Toto je druhý díl ze série o řešení problému generátoru číselných řad. Minulý měsíc jsem se zabýval řešeními, která generují řádky za běhu pomocí konstruktoru hodnot tabulky s řádky založenými na konstantách. V těchto řešeních nebyly zahrnuty žádné I/O operace. Tento měsíc se zaměřím na řešení, která se dotazují na fyzickou základní tabulku, kterou předem vyplníte řádky. Z tohoto důvodu kromě vykazování časového profilu řešení, jako jsem to udělal minulý měsíc, budu také hlásit I/O profil nových řešení. Ještě jednou děkujeme Alanu Bursteinovi, Joe Obbishovi, Adamu Machanicovi, Christopheru Fordovi, Jeffu Modenovi, Charliemu, NoamGr, Kamilu Kosnovi, Dave Masonovi, Johnu Nelsonovi #2 a Edu Wagnerovi za sdílení vašich nápadů a komentářů.
Zatím nejrychlejší řešení
Nejprve si jako rychlé připomenutí projdeme nejrychlejší řešení z článku z minulého měsíce, implementované jako inline TVF s názvem dbo.GetNumsAlanCharlieItzikBatch.
Provedu své testování v tempdb a povolím statistiky IO a TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Nejrychlejší řešení z minulého měsíce používá spojení s fiktivní tabulkou, která má index columnstore pro dávkové zpracování. Zde je kód pro vytvoření fiktivní tabulky:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A zde je kód s definicí funkce dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Minulý měsíc jsem použil následující kód k otestování výkonu funkce se 100 miliony řádků poté, co jsem povolil možnost Zahodit výsledky po spuštění v SSMS, aby se potlačilo vracení výstupních řádků:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zde jsou časové statistiky, které jsem získal pro toto provedení:
Čas CPU =16031 ms, uplynulý čas =17172 ms.Joe Obbish správně poznamenal, že tento test může postrádat odraz některých reálných scénářů v tom smyslu, že velká část doby běhu je způsobena asynchronním síťovým I/O čekáním (typ čekání ASYNC_NETWORK_IO). Nejvyšší čekání můžete pozorovat tak, že se podíváte na stránku vlastností kořenového uzlu skutečného plánu dotazů nebo spustíte rozšířenou relaci událostí s informacemi o čekání. Skutečnost, že povolíte zahodit výsledky po spuštění v SSMS, nebrání serveru SQL Server v odesílání řádků výsledků do SSMS; pouze brání SSMS v jejich tisku. Otázkou je, jaká je pravděpodobnost, že klientovi vrátíte velké sady výsledků v reálných scénářích, i když tuto funkci použijete k vytvoření velkých číselných řad? Možná častěji zapíšete výsledky dotazu do tabulky nebo použijete výsledek funkce jako součást dotazu, který nakonec vytvoří malou sadu výsledků. Musíte na to přijít. Výslednou sadu můžete zapsat do dočasné tabulky pomocí příkazu SELECT INTO, nebo můžete použít trik Alana Bursteina s příkazem SELECT přiřazení, který přiřadí hodnotu sloupce výsledku proměnné.
Zde je návod, jak byste změnili poslední test tak, aby používal možnost přiřazení proměnné:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zde jsou časové statistiky, které jsem získal pro tento test:
CPU čas =8641 ms, uplynulý čas =8645 ms.Tentokrát informace o čekání nemají žádné asynchronní síťové I/O čekání a můžete vidět výrazný pokles doby běhu.
Otestujte funkci znovu, tentokrát s přidáním objednávky:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Získal jsem následující statistiky výkonu pro toto provedení:
CPU čas =9360 ms, uplynulý čas =9551 ms.Připomeňme, že pro tento dotaz není v plánu nutný operátor řazení, protože sloupec n je založen na výrazu, který zachovává pořadí vzhledem ke sloupci rownum. To je díky Charliho neustálému skládacímu triku, kterým jsem se zabýval minulý měsíc. Plány pro oba dotazy – jeden bez objednání a jeden s objednáním jsou stejné, takže výkon bývá podobný.
Obrázek 1 shrnuje údaje o výkonu, které jsem získal pro řešení z minulého měsíce, tentokrát pouze s použitím proměnného přiřazení v testech namísto zahození výsledků po provedení.
