Můj spolupracovník Steve Wright (blog | @SQL_Steve) mě nedávno pobídl otázkou na podivný výsledek, který viděl. Aby otestoval některé funkce v našem nejnovějším nástroji, SQL Sentry Plan Explorer PRO, vyrobil širokou a velkou tabulku a spouštěl proti ní různé dotazy. V jednom případě vracel hodně dat, ale STATISTICS IO ukazovalo, že probíhá velmi málo čtení. Pingl jsem pár lidí na #sqlhelp, a protože se zdálo, že tento problém nikdo neviděl, napadlo mě, že o tom budu psát blog.
Verze TL;DR
Stručně řečeno, uvědomte si, že existují některé scénáře, kdy se nemůžete spolehnout na STATISTICS IO říct ti pravdu. V některých případech (tento zahrnuje TOP a paralelismus), bude výrazně podhodnocovat logická čtení. To vás může vést k domněnce, že máte dotaz velmi vstřícný k I/O, když nemáte. Existují další zjevnější případy – například když máte spoustu I/O skrytých pomocí skalárních uživatelsky definovaných funkcí. Myslíme si, že Plan Explorer tyto případy objasňuje; tento je však trochu složitější.
Problémový dotaz
Tabulka má 37 milionů řádků, až 250 bajtů na řádek, asi 1 milion stránek a velmi nízkou fragmentaci (0,42 % na úrovni 0, 15 % na úrovni 1 a 0 za tím). Neexistují žádné vypočítané sloupce, žádné UDF ve hře a žádné indexy kromě seskupeného primárního klíče na úvodním INT sloupec. Jednoduchý dotaz vracející 500 000 řádků, všechny sloupce, pomocí TOP a SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(A ano, uvědomuji si, že porušuji svá vlastní pravidla a používám SELECT * a TOP bez ORDER BY , ale kvůli jednoduchosti se snažím co nejlépe minimalizovat svůj vliv na optimalizátor.)
Výsledky:
(dotčeno 500 000 řádků)Tabulka 'Historie objednávek'. Počet skenů 1, logické čtení 23, fyzické čtení 0, čtení napřed čtení 0, logické čtení lob 0, fyzické čtení 0 lob, napřed čtení 0.
Vracíme 500 000 řádků a trvá to asi 10 sekund. Okamžitě vím, že s číslem logického čtení není něco v pořádku. I když jsem ještě nevěděl o základních datech, z výsledků mřížky v Management Studio mohu říci, že to stahuje více než 23 stránek dat, ať už jsou z paměti nebo mezipaměti, a to by se mělo odrazit někde v STATISTICS IO . Při pohledu na plán…
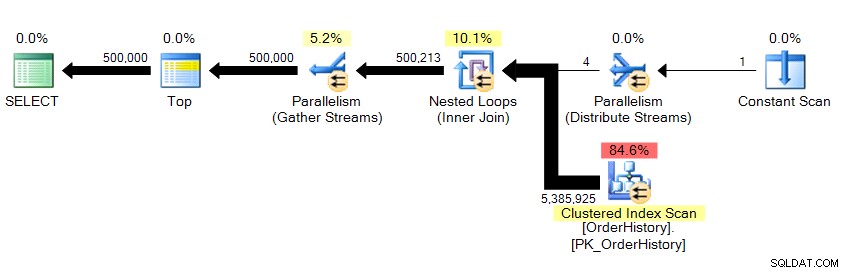
…vidíme, že je tam paralelismus a že jsme prohledali celou tabulku. Jak je tedy možné, že existuje pouze 23 logických čtení?
Další "identický" dotaz
Jedna z mých prvních otázek na Steva byla:"Co se stane, když odstraníte paralelismus?" Tak jsem to zkusil. Vzal jsem původní verzi poddotazu a přidal jsem MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Výsledky a plán:
(dotčeno 500 000 řádků)Tabulka 'Historie objednávek'. Počet skenů 1, logické čtení 149589, fyzické čtení 0, čtení napřed čtení 0, logické čtení lob 0, fyzické čtení 0 lob, čtení dopředu čtení 0.
