Často, když píšeme uloženou proceduru, chceme, aby se chovala různými způsoby na základě vstupu uživatele. Podívejme se na následující příklad:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Tato uložená procedura, kterou jsem vytvořil v databázi AdventureWorks2017, má dva parametry:@CustomerID a @SortOrder. První parametr, @CustomerID, ovlivňuje řádky, které mají být vráceny. Pokud je do uložené procedury předáno konkrétní ID zákazníka, vrátí všechny objednávky (10 nejlepších) pro tohoto zákazníka. V opačném případě, pokud je NULL, uložená procedura vrátí všechny objednávky (prvních 10) bez ohledu na zákazníka. Druhý parametr, @SortOrder, určuje, jak budou data řazena – podle OrderDate nebo SalesOrderID. Všimněte si, že bude vráceno pouze prvních 10 řádků podle pořadí řazení.
Uživatelé tedy mohou chování dotazu ovlivnit dvěma způsoby – které řádky vrátit a jak je seřadit. Přesněji řečeno, pro tento dotaz existují 4 různá chování:
- Vraťte prvních 10 řádků pro všechny zákazníky seřazených podle Datum objednávky (výchozí chování)
- Vraťte prvních 10 řádků pro konkrétního zákazníka seřazených podle Datum objednávky
- Vraťte prvních 10 řádků pro všechny zákazníky seřazené podle SalesOrderID
- Vraťte prvních 10 řádků pro konkrétního zákazníka seřazených podle SalesOrderID
Pojďme otestovat uloženou proceduru se všemi 4 možnostmi a prozkoumáme plán provádění a statistiku IO.
Vraťte 10 nejlepších řádků pro všechny zákazníky seřazených podle data objednávky
Následuje kód pro provedení uložené procedury:
EXECUTE Sales.GetOrders; GO
Zde je plán provedení:
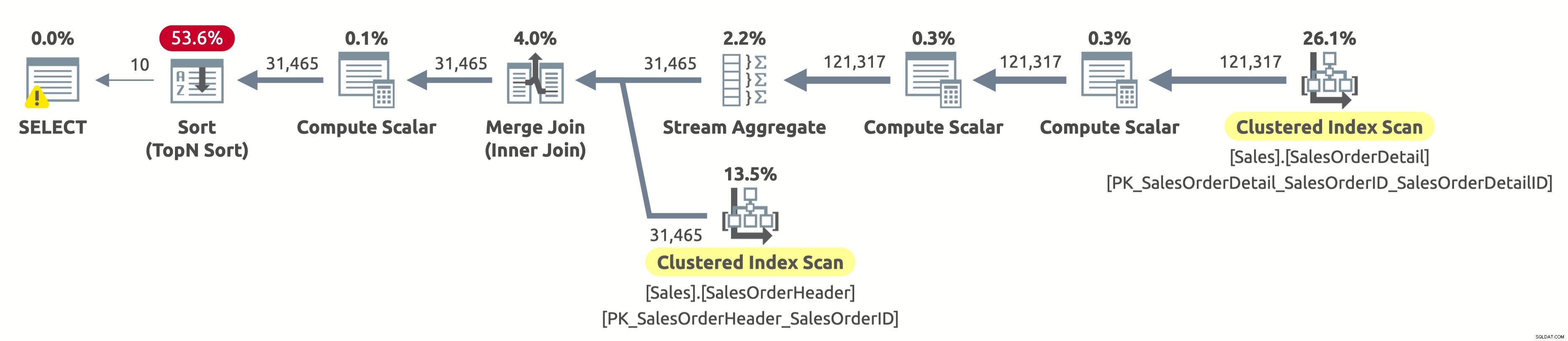
Protože jsme nefiltrovali podle zákazníka, musíme naskenovat celou tabulku. Optimalizátor se rozhodl skenovat obě tabulky pomocí indexů na SalesOrderID, což umožnilo efektivní agregaci streamů a také efektivní spojení sloučení.
Pokud zkontrolujete vlastnosti operátoru Clustered Index Scan v tabulce Sales.SalesOrderHeader, najdete následující predikát:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] jako [SalesOrders].[CustomerID]=[ @CustomerID] NEBO [@CustomerID] JE NULL. Procesor dotazů musí vyhodnotit tento predikát pro každý řádek v tabulce, což není příliš efektivní, protože se vždy vyhodnotí jako true.