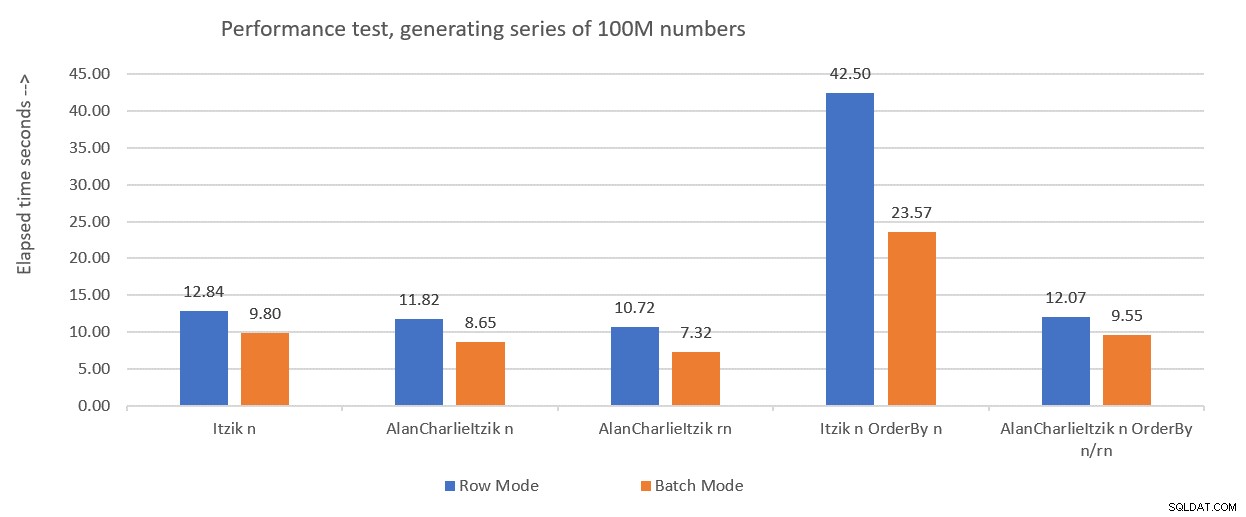 Obrázek 1:Shrnutí dosavadního výkonu s přiřazením proměnných
Obrázek 1:Shrnutí dosavadního výkonu s přiřazením proměnných
K testování zbývajících řešení, která představím v tomto článku, použiji techniku přiřazení proměnných. Ujistěte se, že upravujete své testy tak, aby co nejlépe odrážely vaši skutečnou situaci, pomocí přiřazení proměnných, SELECT INTO, Zrušení výsledků po provedení nebo jakékoli jiné techniky.
Tip pro vynucení sériových plánů bez MAXDOP 1
Než představím nová řešení, chtěl jsem pokrýt malý tip. Připomeňme, že některá řešení fungují nejlépe při použití sériového plánu. Zřejmý způsob, jak to vynutit, je pomocí nápovědy k dotazu MAXDOP 1. A to je správná cesta, pokud někdy chcete povolit paralelismus a někdy ne. Co když však chcete při použití funkce vždy vynutit sériový plán, i když je to méně pravděpodobný scénář?
Existuje trik, jak toho dosáhnout. Použití nelineovatelného skalárního UDF v dotazu je inhibitor paralelismu. Jedním ze skalárních inhibitorů inliningu UDF je vyvolání vnitřní funkce, která je závislá na čase, jako je SYSDATETIME. Zde je příklad skalárního UDF, který nelze vložit:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Další možností je definovat UDF pouze s nějakou konstantou jako vrácenou hodnotou a použít volbu INLINE =OFF v jeho záhlaví. Tato možnost je však k dispozici pouze počínaje SQL Serverem 2019, který zavedl skalární vkládání UDF. Pomocí výše navrhované funkce ji můžete vytvořit stejně jako u starších verzí SQL Server.
