Ve svém předchozím příspěvku jsem diskutoval o čekání CXPACKET a způsobech, jak zabránit nebo omezit paralelismus. Vysvětlil jsem také, jak řídicí vlákno v paralelní operaci vždy registruje čekání CXPACKET a že někdy nekontrolní vlákna mohou také registrovat čekání CXPACKET. K tomu může dojít, pokud je jedno z vláken zablokováno při čekání na zdroj (takže všechna ostatní vlákna skončí před ním a zaregistrují také čekání CXPACKET), nebo pokud jsou odhady mohutnosti nesprávné. V tomto příspěvku bych rád prozkoumal to druhé.
Když jsou odhady mohutnosti nesprávné, paralelní vlákna provádějící dotazovací práci dostanou nerovnoměrné množství práce. Typický případ je, kdy jedno vlákno dostane veškerou práci, nebo mnohem více práce než ostatní vlákna. To znamená, že vlákna, která dokončí zpracování svých řádků (pokud vůbec nějaké dostali) před nejpomalejším vláknem, zaregistrují CXPACKET od okamžiku, kdy skončí, dokud nedokončí nejpomalejší vlákno. Tento problém může vést ke zdánlivé explozi v čekání CXPACKET a běžně se nazývá šikmý paralelismus , protože rozložení práce mezi paralelní vlákna je zkosené, ne rovnoměrné.
Všimněte si, že v SQL Server 2016 SP2 a SQL Server 2017 RTM CU3 již spotřebitelská vlákna neregistrují čekání CXPACKET. Registrují čekání CXCONSUMER, které jsou neškodné a lze je ignorovat. Tím se sníží počet generovaných čekání na CXPACKET a u zbývajících je pravděpodobnější, že budou použitelné.
Příklad šikmé rovnoběžnosti
Projdu si vymyšlený příklad, abych ukázal, jak takové případy identifikovat.
Nejprve vytvořím scénář, ve kterém bude tabulka obsahovat velmi nepřesné statistiky, ručním nastavením počtu řádků a stránek v AKTUALIZACI STATISTIKY prohlášení (nedělejte to ve výrobě!):
USE [master];
GO
IF DB_ID (N'ExecutionMemory') IS NOT NULL
BEGIN
ALTER DATABASE [ExecutionMemory] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [ExecutionMemory];
END
GO
CREATE DATABASE [ExecutionMemory];
GO
USE [ExecutionMemory];
GO
CREATE TABLE dbo.[Test] (
[RowID] INT IDENTITY,
[ParentID] INT,
[CurrentValue] NVARCHAR (100),
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED ([RowID]));
GO
INSERT INTO dbo.[Test] ([ParentID], [CurrentValue])
SELECT
CASE WHEN ([t1].[number] % 3 = 0)
THEN [t1].[number] – [t1].[number] % 6
ELSE [t1].[number] END,
'Test' + CAST ([t1].[number] % 2 AS VARCHAR(11))
FROM [master].[dbo].[spt_values] AS [t1]
WHERE [t1].[type] = 'P';
GO
UPDATE STATISTICS dbo.[Test] ([PK_Test]) WITH ROWCOUNT = 10000000, PAGECOUNT = 1000000;
GO Moje tabulka má tedy jen několik tisíc řádků, ale předstíral jsem, že má 10 milionů řádků.
Nyní vytvořím vykonstruovaný dotaz pro výběr horních 500 řádků, který půjde paralelně, protože si myslí, že existují miliony řádků ke skenování.
USE [ExecutionMemory];
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentValue NVARCHAR (100);
WHILE (1=1)
SELECT TOP (500)
@CurrentValue = [CurrentValue]
FROM dbo.[Test]
ORDER BY NEWID() DESC;
GO A spustit to.
Zobrazení CXPACKET čeká
Nyní se mohu podívat na čekání CXPACKET, která se vyskytují, pomocí jednoduchého skriptu a podívat se na sys.dm_os_waiting_tasks DMV:
SELECT
[owt].[session_id],
[owt].[exec_context_id],
[owt].[wait_duration_ms],
[owt].[wait_type],
[owt].[blocking_session_id],
[owt].[resource_description],
[er].[database_id],
[eqp].[query_plan]
FROM sys.dm_os_waiting_tasks [owt]
INNER JOIN sys.dm_exec_sessions [es] ON
[owt].[session_id] = [es].[session_id]
INNER JOIN sys.dm_exec_requests [er] ON
[es].[session_id] = [er].[session_id]
OUTER APPLY sys.dm_exec_sql_text ([er].[sql_handle]) [est]
OUTER APPLY sys.dm_exec_query_plan ([er].[plan_handle]) [eqp]
WHERE
[es].[is_user_process] = 1
ORDER BY
[owt].[session_id],
[owt].[exec_context_id]; Pokud to několikrát provedu, nakonec uvidím některé výsledky ukazující zkreslený paralelismus (odstranil jsem odkaz na zpracování plánu dotazů a omezil popis zdroje, aby bylo jasné, a všiml jsem si, že jsem vložil kód, abych uchopil text SQL, pokud to chcete také):
| id_relace | exec_context_id | wait_duration_ms | wait_type | blocking_session_id | resource_description | database_id |
|---|---|---|---|---|---|---|
56 | 0 | 1 | CXPACKET | NULL | exchangeEvent | 13 |
56 | 1 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 3 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 4 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 5 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 6 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 7 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
Výsledky ukazující zkreslený paralelismus v akci
Řídicí vlákno je vlákno s exec_context_id nastavena na 0. Další paralelní vlákna jsou ta s exec_context_id vyšší než 0 a všechny zobrazují čekání CXPACKET kromě jednoho (všimněte si, že exec_context_id = 2 v seznamu chybí). Všimněte si, že všichni uvádějí své vlastní session_id jako ten, který je blokuje, a to je správné, protože všechna vlákna čekají na další vlákno ze svého vlastního session_id dokončit. database_id je databáze, v jejímž kontextu se dotaz provádí, ne nutně databáze, kde je problém, ale obvykle tomu tak je, pokud dotaz nepoužívá třídílné pojmenování k provedení v jiné databázi.
