Vnitřní spojení, vnější spojení, křížové spojení? Co dává?
je to platná otázka. Jednou jsem viděl kód jazyka Visual Basic s vloženými kódy T-SQL. Kód VB načte záznamy tabulky s více příkazy SELECT, jeden SELECT * na tabulku. Potom zkombinuje více sad výsledků do sady záznamů. Absurdní?
Pro mladé vývojáře, kteří to udělali, to nebylo. Ale když mě požádali, abych zhodnotil, proč je systém pomalý, tento problém upoutal moji pozornost jako první. To je správně. Nikdy neslyšeli o připojení SQL. Abychom k nim byli spravedliví, byli upřímní a otevření návrhům.
Jak popisujete SQL spojení? Možná si pamatujete jednu skladbu – Imagine od Johna Lennona:
Můžete říct, že jsem snílek, ale nejsem jediný.
Doufám, že se k nám jednoho dne přidáte a svět bude jako jeden.
V kontextu písně je spojení sjednocující. V databázi SQL sloučení záznamů 2 nebo více tabulek do jedné sady výsledků tvoří spojení .
Tento článek je začátkem 3dílné série pojednávající o SQL join:
- VNITŘNÍ PŘIPOJENÍ
- OUTER JOIN, což zahrnuje LEFT, RIGHT a FULL
- PROVOZNÍ PŘIPOJENÍ
Než však začneme diskutovat o INNER JOIN, popišme připojení obecně.

Více o SQL JOIN
Spojení se objeví hned za klauzulí FROM. Ve své nejjednodušší podobě to vypadá jako použití standardu SQL-92:
FROM <table source> [<alias1>]
<join type> JOIN <table source> [<alias2>] [ON <join condition>]
[<join type> JOIN <table source> [<alias3>] [ON <join condition>]
<join type> JOIN <table source> [<aliasN>] [ON <join condition>]]
[WHERE <condition>]Pojďme si popsat každodenní věci kolem JOIN.
Zdroje tabulek
Podle Microsoftu můžete přidat až 256 zdrojů tabulek. Samozřejmě záleží na zdrojích vašeho serveru. Nikdy v životě jsem se nepřipojil k více než 10 tabulkám, nemluvě k 256. Každopádně zdroje tabulek mohou být následující:
- Tabulka
- Zobrazit
- Synonymum tabulky nebo zobrazení
- Proměnná tabulky
- Funkce s tabulkovou hodnotou
- Odvozená tabulka
Alias tabulky
Alias je volitelný, ale zkracuje váš kód a minimalizuje psaní. Také vám to pomůže vyhnout se chybám, když název sloupce existuje ve dvou nebo více tabulkách použitých v příkazech SELECT, UPDATE, INSERT nebo DELETE. Také to dodává vašemu kódu přehlednost. Je to volitelné, ale já bych doporučil používat aliasy. (Pokud rádi nezadáváte zdroje tabulek podle názvu.)
Podmínka připojení
Klíčové slovo ON předchází podmínce spojení, kterou může být jediné spojení nebo 2-klíčové sloupce ze 2 spojených tabulek. Nebo to může být složené spojení pomocí více než 2 klíčových sloupců. Definuje, jak spolu tabulky souvisí.
Podmínku spojení však používáme pouze pro INNER a OUTER spojení. Použití na CROSS JOIN způsobí chybu.
Protože podmínky spojení definují vztahy, potřebují operátory.
Nejběžnějším operátorem podmínky spojení je operátor rovnosti (=). Ostatní operátory jako> nebo
Většinu spojení lze přepsat jako poddotazy a naopak. V tomto článku se dozvíte více o dílčích dotazech ve srovnání s připojeními.
Použití odvozených tabulek ve spojení vypadá takto:
Připojuje se z výsledku jiného příkazu SELECT a je dokonale platný.
Budete mít více příkladů, ale pojďme se zabývat jednou poslední věcí o SQL JOINS. To je způsob, jakým se procesy SQL Server Query Optimizer spojují.
Abyste pochopili, jak tento proces funguje, musíte vědět o dvou typech operací:
Jedno slovo:Výkon.
Jedna věc je vědět, jak tvořit dotazy se spojeními, aby byly výsledky správné. Dalším je, aby to běželo co nejrychleji. Pokud chcete mít u svých uživatelů dobrou pověst, musíte se tím více zabývat.