Dále změňte definici funkce dbo.GetNumsAlanCharlieItzikBatch tak, aby měla fiktivní volání dbo.MySYSDATETIME (definujte na jeho základě sloupec, ale neodkazujte na sloupec ve vráceném dotazu), například takto:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Nyní můžete znovu spustit test výkonu bez zadání MAXDOP 1 a přesto získat sériový plán:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Je důležité zdůraznit, že jakýkoli dotaz využívající tuto funkci nyní získá sériový plán. Pokud existuje nějaká šance, že funkce bude použita v dotazech, které budou těžit z paralelních plánů, raději tento trik nepoužívejte, a když potřebujete sériový plán, jednoduše použijte MAXDOP 1.
Řešení od Joe Obbishe
Joeovo řešení je docela kreativní. Zde je jeho vlastní popis řešení:
„Rozhodl jsem se pro vytvoření seskupeného indexu columnstore (CCI) se 134 217 728 řádky sekvenčních celých čísel. Funkce odkazuje na tabulku až 32krát, aby získala všechny řádky potřebné pro sadu výsledků. Vybral jsem si CCI, protože data se budou dobře komprimovat (méně než 3 bajty na řádek), dostanete dávkový režim „zdarma“ a předchozí zkušenosti naznačují, že čtení sekvenčních čísel z CCI bude rychlejší než jejich generování nějakou jinou metodou. “Jak již bylo zmíněno dříve, Joe také poznamenal, že moje původní testování výkonu bylo výrazně zkreslené kvůli asynchronním síťovým I/O čekáním generovaným přenosem řádků do SSMS. Takže všechny testy, které zde provedu, budou používat Alanův nápad s přiřazením proměnné. Nezapomeňte upravit své testy podle toho, co nejvíce odpovídá vaší skutečné životní situaci.
Zde je kód, který Joe použil k vytvoření tabulky dbo.GetNumsObbishTable a naplnil ji 134 217 728 řádky:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Dokončení tohoto kódu na mém počítači trvalo 1:04 minuty.
Využití místa v této tabulce můžete zkontrolovat spuštěním následujícího kódu:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Využil jsem asi 350 MB místa. V porovnání s ostatními řešeními, která představím v tomto článku, toto zabírá podstatně více místa.
V architektuře columnstore SQL Serveru je skupina řádků omezena na 2^20 =1 048 576 řádků. Pomocí následujícího kódu můžete zkontrolovat, kolik skupin řádků bylo pro tuto tabulku vytvořeno:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Mám 128 skupin řádků.
Zde je kód s definicí funkce dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
32 jednotlivých dotazů generuje nesouvislé podrozsahy 134 217 728 celých čísel, které po sjednocení vytvoří úplný nepřerušovaný rozsah 1 až 4 294 967 296. To, co je na tomto řešení opravdu chytré, jsou predikáty filtru WHERE, které jednotlivé dotazy používají. Připomeňme, že když SQL Server zpracovává inline TVF, nejprve použije vkládání parametrů a nahradí parametry vstupními konstantami. SQL Server pak může optimalizovat dotazy, které vytvářejí podrozsahy, které se neprotínají se vstupním rozsahem. Když například požadujete vstupní rozsah 1 až 100 000 000, bude relevantní pouze první dotaz a všechny ostatní budou optimalizovány. Plán pak v tomto případě bude zahrnovat odkaz pouze na jednu instanci tabulky. To je skvělé!
Pojďme otestovat výkon funkce v rozsahu 1 až 100 000 000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Plán pro tento dotaz je znázorněn na obrázku 2.
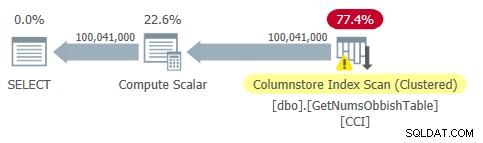 Obrázek 2:Plán pro dbo.GetNumsObbish, 100 milionů řádků, neuspořádané
Obrázek 2:Plán pro dbo.GetNumsObbish, 100 milionů řádků, neuspořádané
Všimněte si, že v tomto plánu je skutečně potřeba pouze jeden odkaz na CCI tabulky.
Pro toto provedení jsem získal následující časové statistiky:
To je docela působivé a mnohem rychlejší než cokoliv jiného, co jsem testoval.
Zde jsou I/O statistiky, které jsem získal pro toto provedení:
Tabulka 'GetNumsObbishTable'. Počet skenování 1, logická čtení 0, fyzická čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, lob logická čtení 32928 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.Tabulka 'GetNumsObbishTable'. Segment má hodnotu 96 , segment přeskočen 32.