Stále potřebujeme seřadit všechna data podle OrderDate, abychom vrátili prvních 10 řádků. Pokud by byl index na OrderDate, pak by ho optimalizátor pravděpodobně použil ke skenování pouze prvních 10 řádků z Sales.SalesOrderHeader, ale žádný takový index neexistuje, takže plán vypadá v pořádku s ohledem na dostupné indexy.
Zde je výstup statistik IO:
- Tabulka 'SalesOrderHeader'. Počet skenů 1, logická přečtení 689
- Tabulka 'SalesOrderDetail'. Počet skenů 1, logických čtení 1248
Pokud se ptáte, proč je na operátoru SELECT varování, pak je to nadměrné varování o udělení. V tomto případě to není proto, že by byl problém v prováděcím plánu, ale spíše proto, že procesor dotazu požadoval 1 024 KB (což je ve výchozím nastavení minimum) a použil pouze 16 KB.
Někdy není ukládání plánu do mezipaměti tak dobrý nápad
Dále chceme otestovat scénář vrácení prvních 10 řádků pro konkrétního zákazníka seřazených podle Datum objednávky. Níže je kód:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Prováděcí plán je úplně stejný jako dříve. Tentokrát je plán velmi neefektivní, protože proskenuje obě tabulky pouze pro vrácení 3 objednávek. Existují mnohem lepší způsoby, jak tento dotaz provést.
Důvodem je v tomto případě ukládání plánu do mezipaměti. Prováděcí plán byl vygenerován při prvním spuštění na základě hodnot parametrů v tomto konkrétním provedení – metoda známá jako parametrické čichání. Tento plán byl uložen v mezipaměti plánu pro opětovné použití a od této chvíle bude každé volání této uložené procedury znovu používat stejný plán.
Toto je příklad, kdy ukládání plánu do mezipaměti není tak dobrý nápad. Vzhledem k povaze této uložené procedury, která má 4 různá chování, očekáváme, že pro každé chování získáme jiný plán. Ale zůstali jsme u jediného plánu, který je dobrý pouze pro jednu ze 4 možností, na základě možnosti použité v prvním provedení.