Na co si tedy musíte dávat pozor v Plánu provádění těchto logických operací?
Rady pro připojení jsou nové v SQL Server 2019. Když je použijete ve spojeních, sdělí optimalizátoru dotazů, aby přestal rozhodovat o tom, co je pro dotaz nejlepší. Jste šéfem, pokud jde o použití fyzického spojení.
Teď přestaň, hned tam. Pravdou je, že optimalizátor dotazů obvykle vybere nejlepší fyzické spojení pro váš dotaz. Pokud nevíte, co děláte, nepoužívejte rady pro spojení.
Možné tipy, které můžete zadat, jsou LOOP, MERGE, HASH nebo REMOTE.
Nepoužil jsem tipy pro spojení, ale zde je syntaxe:
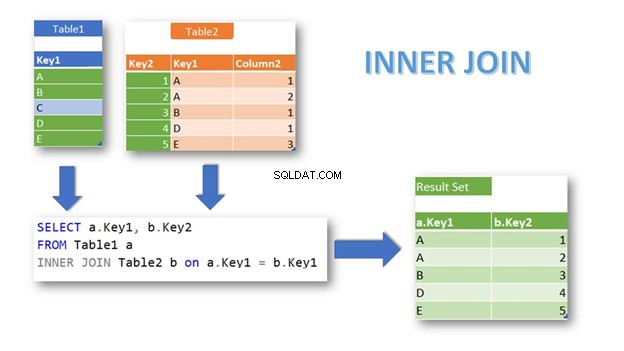
INNER JOIN vrátí řádky s odpovídajícími záznamy v obou tabulkách na základě podmínky. Je to také výchozí spojení, pokud nezadáte klíčové slovo INNER:
Jak vidíte, odpovídající řádky z Tabulky1 a Tabulka2 jsou vráceny pomocí Klíče1 jako podmínku připojení. Tabulka1 záznam s Klíčem1 =‚C‘ je vyloučeno, protože v Tabulce2 nejsou žádné odpovídající záznamy .
Kdykoli vytvořím dotaz, moje první volba je INNER JOIN. OUTER JOIN přichází pouze tehdy, když to vyžadují požadavky.
V T-SQL jsou podporovány dvě syntaxe INNER JOIN:SQL-92 a SQL-89.
První syntaxe spojení, kterou jsem se naučil, byla SQL-89. Když SQL-92 konečně dorazil, myslel jsem, že je příliš zdlouhavý. Také jsem si myslel, že výstup byl stejný, proč se obtěžovat psaním dalších klíčových slov? Grafický návrhář dotazů nechal vygenerovat kód SQL-92 a já jsem jej změnil zpět na SQL-89. Ale dnes dávám přednost SQL-92, i když musím víc psát. Zde je důvod:
Výše uvedené důvody jsou moje. Možná máte své důvody, proč preferujete SQL-92 nebo proč jej nenávidíte. Zajímalo by mě, jaké jsou ty důvody. Dejte mi vědět v sekci Komentáře níže.
Ale nemůžeme tento článek ukončit bez příkladů a vysvětlení.
Zde je příklad 2 tabulek spojených dohromady pomocí INNER JOIN v syntaxi SQL-92.
Zadáte pouze sloupce, které potřebujete. Ve výše uvedeném příkladu jsou zadány 4 sloupce. Vím, že je to příliš dlouhé než SELECT *, ale mějte na paměti:je to osvědčený postup.
Všimněte si také použití aliasů tabulek. Oba Produkt a Podkategorie produktu tabulky mají sloupec s názvem [Název ]. Pokud alias neurčíte, spustí se chyba.
Mezitím je zde ekvivalentní syntaxe SQL-89:
Jsou stejné kromě podmínky spojení smíchané v klauzuli WHERE s klíčovým slovem AND. Ale pod kapotou jsou opravdu stejné? Pojďme si prohlédnout sadu výsledků, STATISTICS IO a Realizační plán.
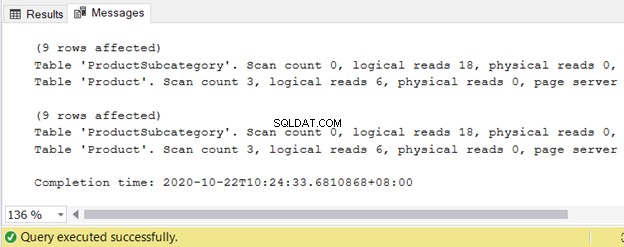
Podívejte se na sadu výsledků 9 záznamů:
Nejde jen o výsledky, ale stejné jsou i zdroje požadované SQL Serverem.