Vstupně-výstupní profil tohoto řešení je jednou z jeho nevýhod ve srovnání s ostatními, protože toto provedení vyžaduje více než 30 kB logických čtení.
Chcete-li vidět, že když překročíte více podrozsahů 134 217 728 celých čísel, plán bude zahrnovat více odkazů na tabulku, zadejte dotaz na funkci s rozsahem 1 až 400 000 000, například:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Plán tohoto provedení je znázorněn na obrázku 3.
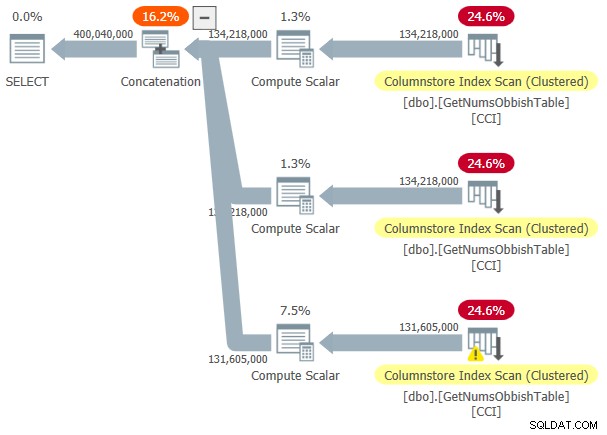 Obrázek 3:Plán pro dbo.GetNumsObbish, 400 milionů řádků, neuspořádané
Obrázek 3:Plán pro dbo.GetNumsObbish, 400 milionů řádků, neuspořádané
Požadovaný rozsah překročil tři podrozsahy 134 217 728 celých čísel, takže plán ukazuje tři odkazy na CCI tabulky.
Zde jsou časové statistiky, které jsem získal pro toto provedení:
Čas CPU =20610 ms, uplynulý čas =20628 ms.A zde jsou jeho I/O statistiky:
Tabulka 'GetNumsObbishTable'. Počet skenování 3, logická čtení 0, fyzická čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server napřed čtení 0, lob logické čtení 131026 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.Tabulka 'GetNumsObbishTable'. Čtení segmentu 382 , segment přeskočen 2.
Tentokrát provedení dotazu vedlo k více než 130 kB logických čtení.
Pokud snesete náklady na I/O a nepotřebujete zpracovávat číselné řady uspořádaným způsobem, je to skvělé řešení. Pokud však potřebujete zpracovat sérii v pořadí, toto řešení bude mít za následek operátor řazení v plánu. Zde je test vyžadující objednaný výsledek:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Plán tohoto provedení je znázorněn na obrázku 4.
 Obrázek 4:Plán pro dbo.GetNumsObbish, 100 milionů řádků, objednané
Obrázek 4:Plán pro dbo.GetNumsObbish, 100 milionů řádků, objednané
Zde jsou časové statistiky, které jsem získal pro toto provedení:
Čas CPU =44516 ms, uplynulý čas =34836 ms.Jak můžete vidět, výkon se výrazně snížil s dobou běhu, která se o řád prodloužila v důsledku explicitního řazení.
Zde jsou statistiky I/O, které jsem získal pro toto provedení:
Tabulka 'GetNumsObbishTable'. Počet skenování 4, logická čtení 0, fyzická čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server čtení dopředu čte 0, lob logická čtení 32928 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.Tabulka 'GetNumsObbishTable'. Segment má hodnotu 96 , segment přeskočen 32.
Tabulka 'Pracovní stůl'. Počet skenování 0, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkovací server napřed čtení 0, logické čtení 0, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, server Lob napřed čte 0.
Všimněte si, že se ve výstupu STATISTICS IO objevila pracovní tabulka. Je to proto, že řazení se může potenciálně přenést do databáze tempdb, v takovém případě by použil pracovní stůl. Toto provedení se nerozsypalo, proto jsou v tomto záznamu všechna čísla nula.
Řešení od John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 zveřejnil řešení, které je prostě krásné ve své jednoduchosti. Navíc obsahuje nápady a návrhy z jiných řešení od Davea, Joea, Alana, Charlieho a mě.