Zobrazení problému odhadu mohutnosti
Pomocí plánu_dotazů sloupec ve výstupu dotazu (který jsem kvůli přehlednosti odstranil), můžete na něj kliknout a vyvolat grafický plán a poté kliknout pravým tlačítkem a vybrat Zobrazit s průzkumníkem plánů SQL Sentry. To ukazuje níže:
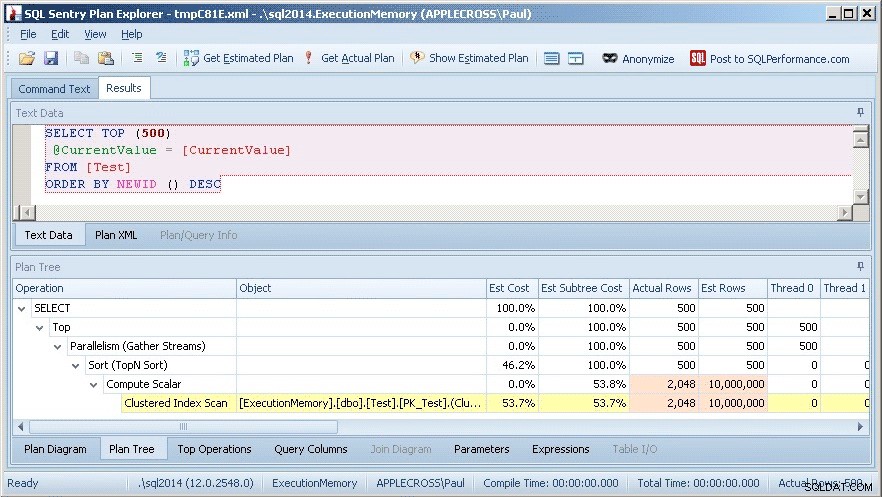
Okamžitě vidím, že existuje problém s odhadem mohutnosti, protože skutečné řádky pro skenování sdruženého indexu jsou pouze 2 048 ve srovnání s 10 000 000 odhadovanými (odhadovanými) řádky.
Když roluji napříč, vidím rozložení řádků napříč paralelními vlákny, která byla použita:
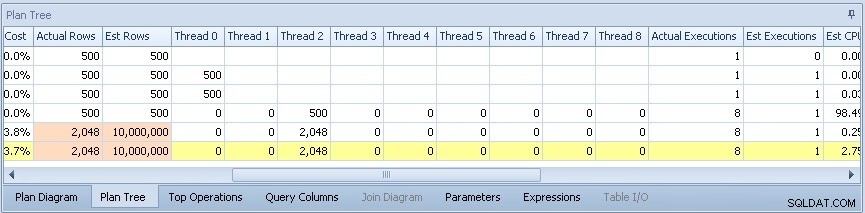
Hle, během paralelní části plánu pracovalo pouze jediné vlákno – to, které se nezobrazilo v sys.dm_os_waiting_tasks výstup výše.
V tomto případě je opravou aktualizace statistik pro tabulku.
V mém vymyšleném příkladu to nebude fungovat, protože v tabulce nebyly provedeny žádné úpravy, takže znovu spustím nastavovací skript a vynechám UPDATE STATISTICS prohlášení.
Plán dotazů se poté změní na:
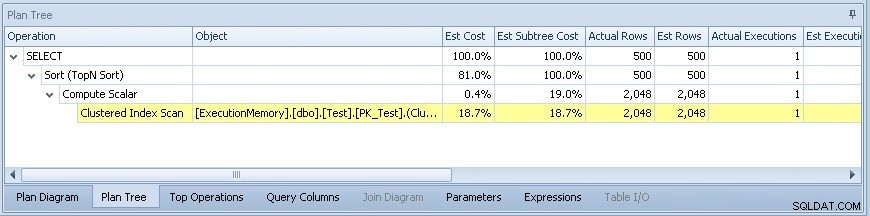
Tam, kde není problém mohutnosti ani paralelismus – problém vyřešen!
Shrnutí
Pokud vidíte, že dochází k čekání CXPACKET, je snadné zkontrolovat zkosenou rovnoběžnost pomocí výše popsané metody. Všechny případy, které jsem viděl, byly způsobeny problémy s odhadem mohutnosti toho či onoho druhu a často je to jednoduše případ aktualizace statistik.
Pokud jde o obecné statistiky čekání, více informací o jejich použití pro odstraňování problémů s výkonem naleznete v:
- Moje série příspěvků na blogu SQLskills, počínaje statistikou čekání, nebo mi prosím řekněte, kde to bolí
- Moje knihovna typů čekání a tříd Latch zde
- Online školicí kurz My Pluralsight SQL Server:Odstraňování problémů s výkonem pomocí statistiky čekání
- Sledování SQL
Do příště přejeme hodně štěstí při odstraňování problémů!