Kvalita prováděcího plánu je vysoce závislá na přesnosti odhadovaného počtu výstupů řádků každým operátorem plánu. Pokud je odhadovaný počet řádků výrazně zkreslený od skutečného počtu řádků, může to mít významný dopad na kvalitu plánu provádění dotazu. Špatná kvalita plánu může být zodpovědná za nadměrné I/O, přetížení CPU, tlak na paměť, sníženou propustnost a sníženou celkovou souběžnost.
„Kvalitou plánu“ – mluvím o tom, že SQL Server generuje plán provádění, jehož výsledkem jsou volby fyzického operátora, které odrážejí aktuální stav dat. Při rozhodování na základě přesných dat je větší šance, že dotaz bude fungovat správně. Odhadované hodnoty mohutnosti se používají jako vstup pro kalkulaci nákladů operátora, a když jsou hodnoty příliš vzdálené realitě, může být vysloven negativní dopad na prováděcí plán. Tyto odhady jsou přiváděny do různých modelů nákladů souvisejících se samotným dotazem a špatné odhady řádků mohou ovlivnit řadu rozhodnutí včetně výběru indexu, operací vyhledávání vs. skenování, paralelního a sériového provádění, výběru algoritmu spojení, vnitřního vs. vnějšího fyzického spojení. výběr (např. sestavení vs. sonda), generování zařazování, vyhledávání záložek vs. úplný klastrový nebo haldový přístup k tabulce, výběr streamu nebo hash agregace a zda modifikace dat používá široký nebo úzký plán.
Jako příklad řekněme, že máte následující SELECT dotaz (pomocí Úvěrové databáze):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
Je na základě logiky dotazu následující tvar plánu takový, jaký byste očekávali?
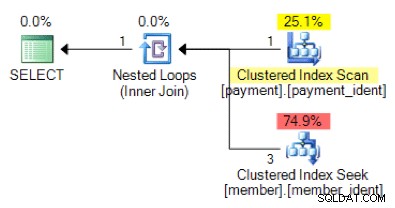
A co tento alternativní plán, kde místo vnořené smyčky máme hash match?
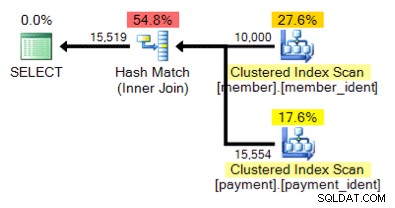
„Správná“ odpověď závisí na několika dalších faktorech – ale jedním z hlavních faktorů je počet řádků v každé z tabulek. V některých případech je jeden algoritmus fyzického spojení vhodnější než druhý – a pokud počáteční předpoklady odhadu mohutnosti nejsou správné, váš dotaz možná používá neoptimální přístup.
Identifikace problém odhadu mohutnosti je relativně jednoduchý. Pokud máte skutečný plán provádění, můžete porovnat odhadované a skutečné hodnoty počtu řádků pro operátory a hledat zkreslení. SQL Sentry Plan Explorer zjednodušuje tento úkol tím, že vám umožňuje vidět skutečné a odhadované řádky pro všechny operátory na jediné záložce stromu plánu oproti nutnosti najíždět na jednotlivé operátory v grafickém plánu:

Zkreslení ne vždy vede ke špatné kvalitě plánů, ale pokud máte problémy s výkonem dotazu a takové zkreslení v plánu vidíte, je to oblast, která si pak zaslouží další prozkoumání.
Identifikace problémů s odhadem mohutnosti je relativně přímočará, ale řešení často ne. Existuje řada základních příčin, proč mohou nastat problémy s odhadem mohutnosti, a v tomto příspěvku se budu zabývat deseti běžnými důvody.
Chybí nebo zastaralé statistiky
Ze všech důvodů problémů s odhadem mohutnosti je to ten, ve který doufáte vidět, protože je často nejsnáze řešitelné. V tomto scénáři vaše statistiky buď chybí, nebo jsou zastaralé. Můžete mít vypnuté možnosti databáze pro automatické vytváření statistik a aktualizace, pro konkrétní statistiky povoleno „no recomputed“ nebo máte dostatečně velké tabulky, že vaše automatické aktualizace statistik prostě neprobíhají dostatečně často.
Problémy se vzorkováním
Je možné, že přesnost statistického histogramu je nedostatečná – například pokud máte velmi velkou tabulku s významnými a/nebo častými zkresleními dat. Možná budete muset změnit vzorkování z výchozího nastavení, nebo pokud ani to nepomůže – prozkoumejte pomocí samostatných tabulek, filtrovaných statistik nebo filtrovaných indexů.
Korelace skrytých sloupců
Optimalizátor dotazů předpokládá, že sloupce ve stejné tabulce jsou nezávislé. Pokud máte například sloupec města a státu, můžeme intuitivně vědět, že tyto dva sloupce spolu souvisí, ale SQL Server tomu nerozumí, pokud mu nepomůžeme přidruženým vícesloupcovým indexem nebo ručně vytvořeným vícesloupcovým indexem. sloupcová statistika. Bez pomoci optimalizátoru s korelací může být selektivita vašich predikátů přehnaná.