Zakažme ukládání plánu do mezipaměti pro tuto uloženou proceduru, abychom viděli nejlepší plán, který může optimalizátor vymyslet pro každé z dalších 3 chování. To provedeme přidáním WITH RECOMPILE do příkazu EXECUTE.
Vraťte prvních 10 řádků pro konkrétního zákazníka seřazených podle data objednávky
Následuje kód pro vrácení prvních 10 řádků pro konkrétního zákazníka seřazených podle OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Níže je uveden plán provádění:
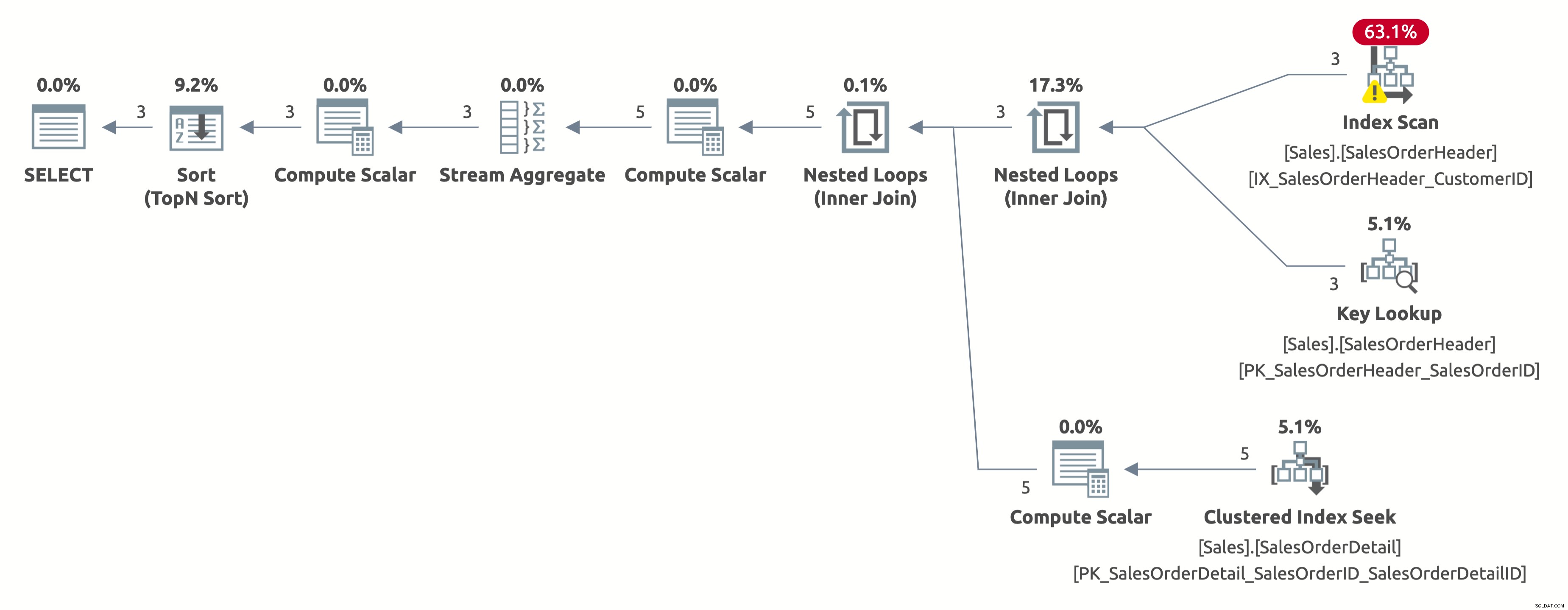
Tentokrát dostáváme lepší plán, který používá index na CustomerID. Optimalizátor správně odhadne 2,6 řádků pro CustomerID =11006 (skutečný počet je 3). Všimněte si však, že místo hledání indexu provádí prohledávání indexu. Nemůže provést hledání indexu, protože musí vyhodnotit následující predikát pro každý řádek v tabulce:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] jako [SalesOrders].[CustomerID]=[@CustomerID ] NEBO [@CustomerID] JE NULL.
Zde je výstup statistik IO:
- Tabulka 'SalesOrderDetail'. Počet skenů 3, logické čtení 9
- Tabulka 'SalesOrderHeader'. Počet skenů 1, logické čtení 66
Vraťte prvních 10 řádků pro všechny zákazníky seřazených podle SalesOrderID
Následuje kód pro vrácení prvních 10 řádků pro všechny zákazníky seřazené podle SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Níže je uveden plán provádění:
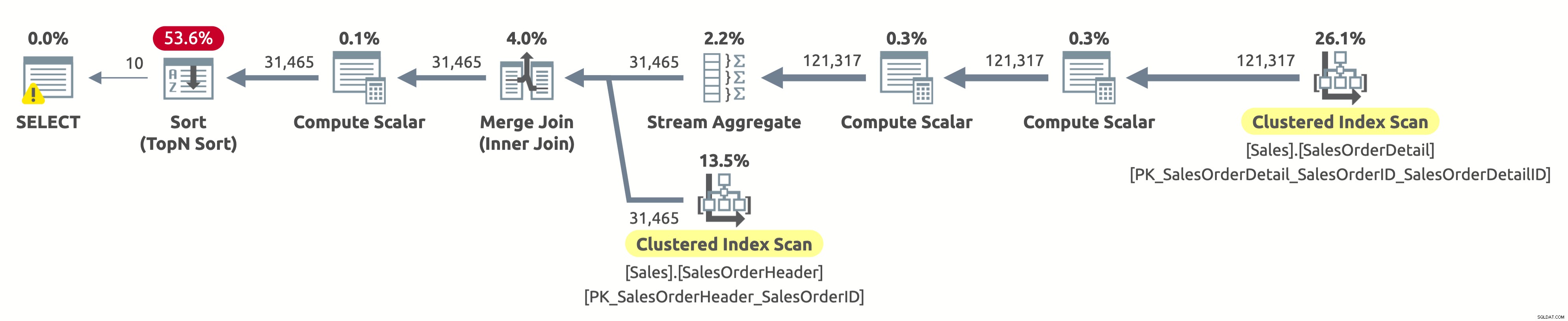
Hej, toto je stejný plán provedení jako v první možnosti. Ale tentokrát je něco špatně. Již víme, že seskupené indexy v obou tabulkách jsou seřazeny podle SalesOrderID. Víme také, že plán prohledá oba v logickém pořadí, aby zachoval pořadí řazení (vlastnost Ordered je nastavena na True). Operátor Merge Join také zachová pořadí řazení. Protože nyní žádáme o seřazení výsledku podle SalesOrderID a už je takto seřazen, proč tedy musíme platit za drahého operátora řazení?