Stejně jako u řešení Joe se John rozhodl použít CCI, aby získal vysokou úroveň komprese a „bezplatné“ dávkové zpracování. Pouze John se rozhodl vyplnit tabulku 4B řádky s nějakým falešným NULL markerem v bitovém sloupci a nechat vygenerovat čísla funkcí ROW_NUMBER. Protože uložené hodnoty jsou všechny stejné, s kompresí opakujících se hodnot potřebujete výrazně méně místa, což má za následek výrazně méně I/O ve srovnání s řešením Joe. Komprese Columnstore zvládá opakující se hodnoty velmi dobře, protože může reprezentovat každou takovou po sobě jdoucí sekci v segmentu sloupce skupiny řádků pouze jednou spolu s počtem po sobě jdoucích opakujících se výskytů. Protože všechny řádky mají stejnou hodnotu (značka NULL), teoreticky potřebujete pouze jeden výskyt na skupinu řádků. Se 4B řádky byste měli skončit se 4 096 skupinami řádků. Každý by měl mít jeden segment sloupců s velmi malými požadavky na prostor.
Zde je kód pro vytvoření a naplnění tabulky implementované jako CCI s archivní kompresí:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Hlavní nevýhodou tohoto řešení je čas potřebný k naplnění této tabulky. Dokončení tohoto kódu na mém počítači trvalo 12:32 minut, když jsem povolil paralelismus, a 15:17 minut, když jsem si vynutil sériový plán.
Všimněte si, že můžete pracovat na optimalizaci zatížení dat. Například John testoval řešení, které načítalo řádky pomocí 32 současných připojení s OSTRESS.EXE, z nichž každé provedlo 128 kol vložení 2^20 řádků (maximální velikost skupiny řádků). Toto řešení snížilo Johnovu dobu načítání na třetinu. Zde je kód, který John použil:
ostres -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"WITH L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (VYBERTE A.b Z L0 JAKO KŘÍŽOVÉ PŘIPOJENÍ L0 JAKO B), L2 AS (VYBERTE A.b Z L1 JAKO KŘÍŽOVÉ SPOJE L1 AS B), nulls(b) AS (VYBERTE A.b Z L2 JAKO A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Přesto je doba načítání v minutách. Dobrou zprávou je, že toto načtení dat musíte provést pouze jednou.
Skvělou zprávou je malý prostor, který stůl potřebuje. Ke kontrole využití místa použijte následující kód:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Mám 1,64 MB. To je úžasné vzhledem k tomu, že tabulka má 4B řádků!
Pomocí následujícího kódu zkontrolujte, kolik skupin řádků bylo vytvořeno:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Podle očekávání je počet skupin řádků 4 096.
Definice funkce dbo.GetNumsJohn2DaveObbishAlanCharlieItzik se pak stává docela jednoduchou:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Jak vidíte, jednoduchý dotaz na tabulku používá funkci ROW_NUMBER k výpočtu základních čísel řádků (sloupec rownum) a pak vnější dotaz používá stejné výrazy jako v dbo.GetNumsAlanCharlieItzikBatch k výpočtu rn, op a n. Také zde platí, že rn i n jsou zachováním pořadí s ohledem na rownum.
Pojďme otestovat výkon funkce:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Mám plán znázorněný na obrázku 5 pro toto provedení.
 Obrázek 5:Plán pro dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Obrázek 5:Plán pro dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Zde jsou časové statistiky, které jsem získal pro tento test:
Čas CPU =7593 ms, uplynulý čas =7590 ms.
Jak můžete vidět, doba provádění není tak rychlá jako u Joeova řešení, ale je stále rychlejší než všechna ostatní řešení, která jsem testoval.
Zde jsou I/O statistiky, které jsem získal pro tento test:
Tabulka 'NullBits4B'. Segment má hodnotu 96 , segment přeskočen 0
Všimněte si, že I/O požadavky jsou výrazně nižší než u řešení Joe.
Další skvělá věc na tomto řešení je, že když potřebujete zpracovat objednanou číselnou řadu, neplatíte nic navíc. To proto, že to nepovede k explicitní operaci řazení v plánu, bez ohledu na to, zda výsledek objednáte podle rn nebo n.
Zde je test, který to demonstruje:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Získáte stejný plán, jaký je znázorněn na obrázku 5.