Viz logické čtení:
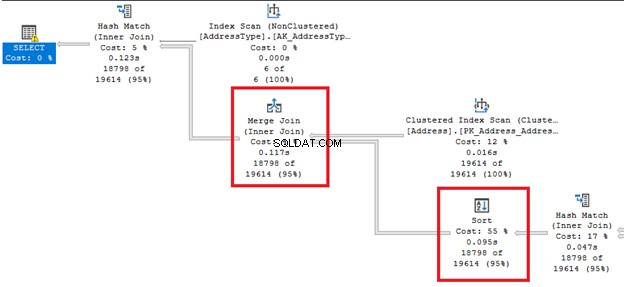
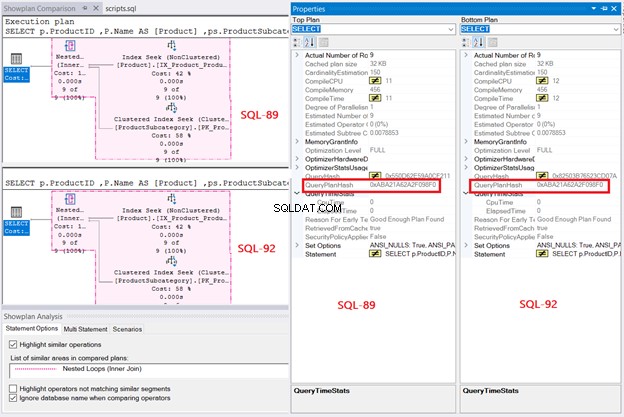
Nakonec plán provádění odhalí stejný plán dotazů pro oba dotazy, když jejich QueryPlanHashes jsou si rovni. Všimněte si také zvýrazněných operací v diagramu:
Na základě zjištění je zpracování dotazů SQL Server stejné, ať už jde o SQL-92 nebo SQL-89. Ale jak jsem řekl, přehlednost v SQL-92 je pro mě mnohem lepší.
Obrázek 7 také ukazuje spojení Nested Loop Join použité v plánu. Proč? Výsledná sada je malá.
Podívejte se na dotaz níže pomocí 3 spojených tabulek.
Můžete také spojit 2 stoly pomocí 2 kláves, abyste je spojili. Podívejte se na ukázku níže. Používá 2 podmínky spojení s operátorem AND.
V níže uvedeném příkladu Produkt tabulka má 9 záznamů – malá sada. Připojený stůl je Detail prodejní objednávky - velká sada. Optimalizátor dotazů použije spojení Nested Loop Join, jak je znázorněno na obrázku 8.
Níže uvedený příklad používá spojení sloučení, protože obě vstupní tabulky jsou seřazeny podle SalesOrderID.
Následující příklad bude používat spojení hash:
V níže uvedeném příkladu Prodejce tabulka má index ColumnStore bez seskupení na TerritoryID sloupec. Optimalizátor dotazů se rozhodl pro spojení Nested Loop Join, jak je znázorněno na obrázku 11.
Zvažte tento příkaz s vnořeným poddotazem:
Stejné výsledky mohou vyjít, pokud jej změníte na INNER JOIN, jak je uvedeno níže:
Dalším způsobem, jak jej přepsat, je použití odvozené tabulky jako zdroje tabulky pro INNER JOIN:
Všechny 3 dotazy vydávají stejných 48 záznamů.
Následující dotaz používá vnořenou smyčku:
Pokud jej chcete vynutit k připojení hash, stane se toto:
Mějte však na paměti, že STATISTICS IO ukazuje, že výkon se zhorší, když jej vynutíte k připojení hash.
Mezitím dotaz níže používá spojení sloučení:
Zde je to, co se stane, když jej přinutíte k vnořené smyčce:
Po kontrole STATISTICS IO obou, vynucení na vnořenou smyčku vyžaduje více zdrojů pro zpracování dotazu:
Použití tipů na spojení by tedy mělo být vaší poslední možností při ladění výkonu. Nechte svůj SQL Server, aby to zvládl za vás.