Pokud zaškrtnete operátor Sort, všimnete si, že třídí data podle Expr1004. A pokud zaškrtnete operátor Compute Scalar napravo od operátoru Sort, zjistíte, že Expr1004 je následující:

Není to hezký pohled, já vím. Toto je výraz, který máme v klauzuli ORDER BY našeho dotazu. Problém je v tom, že optimalizátor nemůže tento výraz vyhodnotit v době kompilace, takže jej musí vypočítat pro každý řádek za běhu a na základě toho seřadit celou sadu záznamů.
Výstup statistiky IO je stejný jako v prvním provedení:
- Tabulka 'SalesOrderHeader'. Počet skenů 1, logická přečtení 689
- Tabulka 'SalesOrderDetail'. Počet skenů 1, logických čtení 1248
Vraťte prvních 10 řádků pro konkrétního zákazníka seřazených podle SalesOrderID
Následuje kód pro vrácení prvních 10 řádků pro konkrétního zákazníka seřazených podle SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Plán realizace je stejný jako u druhé možnosti (vrácení prvních 10 řádků pro konkrétního zákazníka seřazených podle Datum objednávky). Plán má stejné dva problémy, které jsme již zmínili. První problém spočívá v provádění skenování indexu namísto hledání indexu kvůli výrazu v klauzuli WHERE. Druhým problémem je provádění drahého řazení kvůli výrazu v klauzuli ORDER BY.
Co bychom tedy měli dělat?
Připomeňme si nejprve, s čím máme co do činění. Máme parametry, které určují strukturu dotazu. Pro každou kombinaci hodnot parametrů získáme jinou strukturu dotazu. V případě parametru @CustomerID jsou dvě různá chování NULL nebo NOT NULL a ovlivňují klauzuli WHERE. V případě parametru @SortOrder existují dvě možné hodnoty a ovlivňují klauzuli ORDER BY. Výsledkem jsou 4 možné struktury dotazů a pro každou bychom rádi získali jiný plán.
Pak máme dva odlišné problémy. Prvním je ukládání do mezipaměti plánu. Existuje pouze jeden plán pro uloženou proceduru a bude generován na základě hodnot parametrů při prvním spuštění. Druhým problémem je, že i když je vygenerován nový plán, není efektivní, protože optimalizátor nemůže vyhodnotit "dynamické" výrazy v klauzuli WHERE a v klauzuli ORDER BY během kompilace.
Tyto problémy se můžeme pokusit vyřešit několika způsoby:
- Použijte řadu příkazů IF-ELSE
- Rozdělte proceduru na samostatné uložené procedury
- Použijte OPTION (RECOMPILE)
- Generujte dotaz dynamicky
Použijte řadu příkazů IF-ELSE
Myšlenka je jednoduchá:namísto „dynamických“ výrazů v klauzuli WHERE a v klauzuli ORDER BY můžeme rozdělit provádění do 4 větví pomocí příkazů IF-ELSE – jedna větev pro každé možné chování.
Například následující je kód pro první větev:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Tento přístup může pomoci vytvářet lepší plány, má však určitá omezení.
Za prvé, uložená procedura se stává poměrně dlouhou a je obtížnější ji zapisovat, číst a udržovat. A to je, když máme pouze dva parametry. Pokud bychom měli 3 parametry, měli bychom 8 větví. Představte si, že potřebujete přidat sloupec do klauzule SELECT. Sloupec byste museli přidat do 8 různých dotazů. Stává se z toho noční můra údržby s vysokým rizikem lidské chyby.