Zde jsou časové statistiky, které jsem získal pro tento test;
Čas CPU =7578 ms, uplynulý čas =7582 ms.A zde jsou I/O statistiky:
Tabulka 'NullBits4B'. Počet skenování 1, logické čtení 0, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkový server čtení napřed čte 0, lob logické čtení 194 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.Tabulka 'NullBits4B'. Segment má hodnotu 96 , segment přeskočen 0.
Jsou v podstatě stejné jako v testu bez řazení.
Řešení 2 od John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
Johnovo řešení je rychlé a jednoduché. To je fantastické. Jedinou nevýhodou je doba načítání. Někdy to nebude problém, protože načítání proběhne pouze jednou. Pokud se však jedná o problém, můžete tabulku naplnit 102 400 řádky místo 4B řádků a použít křížové spojení mezi dvěma instancemi tabulky a TOP filtr k vygenerování požadovaného maxima 4B řádků. Všimněte si, že pro získání 4B řádků by stačilo naplnit tabulku 65 536 řádky a poté použít křížové spojení; nicméně, aby byla data okamžitě komprimována – na rozdíl od načítání do delta úložiště založeného na rowstore – musíte načíst tabulku s minimálně 102 400 řádky.
Zde je kód pro vytvoření a naplnění tabulky:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Doba načítání je zanedbatelná – 43 ms na mém počítači.