Můžete také použít INNER JOIN v příkazu UPDATE. Zde je příklad:
Protože je možné použít spojení v UPDATE, proč to nezkusit pomocí DELETE a INSERT?
Co je tedy na SQL join důležité?
Mezitím tento příspěvek ukázal 10 příkladů INNER JOINů. Nejsou to jen ukázkové kódy. Některé z nich zahrnují také kontrolu fungování kódu zevnitř. Není to jen proto, aby vám pomohl s kódováním, ale také proto, abyste měli na paměti výkon. Na konci dne by výsledky neměly být jen správné, ale také rychlé.
ještě jsme neskončili. Příští článek se bude zabývat OUTER JOINS. Zůstaňte naladěni.
SQL Joins vám umožní načítat a kombinovat data z více než jedné tabulky. Podívejte se na toto video a dozvíte se více o SQL Joins.SQL JOIN vs. poddotazy
Joins a odvozené tabulky
FROM table1 a
INNER JOIN (SELECT y.column3 from table2 x
INNER JOIN table3 y on x.column1 = y.column1) b ON a.col1 = b.col2Jak SQL Server zpracovává spojení

Proč se s tím musíme obtěžovat?
Tipy pro připojení
<join type> <join hint> JOIN <table source> [<alias>] ON <join condition>Vše o INNER JOIN
Syntaxe INNER JOIN
VNITŘNÍ PŘIPOJENÍ SQL-92
FROM <table source1> [<alias1>]
INNER JOIN <table source2> [<alias2>] ON <join condition1>
[INNER JOIN <table source3> [<alias3>] ON <join condition2>
INNER JOIN <table sourceN> [<aliasN>] ON <join conditionN>]
[WHERE <condition>]VNITŘNÍ PŘIPOJENÍ SQL-89
FROM <table source1> [alias1], <table source2> [alias2] [, <table source3> [alias3], <table sourceN> [aliasN]]
WHERE (<join condition1>)
[AND (<join condition2>)
AND (<join condition3>)
AND (<join conditionN>)]Která syntaxe INNER JOIN je lepší?
10 příkladů INNER JOIN
1. Spojení 2 stolů
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE P.ProductSubcategoryID IN (25, 31, 33); -- for vest, helmet, and light
-- product subcategories-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p, Production.ProductSubcategory ps
WHERE P.ProductSubcategoryID = ps.ProductSubcategoryID
AND P.ProductSubcategoryID IN (25, 31, 33);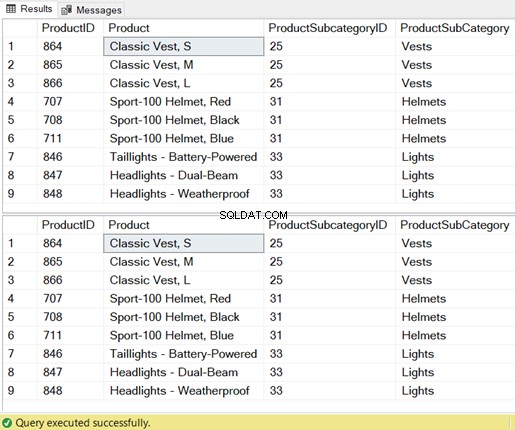
2. Spojení více stolů
-- Get the total number of orders per Product Category
USE AdventureWorks
GO
SELECT
ps.Name AS ProductSubcategory
,SUM(sod.OrderQty) AS TotalOrders
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod ON P.ProductID = sod.ProductID