Za druhé, stále máme problém s ukládáním plánu do mezipaměti a sniffováním parametrů do určité míry. Důvodem je, že při prvním spuštění optimalizátor vygeneruje plán pro všechny 4 dotazy na základě hodnot parametrů v tomto spuštění. Řekněme, že první spuštění použije výchozí hodnoty parametrů. Konkrétně hodnota @CustomerID bude NULL. Všechny dotazy budou optimalizovány na základě této hodnoty, včetně dotazu s klauzulí WHERE (SalesOrders.CustomerID =@CustomerID). Optimalizátor odhadne 0 řádků pro tyto dotazy. Nyní řekněme, že druhé provedení bude používat nenulovou hodnotu pro @CustomerID. Bude použit plán uložený v mezipaměti, který odhaduje 0 řádků, i když zákazník může mít v tabulce mnoho objednávek.
Rozdělit proceduru na samostatné uložené procedury
Místo 4 větví v rámci stejné uložené procedury můžeme vytvořit 4 samostatné uložené procedury, každou s příslušnými parametry a odpovídajícím dotazem. Potom můžeme buď přepsat aplikaci, abychom se rozhodli, kterou uloženou proceduru provést podle požadovaného chování. Nebo, pokud chceme, aby to bylo pro aplikaci transparentní, můžeme přepsat původní uloženou proceduru a rozhodnout se, kterou proceduru provést na základě hodnot parametrů. Budeme používat stejné příkazy IF-ELSE, ale místo provádění dotazu v každé větvi provedeme samostatnou uloženou proceduru.
Výhodou je, že řešíme problém ukládání plánu do mezipaměti, protože každá uložená procedura má nyní svůj vlastní plán a plán pro každou uloženou proceduru se vygeneruje při prvním spuštění na základě sniffování parametrů.
Ale stále máme problém s údržbou. Někdo by mohl říct, že teď je to ještě horší, protože potřebujeme udržovat více uložených procedur. Opět, pokud zvýšíme počet parametrů na 3, skončíme s 8 odlišnými uloženými procedurami.
Použijte OPTION (REKOMPILOVAT)
OPTION (REKOMPILOVAT) funguje jako kouzlo. Stačí slova vyslovit (nebo je připojit k dotazu) a kouzlo se stane. Opravdu řeší tolik problémů, protože zkompiluje dotaz za běhu a dělá to při každém spuštění.
Ale musíte být opatrní, protože víte, co se říká:"S velkou mocí přichází velká zodpovědnost." Pokud použijete OPTION (RECOMPILE) v dotazu, který se na zaneprázdněném systému OLTP spouští velmi často, můžete systém zabít, protože server potřebuje zkompilovat a vygenerovat nový plán při každém provádění s využitím velkého množství prostředků CPU. To je opravdu nebezpečné. Pokud se ale dotaz provádí jen jednou za čas, řekněme jednou za pár minut, pak je to pravděpodobně bezpečné. Vždy však vyzkoušejte dopad ve vašem konkrétním prostředí.