Zkontrolujte velikost tabulky na disku:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Mám 56 KB místa potřebného pro data.
Zkontrolujte počet skupin řádků, jejich stav (komprimovaný nebo otevřený) a jejich velikost:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Mám následující výstup:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Zde je potřeba pouze jedna skupina řádků; je komprimovaný a jeho velikost je zanedbatelných 293 bajtů.
Pokud naplníte tabulku o jeden řádek méně (102 399), získáte nekomprimované otevřené delta úložiště založené na úložišti řádků. V takovém případě sp_spaceused hlásí velikost dat na disku přes 1 MB a sys.column_store_row_groups hlásí následující informace:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Ujistěte se tedy, že tabulku naplníte 102 400 řádky!
Zde je definice funkce dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
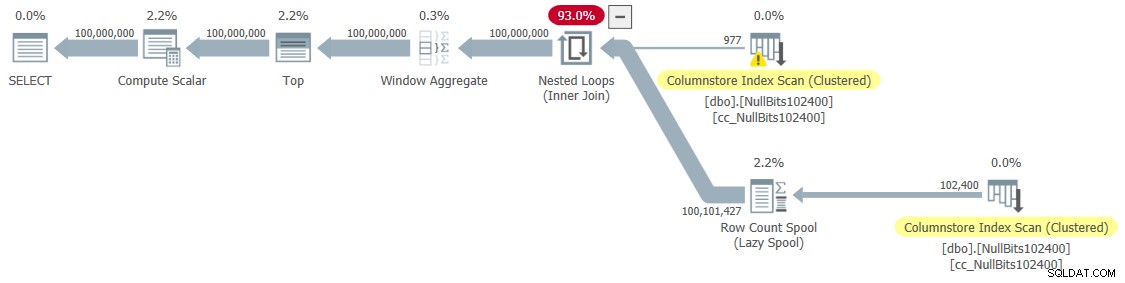 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
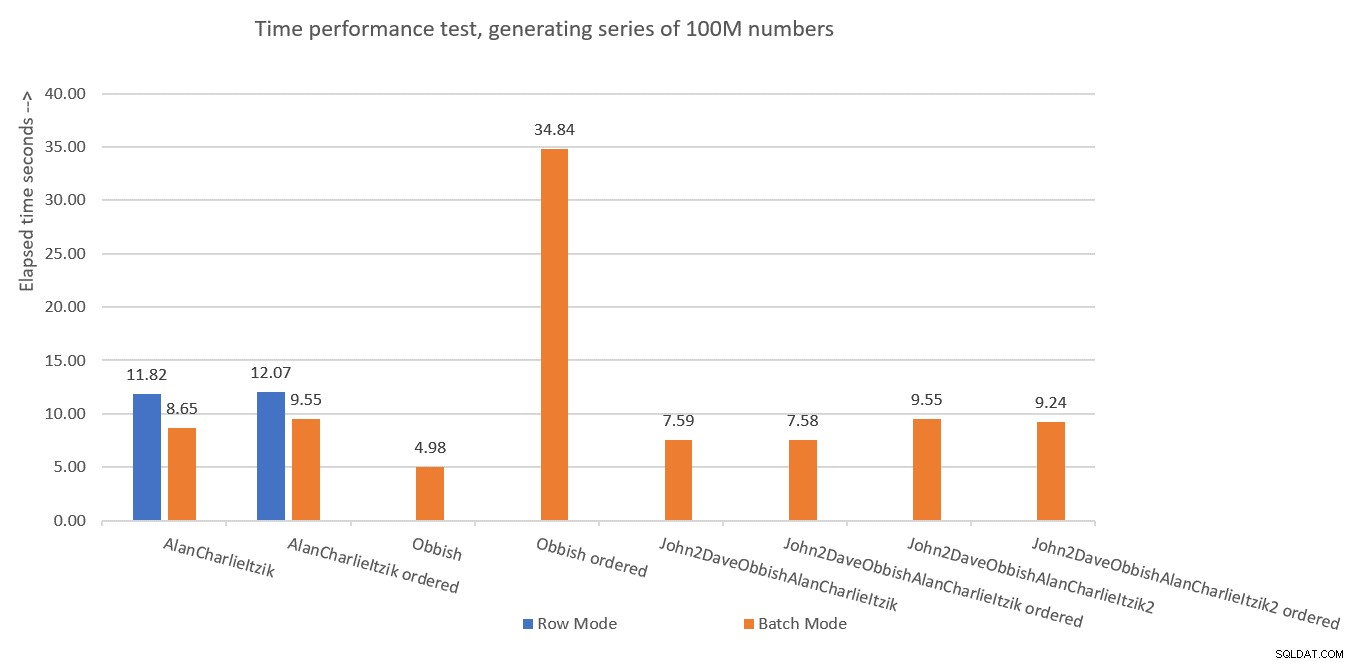 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
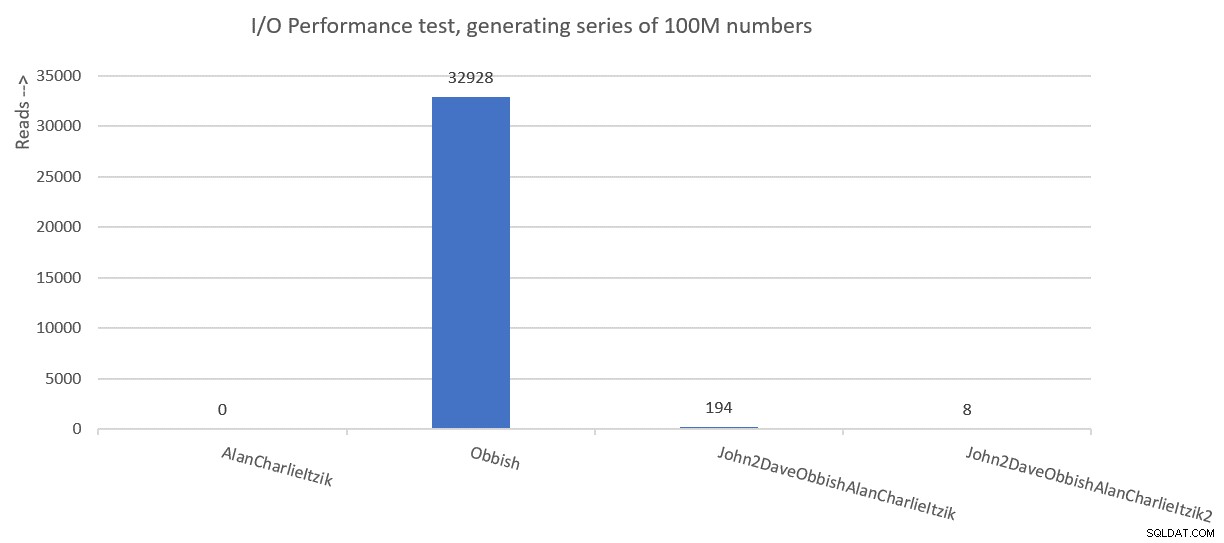 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.