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '1/1/2014' AND '12/31/2014'
AND p.ProductSubcategoryID IN (1,2)
GROUP BY ps.Name
HAVING ps.Name IN ('Mountain Bikes', 'Road Bikes')3. Složené spojení
SELECT
a.column1
,b.column1
,b.column2
FROM Table1 a
INNER JOIN Table2 b ON a.column1 = b.column1 AND a.column2 = b.column24. VNITŘNÍ SPOJENÍ Pomocí fyzického spojení Nested Loop
USE AdventureWorks
GO
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);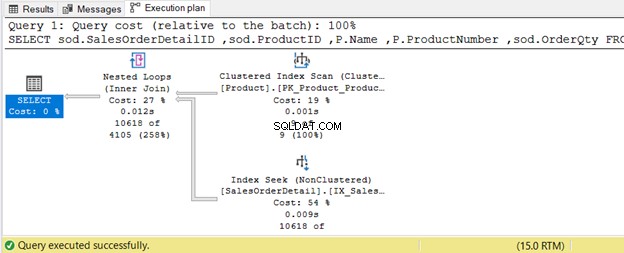
5. VNITŘNÍ SPOJENÍ Použití sloučení fyzického spojení
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID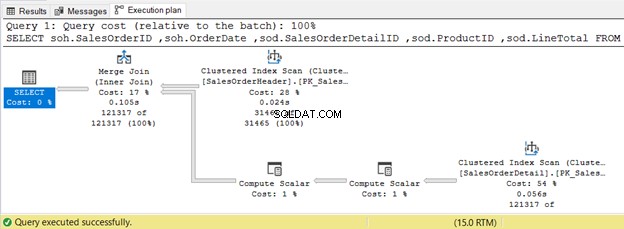
6. VNITŘNÍ SPOJENÍ Použití fyzického spojení hash
SELECT
s.Name AS Store
,SUM(soh.TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.Store s ON soh.SalesPersonID = s.SalesPersonID
GROUP BY s.Name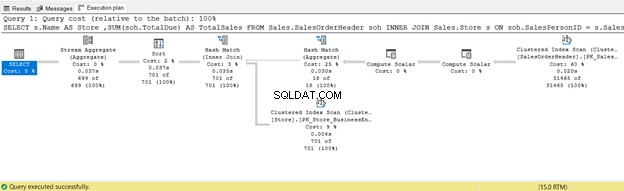
7. VNITŘNÍ SPOJENÍ Pomocí adaptivního fyzického spojení
SELECT
sp.BusinessEntityID
,sp.SalesQuota
,st.Name AS Territory
FROM Sales.SalesPerson sp
INNER JOIN Sales.SalesTerritory st ON sp.TerritoryID = st.TerritoryID
WHERE sp.TerritoryID BETWEEN 1 AND 5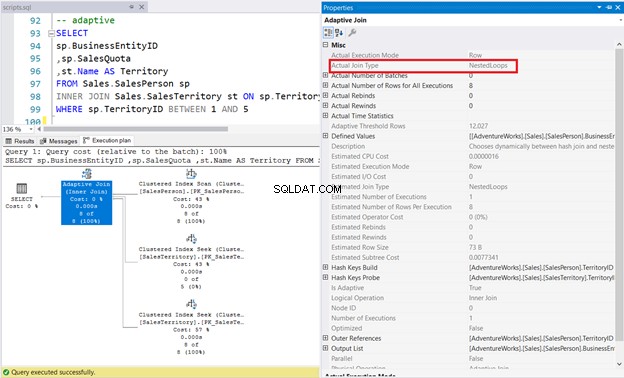
8. Dva způsoby, jak přepsat poddotaz na INNER JOIN
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT [CustomerID] FROM Sales.Customer
WHERE PersonID IN (SELECT BusinessEntityID FROM Person.Person
WHERE lastname LIKE N'I%' AND PersonType='SC'))SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.lastname LIKE N'I%'SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN (SELECT c.CustomerID, P.PersonType, P.LastName
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = P.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.LastName LIKE N'I%') AS q ON o.CustomerID = q.CustomerID9. Pomocí tipů pro spojení
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER HASH JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDSELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID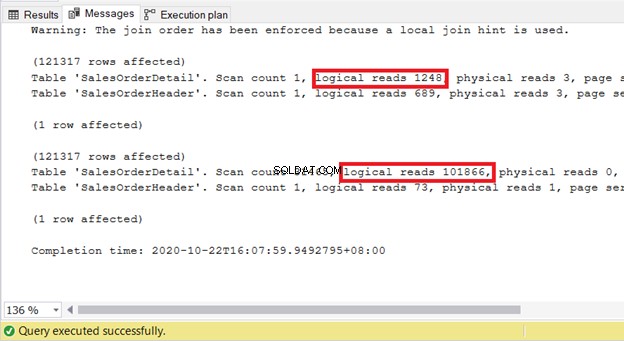
10. Pomocí INNER JOIN v UPDATE
UPDATE Sales.SalesOrderHeader
SET ShipDate = getdate()
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Souhrn SQL Join a INNER JOIN
Viz také