V našem případě, za předpokladu, že můžeme bezpečně použít OPTION (RECOMPILE), vše, co musíme udělat, je přidat kouzelná slova na konec našeho dotazu, jak je znázorněno níže:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Nyní se podívejme na kouzlo v akci. Například následující je plán pro druhé chování:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
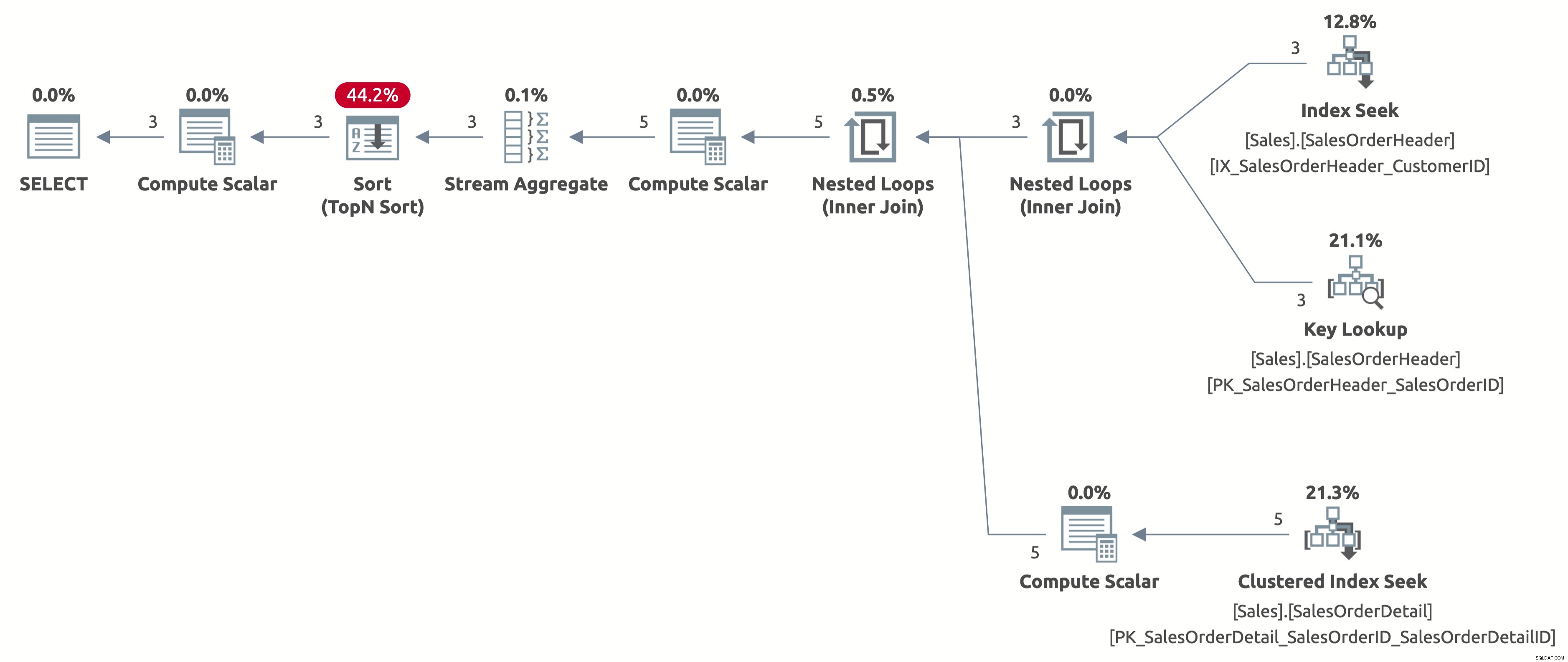
Nyní získáme efektivní hledání indexu se správným odhadem 2,6 řádků. Stále potřebujeme řadit podle OrderDate, ale nyní je řazení přímo podle Order Date a už nemusíme počítat výraz CASE v klauzuli ORDER BY. Toto je nejlepší možný plán pro toto chování dotazu na základě dostupných indexů.
Zde je výstup statistik IO:
- Tabulka 'SalesOrderDetail'. Počet skenů 3, logické čtení 9
- Tabulka 'SalesOrderHeader'. Počet skenů 1, logické čtení 11
Důvod, proč je OPTION (RECOMPILE) v tomto případě tak efektivní, je ten, že řeší přesně ty dva problémy, které zde máme. Pamatujte, že prvním problémem je ukládání do mezipaměti plánu. OPTION (RECOMPILE) tento problém zcela eliminuje, protože pokaždé znovu zkompiluje dotaz. Druhým problémem je neschopnost optimalizátoru vyhodnotit komplexní výraz v klauzuli WHERE a v klauzuli ORDER BY při kompilaci. Protože OPTION (RECOMPILE) probíhá za běhu, řeší to problém. Protože za běhu má optimalizátor mnohem více informací v porovnání s dobou kompilace a to je zásadní rozdíl.
