti? Potom můžete posoudit výkonnostní přínos sloupce, když je klastrovaný nebo bez klastrů. Takže se nalaďte na další sekci o tom.
Co je rychlejší:seskupený nebo neshlukovaný index?
Dobrá otázka. Neexistuje žádné obecné pravidlo. Musíte zkontrolovat logická čtení a plán provádění vašich dotazů.
Náš krátký experiment bude zahrnovat kopie následujících tabulek z AdventureWorks2017 databáze:
- Osoba
- BusinessEntityAddress
- Adresa
- Typ adresy
Zde je skript:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Pomocí výše uvedené struktury porovnáme rychlosti dotazů pro klastrované a neklastrované indexy.
Máme 2 kopie Osoby stůl. První bude používat BusinessEntityID jako primární a seskupený indexový klíč. Druhý stále používá BusinessEntityID jako primární klíč. Seskupený index je založen na Příjmení , Jméno , Prostřední jméno a Přípona .
Začněme.
DOTAZY PŘESNÉ SHODY NA ZÁKLADĚ PŘÍJMENÍ
Nejprve si položme jednoduchý dotaz. Také je potřeba zapnout STATISTICS IO. Poté výsledky vložíme na stránku statisticsparser.com pro tabulkovou prezentaci.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Očekává se, že první SELECT bude pomalejší, protože klauzule WHERE neodpovídá klíči seskupeného indexu. Ale podívejme se na logická čtení.
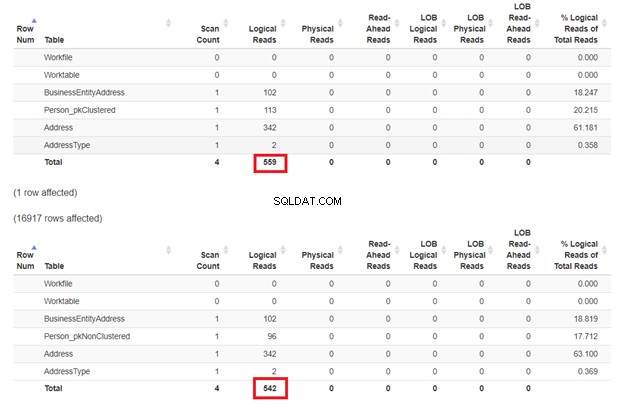
Jak se očekává na obrázku 3, Person_pkClustered měl logičtější čtení. Dotaz proto potřebuje více I/O. Důvod? Tabulka je řazena podle BusinessEntityID . Přesto má druhá tabulka seskupený index založený na názvu. Protože dotaz vyžaduje výsledek založený na názvu, Person_pkNonClustered vyhrává. Čím méně logických čtení, tím rychlejší je dotaz.
co se ještě děje? Podívejte se na obrázek 4.
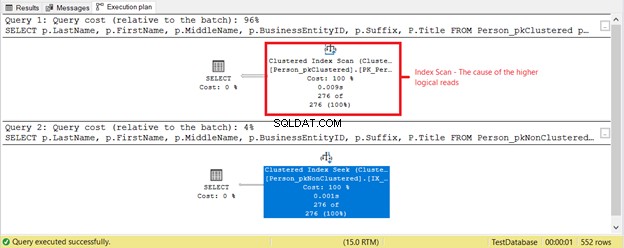
Stalo se něco jiného na základě prováděcího plánu na obrázku 4. Proč je Clustered Index Scan v prvním SELECT místo hledání indexu? Viníkem je Titul ve sloupci SELECT. Není pokryta žádným ze stávajících indexů. Optimalizátor SQL Server považoval za rychlejší použít clusterovaný index založený na BusinessEntityID. Poté jej SQL Server naskenoval na správná příjmení a získal křestní jméno, druhé jméno a titul.