Níže je uveden příklad dvou korelovaných predikátů:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
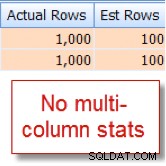
Náhodou vím, že 10 % z našich 10 000 řádků member tabulka se kvalifikuje pro tuto kombinaci, ale optimalizátor dotazů odhaduje, že jde o 1 % z 10 000 řádků:
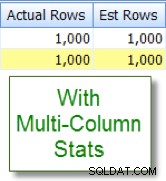
Nyní to porovnejte s příslušným odhadem, který vidím po přidání vícesloupcové statistiky:
Porovnání sloupců uvnitř tabulky
Problémy s odhadem mohutnosti mohou nastat při porovnávání sloupců ve stejné tabulce. Toto je známý problém. Pokud to musíte udělat, můžete zlepšit odhady mohutnosti porovnání sloupců tím, že místo toho použijete vypočítané sloupce nebo přepíšete dotaz tak, aby používal vlastní spojení nebo běžné tabulkové výrazy.
Využití proměnných tabulky
Používáte hodně tabulkové proměnné? Proměnné tabulky vykazují odhad mohutnosti „1“ – což pro malý počet řádků nemusí být problém, ale u velkých nebo nestálých sad výsledků může významně ovlivnit kvalitu plánu dotazů. Níže je snímek obrazovky s odhadem operátora na 1 řádek oproti skutečným 1 600 000 řádkům z @charge proměnná tabulky:

Pokud je toto vaše hlavní příčina, bylo by vhodné prozkoumat alternativy, jako jsou dočasné tabulky nebo trvalé pracovní tabulky, kde je to možné.
Skalární a MSTV UDF
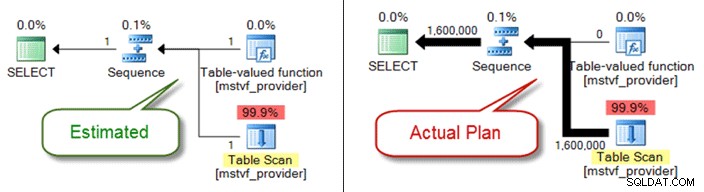
Podobně jako tabulkové proměnné jsou vícepříkazové tabulkové a skalární funkce černou skříňkou z hlediska odhadu mohutnosti. Pokud kvůli nim narazíte na problémy s kvalitou plánu, zvažte jako alternativu funkce vložené tabulky – nebo dokonce úplně vytáhněte odkaz na funkci a pouze odkazujte přímo na objekty.
Níže ukazuje odhadovaný versus skutečný plán při použití vícepříkazové tabulkové funkce:
Problémy s datovými typy
Problémy s implicitními datovými typy ve spojení s podmínkami vyhledávání a spojení mohou způsobit problémy s odhadem mohutnosti. Mohou také tajně požírat zdroje na úrovni serveru (CPU, I/O, paměť), takže je důležité je řešit, kdykoli je to možné.
Složité predikáty
S tímto vzorem jste se již pravděpodobně setkali – dotaz s WHERE klauzule, která má každý odkaz na sloupec tabulky zabalený do různých funkcí, operací zřetězení, matematických operací a dalších. A i když ne všechny zalamování funkcí vylučuje správné odhady mohutnosti (například pro LOWER , UPPER a GETDATE ) existuje mnoho způsobů, jak pohřbít váš predikát do té míry, že optimalizátor dotazů již nebude moci provádět přesné odhady.
Složitost dotazu
Podobně jako u pohřbených predikátů jsou vaše dotazy mimořádně složité? Uvědomuji si, že „komplexní“ je subjektivní pojem a vaše hodnocení se může lišit, ale většina se shodne na tom, že vnořování pohledů do pohledů v pohledech, které odkazují na překrývající se tabulky, pravděpodobně nebude optimální – zvláště ve spojení s více než 10 spojeními tabulek, funkčními odkazy a pohřbené predikáty. Přestože optimalizátor dotazů odvádí obdivuhodnou práci, není to žádná magie, a pokud máte výrazné zkreslení, složitost dotazu (dotazy švýcarského nože) zcela jistě znemožní odvodit přesné odhady řádků pro operátory.
Distribuované dotazy
Používáte distribuované dotazy s propojenými servery a vidíte významné problémy s odhadem mohutnosti? Pokud ano, nezapomeňte zkontrolovat oprávnění spojená s propojeným objektem serveru, který se používá pro přístup k datům. Bez minimálního db_ddladmin opravena databázová role pro účet propojeného serveru, tato nedostatečná viditelnost pro vzdálené statistiky kvůli nedostatečným oprávněním může být zdrojem vašich problémů s odhadem mohutnosti.
A jsou tu další…
Existují další důvody, proč mohou být odhady mohutnosti zkreslené, ale věřím, že jsem popsal ty nejběžnější. Klíčovým bodem je věnovat pozornost zkreslení ve spojení se známými, špatně fungujícími dotazy. Nepředpokládejte, že plán byl vygenerován na základě přesných podmínek počtu řádků. Pokud jsou tato čísla zkreslená, musíte se nejprve pokusit problém vyřešit.