Nyní se podívejme, co se stane, když zkusíme třetí chování:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
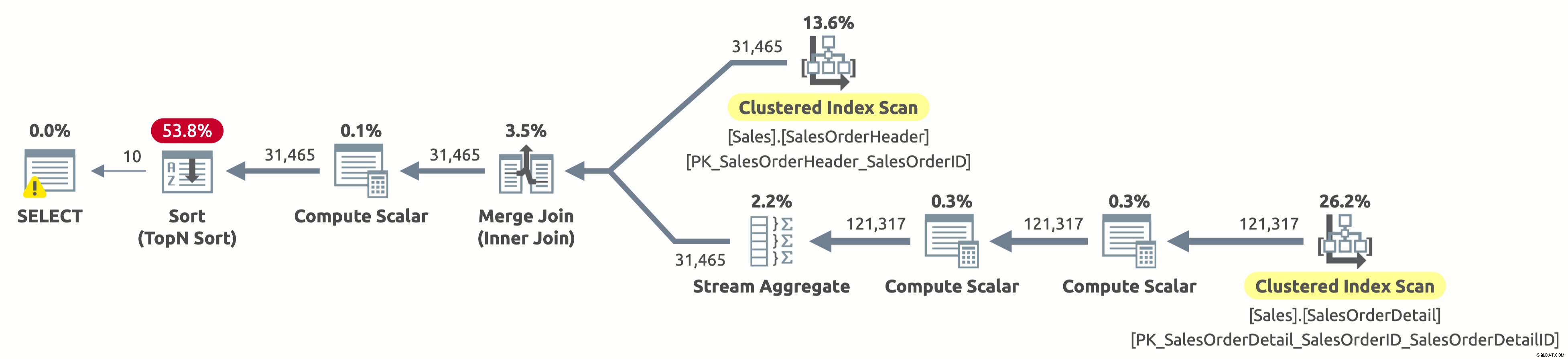
Houstone máme problém. Plán stále proskenuje obě tabulky úplně a pak vše seřadí, místo aby skenoval pouze prvních 10 řádků z Sales.SalesOrderHeader a řazení se úplně vyhnul. Co se stalo?
Toto je zajímavý "případ" a souvisí s výrazem CASE v klauzuli ORDER BY. Výraz CASE vyhodnotí seznam podmínek a vrátí jeden z výsledných výrazů. Ale výsledné výrazy mohou mít různé datové typy. Jaký by tedy byl datový typ celého výrazu CASE? Výraz CASE vždy vrací datový typ s nejvyšší prioritou. V našem případě má sloupec Datum objednávky datový typ DATETIME, zatímco sloupec SalesOrderID má datový typ INT. Datový typ DATETIME má vyšší prioritu, takže výraz CASE vždy vrátí DATETIME.
To znamená, že pokud chceme třídit podle SalesOrderID, musí výraz CASE nejprve implicitně převést hodnotu SalesOrderID na DATETIME pro každý řádek, než jej seřadí. Viz operátor Compute Scalar napravo od operátoru Sort ve výše uvedeném plánu? Přesně to dělá.
To je problém sám o sobě a ukazuje, jak nebezpečné může být míchání různých datových typů v jediném výrazu CASE.
Tento problém můžeme obejít přepsáním klauzule ORDER BY jinými způsoby, ale kód by byl ještě ošklivější a obtížnější na čtení a údržbu. Takže tímto směrem nepůjdu.
Místo toho zkusme další metodu…
Generujte dotaz dynamicky
Protože naším cílem je vygenerovat 4 různé struktury dotazů v rámci jednoho dotazu, může být v tomto případě dynamické SQL velmi užitečné. Cílem je sestavit dotaz dynamicky na základě hodnot parametrů. Tímto způsobem můžeme sestavit 4 různé struktury dotazů v jediném kódu, aniž bychom museli udržovat 4 kopie dotazu. Každá struktura dotazu se zkompiluje jednou, když je poprvé spuštěna, a získá nejlepší plán, protože neobsahuje žádné složité výrazy.
Toto řešení je velmi podobné řešení s více uloženými procedurami, ale místo udržování 8 uložených procedur pro 3 parametry udržujeme pouze jeden kód, který dynamicky vytváří dotaz.
Vím, že dynamické SQL je také ošklivé a někdy může být docela obtížné ho udržovat, ale myslím si, že je to stále jednodušší než udržovat více uložených procedur a neškáluje se exponenciálně, jak se zvyšuje počet parametrů.