Odeberte Název a použitý operátor bude Vyhledávání indexu . Proč? Protože zbývající pole jsou pokryta neshlukovaným indexem založeným na Příjmení , Jméno , Prostřední jméno a Přípona . Zahrnuje také BusinessEntityID jako lokátor seskupeného indexového klíče.
DOTAZ NA ROZSAH ZALOŽENÝ NA ID OBCHODNÍ ENTITY
Seskupené indexy mohou být dobré pro dotazy na rozsah. Je tomu tak vždy? Pojďme to zjistit pomocí níže uvedeného kódu.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Zápis potřebuje řádky založené na rozsahu IDs BusinessEntityID od 285 do 290. Opět platí, že seskupené a neseskupené indexy 2 tabulek jsou nedotčené. Nyní se podívejme na logické čtení na obrázku 5. Očekávaný vítěz je Person_pkClustered protože primární klíč je také seskupený indexový klíč.

Vidíte nižší logické čtení na Person_pkClustered ? Seskupené indexy se v tomto scénáři osvědčily při dotazech na rozsah. Podívejme se, co dalšího prováděcí plán odhalí na obrázku 6.
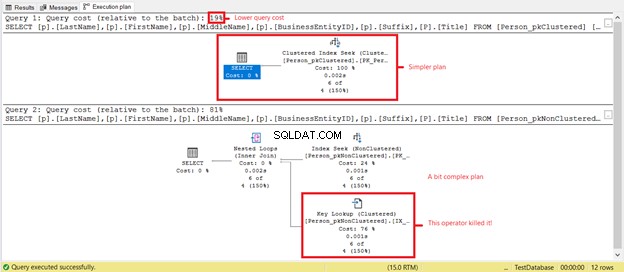
První SELECT má jednodušší plán a nižší náklady na dotaz na základě obrázku 7. To také podporuje nižší logické čtení. Mezitím druhý SELECT má operátor vyhledávání klíčů, který zpomaluje dotaz. Viník? Opět je to Titul sloupec. Odeberte sloupec v dotazu nebo jej přidejte jako zahrnutý sloupec v indexu bez klastrů. Pak budete mít lepší plán a nižší logické čtení.
DOTAZOVAT SE PŘESNÉ SHODY S PŘIPOJENÍM
Mnoho příkazů SELECT obsahuje spojení. Udělejme si nějaké testy. Zde začínáme přesnými shodami:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Očekáváme, že druhý SELECT z Person_pkNonClustered s seskupeným indexem na názvu bude mít méně logických čtení. Ale je to tak? Viz obrázek 7.
Vypadá to, že neseskupený index na názvu fungoval dobře. Logická čtení jsou stejná. Pokud zkontrolujete plán provádění, rozdíl v operátorech je Clustered Index Seek na Person_pkNonClustered a hledání indexu na Person_pkClustered .
Takže musíme zkontrolovat logická čtení a plán provádění, abychom si byli jisti.
DOTAZ NA ROZSAH S PŘIPOJENÍM
Protože se naše očekávání mohou lišit od skutečnosti, zkusme to pomocí dotazů na rozsah. Klastrované indexy jsou s tím obecně dobré. Ale co když přidáte připojení?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Nyní zkontrolujte logická čtení těchto 2 dotazů na obrázku 8:
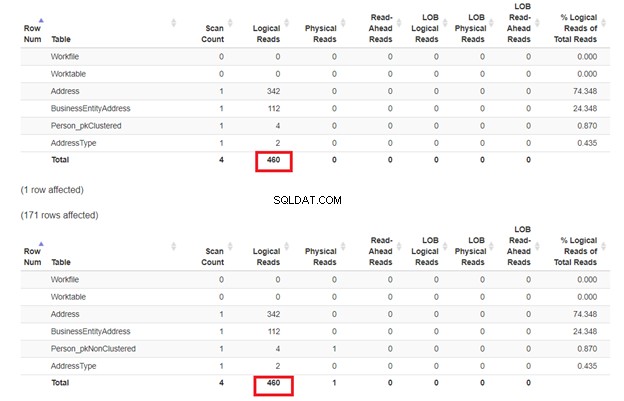
Co se stalo? Na obrázku 9 realita kousne na Person_pkClustered . V porovnání s Person_pkNonClustered byly pozorovány vyšší I/O náklady . To se liší od toho, co očekáváme. Ale na základě této odpovědi na fóru může být hledání indexu bez clusterů rychlejší než hledání indexu s clustery, když jsou všechny sloupce v dotazu 100% pokryty indexem. V našem případě dotaz na Person_pkNonClustered pokryl sloupce pomocí neklastrovaného indexu (BusinessEntityID – klíč; Příjmení , Jméno , Prostřední jméno , Přípona – ukazatel na seskupený indexový klíč).