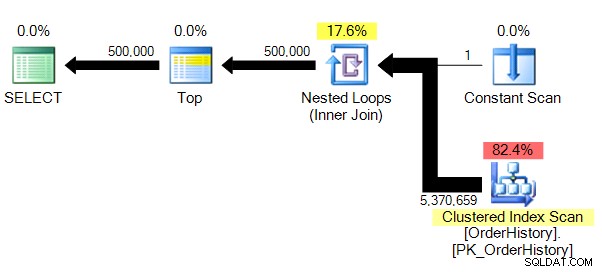
Máme o něco méně komplexní plán a bez paralelismu (z pochopitelných důvodů), STATISTICS IO nám ukazuje mnohem věrohodnější čísla pro logické počty čtení.
Co je pravda?
Není těžké vidět, že jeden z těchto dotazů neříká celou pravdu. Zatímco STATISTICS IO možná nám neřekne celý příběh, možná stopa ano. Pokud získáme metriky běhu vygenerováním skutečného plánu provádění v Průzkumníku plánů, uvidíme, že magický dotaz s nízkou četností ve skutečnosti stahuje data z paměti nebo disku, a ne z oblaku kouzelného pixie prachu. Ve skutečnosti má *více* čtení než jiná verze:

Je tedy jasné, že ke čtení dochází, jen se nezobrazují správně v STATISTICS IO výstup.
V čem je problém?
No, budu docela upřímný:nevím, kromě faktu, že paralelismus určitě hraje roli a zdá se, že jde o nějaký druh závodu. STATISTICS IO (a protože tam získáváme data, naše karta Tabulka I/O) ukazuje velmi zavádějící počet čtení. Je jasné, že dotaz vrací všechna data, která hledáme, a z výsledků trasování je jasné, že k tomu používá čtení a ne osmózu. Zeptal jsem se na to Paula Whitea (blog | @SQL_Kiwi) a on navrhl, že do celkového počtu jsou zahrnuty pouze některé počty I/O před vláknem (a souhlasí s tím, že se jedná o chybu).
Pokud si to chcete vyzkoušet doma, stačí vám AdventureWorks (toto by se mělo opakovat s verzemi 2008, 2008 R2 a 2012) a následující dotaz:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Všimněte si, že SETCPUWEIGHT se používá pouze pro koaxiální paralelismus. Další informace najdete v příspěvku na blogu Paula Whitea o Plan Costing.)
Výsledky:
Tabulka 'SalesOrderHeader'. Počet skenů 1, logické čtení 4, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.Tabulka 'SalesOrderHeader'. Počet skenů 1, logické čtení 333, fyzické čtení 0, čtení napřed čtení 0, logické čtení lob 0, fyzické čtení 0 lob, napřed čtení 0.
Paul poukázal na ještě jednodušší repro:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Výsledky:
Tabulka 'TransactionHistory'. Počet skenů 1, logické čtení 5, fyzické čtení 0, čtení napřed 0, logické čtení 0 lob, fyzické čtení 0, lob čtení napřed čte 0.Tabulka 'TransactionHistory'. Počet skenů 1, logické čtení 110, fyzické čtení 0, čtení napřed čtení 0, logické čtení lob 0, fyzické čtení 0 lob, napřed čtení 0.
Zdá se tedy, že to můžeme snadno libovolně reprodukovat pomocí TOP operátor a dostatečně nízké DOP. Nahlásil jsem chybu:
- STATISTICS IO podhodnocuje logická čtení pro paralelní plány
A Paul nahlásil dvě další poněkud související chyby týkající se paralelismu, první v důsledku našeho rozhovoru:
- Chyba odhadu mohutnosti s posunutým predikátem při vyhledávání [ související blogový příspěvek ]
- Slabý výkon s paralelismem a Top [ související blogový příspěvek ]
(Pro nostalgiky je zde šest dalších chyb paralelismu, na které jsem upozornil před několika lety.)
Jaká je lekce?
Buďte opatrní a důvěřujte jedinému zdroji. Pokud se podíváte pouze na STATISTICS IO po změně dotazu, jako je tento, můžete být v pokušení zaměřit se na zázračný pokles čtení namísto prodloužení doby trvání. V tu chvíli se můžete poplácat po zádech, odejít z práce dříve a užít si víkend v domnění, že jste právě udělali obrovský dopad na výkon vašeho dotazu. Když samozřejmě nic nemůže být dále od pravdy.