Následující kód je:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Všimněte si, že stále používám interní parametr pro ID zákazníka a spouštím dynamický kód pomocí sys.sp_executesql pro předání hodnoty parametru. To je důležité ze dvou důvodů. Za prvé, abyste se vyhnuli více kompilacím stejné struktury dotazu pro různé hodnoty @CustomerID. Za druhé, abychom se vyhnuli SQL injection.
Pokud se nyní pokusíte provést uloženou proceduru pomocí různých hodnot parametrů, uvidíte, že každé chování dotazu nebo struktura dotazu má nejlepší plán provádění a každý ze 4 plánů se zkompiluje pouze jednou.
Jako příklad je uveden plán pro třetí chování:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
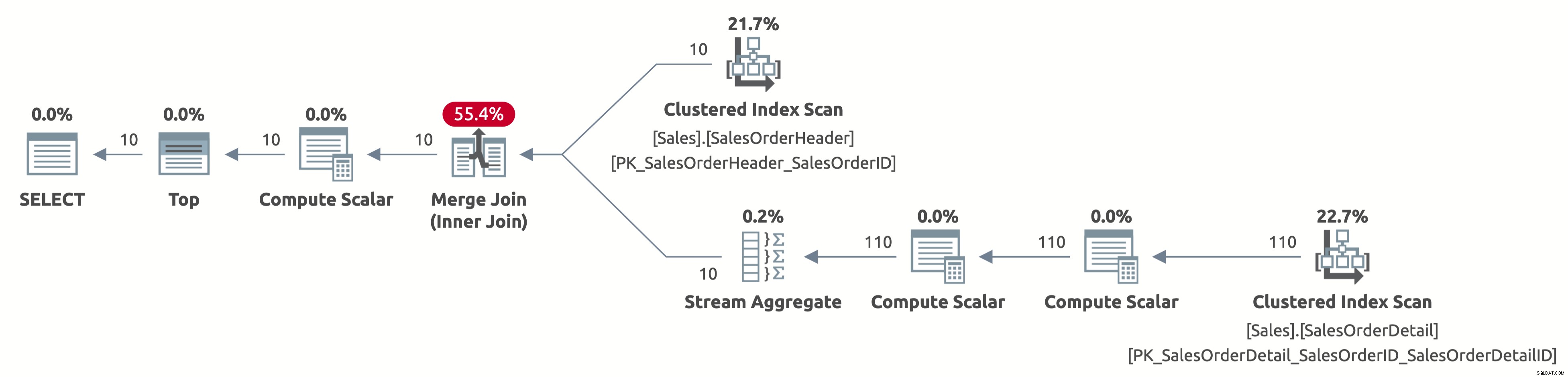
Nyní skenujeme pouze prvních 10 řádků z tabulky Sales.SalesOrderHeader a také skenujeme pouze prvních 110 řádků z tabulky Sales.SalesOrderDetail. Navíc zde není žádný operátor Sort, protože data jsou již řazena podle SalesOrderID.
Zde je výstup statistik IO:
- Tabulka 'SalesOrderDetail'. Počet skenů 1, logické čtení 4
- Tabulka 'SalesOrderHeader'. Počet skenů 1, logické čtení 3
Závěr
Když používáte parametry ke změně struktury dotazu, nepoužívejte v dotazu složité výrazy k odvození očekávaného chování. Ve většině případů to povede ke špatnému výkonu, a to z dobrých důvodů. Prvním důvodem je, že plán bude vygenerován na základě prvního provedení a poté všechna následující provedení znovu použijí stejný plán, který je vhodný pouze pro jednu strukturu dotazu. Druhým důvodem je, že optimalizátor má omezenou schopnost vyhodnotit tyto složité výrazy v době kompilace.
Existuje několik způsobů, jak tyto problémy překonat, a my jsme je prozkoumali v tomto článku. Ve většině případů by nejlepší metodou bylo vytvořit dotaz dynamicky na základě hodnot parametrů. Tímto způsobem bude každá struktura dotazu jednou zkompilována s nejlepším možným plánem.
Když vytváříte dotaz pomocí dynamického SQL, ujistěte se, že používáte parametry tam, kde je to vhodné, a ověřte, zda je váš kód bezpečný.