VLOŽTE VÝKON
Potom zkuste otestovat výkon INSERT na stejných tabulkách.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Obrázek 9 ukazuje logické čtení INSERT:

Oba generovaly stejné I/O. Oba tedy předvedli totéž.
SMAZAT VÝKON
Náš poslední test zahrnuje DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Obrázek 10 ukazuje logická čtení. Všimněte si rozdílu.

Proč máme vyšší logické čtení na Person_pkClustered ? Jde o to, že podmínka příkazu DELETE je založena na přesné shodě jména. Optimalizátor se bude muset nejprve uchýlit k indexu bez klastrů. Znamená to více I/O. Potvrďte pomocí prováděcího plánu na obrázku 11.
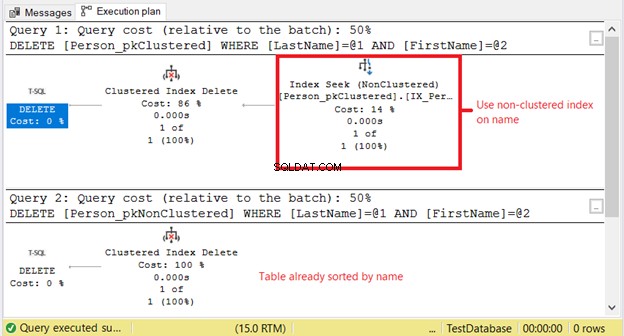
První SELECT potřebuje hledání indexu na indexu bez klastrů. Důvodem je klauzule WHERE na Příjmení a Jméno . Mezitím Person_pkNonClustered je již fyzicky seřazeno podle názvu z důvodu seskupeného indexu.
Takové věci
Vytváření vysoce výkonných dotazů není o štěstí. Nemůžete jen vložit seskupený a neshlukovaný index a pak najednou budou vaše dotazy mít rychlostní sílu. Tyto nástroje musíte nadále používat jako objektiv, abyste mohli zaostřit na jiné malé detaily, než je sada výsledků.
Ale někdy na to všechno prostě nemáte čas. myslím, že je to normální. Ale pokud toho tolik nepokazíte, máte práci druhý den a můžete ji vyřešit. Zpočátku to nebude snadné. Ve skutečnosti to bude matoucí. Budete mít také spoustu otázek. Ale neustálým cvičením toho můžete dosáhnout. Takže bradu vzhůru.
Pamatujte, že klastrované i neklastrované indexy slouží k posílení dotazů. Znalost klíčových rozdílů, scénářů použití a nástrojů vám pomůže při hledání kódování vysoce výkonných dotazů.
Doufám, že tento příspěvek odpoví na vaše nejnaléhavější otázky týkající se seskupených a neshlukovaných indexů. Chcete pro naše čtenáře ještě něco dodat? Sekce Komentáře je otevřená.
A pokud shledáte tento příspěvek poučným, sdílejte jej prosím na svých oblíbených platformách sociálních médií.
Další informace o indexech a výkonu dotazů jsou v níže uvedených článcích:
- 22 šikovných příkladů indexu SQL pro zrychlení vašich dotazů
- Optimalizace dotazů SQL:5 základních faktů pro zvýšení počtu dotazů