Myslím, že každý již zná můj názor na MERGE a proč se od toho držím dál. Ale tady je další (anti-)vzor, který všude vidím, když lidé chtějí provést upsert (aktualizovat řádek, pokud existuje, a vložit jej, pokud ne):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Vypadá to jako docela logický tok, který odráží, jak o tom přemýšlíme v reálném životě:
- Existuje již pro tento klíč řádek?
- ANO :OK, aktualizujte tento řádek.
- NE :OK, pak to přidejte.
To je ale plýtvání.
Vyhledání řádku pro potvrzení jeho existence, jen když jej budete muset najít znovu, abyste jej mohli aktualizovat, dělá dvakrát práci pro nic. I když je klíč indexovaný (což doufám vždy platí). Pokud tuto logiku vložím do vývojového diagramu a v každém kroku přiřadím typ operace, která by se musela v databázi uskutečnit, měl bych toto:
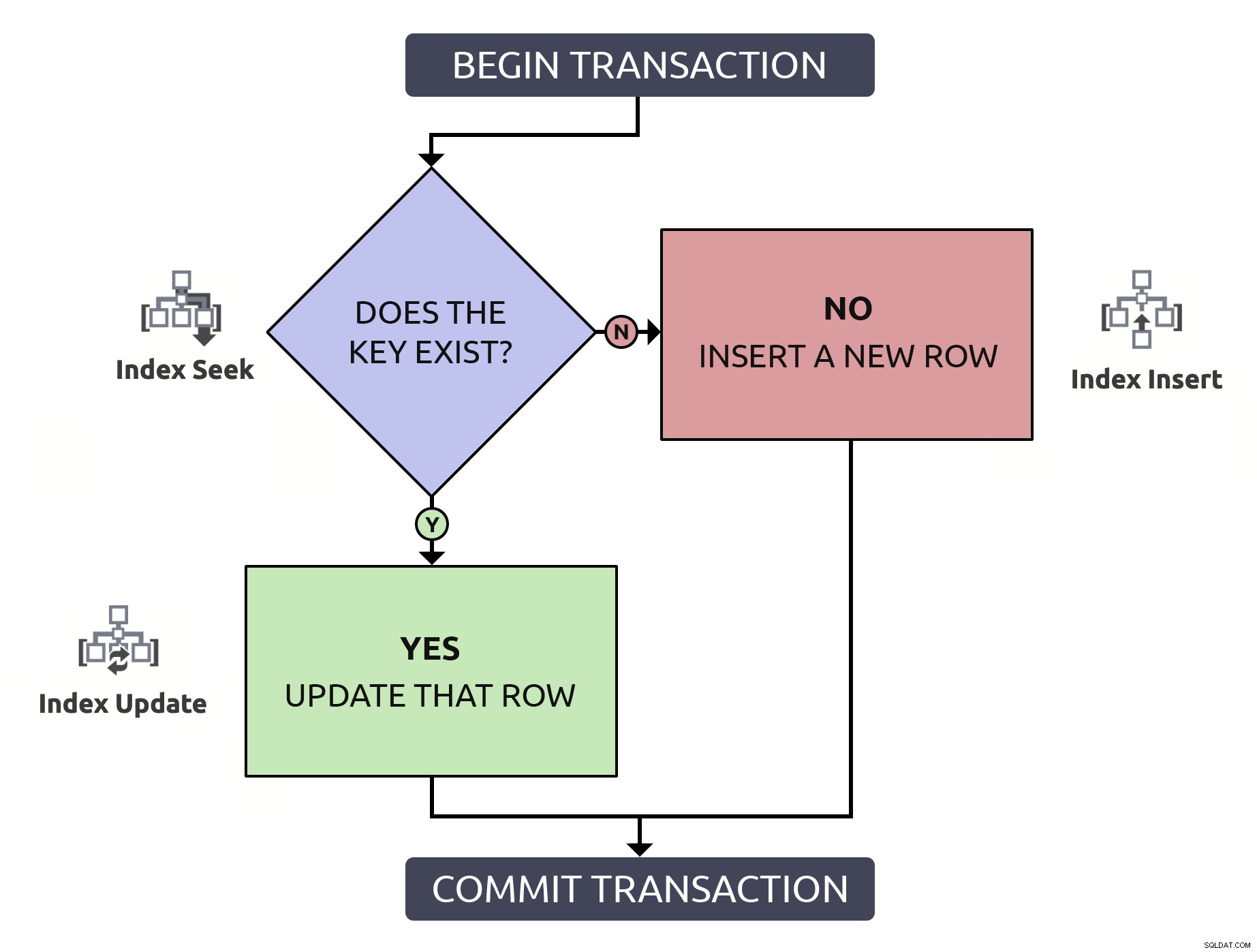 Všimněte si, že všechny cesty budou vyžadovat dvě operace indexování.
Všimněte si, že všechny cesty budou vyžadovat dvě operace indexování.
A co je důležitější, kromě výkonu, pokud nepoužijete explicitní transakci a nezvýšíte úroveň izolace, může se mnoho věcí pokazit, když řádek ještě neexistuje:
- Pokud klíč existuje a dvě relace se pokusí aktualizovat současně, obě se aktualizují úspěšně (jeden „vyhraje“; „poražený“ bude následovat se změnou, která zůstane, což povede ke „ztracené aktualizaci“). To není problém sám o sobě a tak bychom to měli očekávat, že systém se souběžností bude fungovat. Paul White zde hovoří o vnitřní mechanice podrobněji a Martin Smith zde hovoří o některých dalších nuancích.
- Pokud klíč neexistuje, ale obě relace projdou kontrolou existence stejným způsobem, může se stát cokoli, když se obě pokusí vložit:
- zablokování kvůli nekompatibilním zámkům;
- upozorňovat na chyby porušení klíčových slov to se nemělo stát; nebo,
- vložte duplicitní hodnoty klíče pokud tento sloupec není správně omezen.
Ten poslední je nejhorší, IMHO, protože je to ten, který potenciálně poškozuje data . Zablokování a výjimky lze snadno zvládnout pomocí věcí, jako je zpracování chyb, XACT_ABORT a opakujte logiku v závislosti na tom, jak často očekáváte kolize. Ale pokud jste ukolébáni pocitem bezpečí, že IF EXISTS Kontrola vás chrání před duplikáty (nebo narušeními klíče), což je překvapení, které se teprve stane. Pokud očekáváte, že sloupec bude fungovat jako klíč, udělejte to oficiální a přidejte omezení.
„Mnoho lidí říká…“
Dan Guzman hovořil o podmínkách závodu před více než deseti lety v Conditional INSERT/UPDATE Race Condition a později v "UPSERT" Race Condition With MERGE.
Michael Swart se tímto tématem také několikrát zabýval:
- Boření mýtů:Souběžná řešení aktualizací/vkládání – kde uznal, že ponechání původní logiky na místě a pouze zvýšení úrovně izolace jen změnilo porušování klíčových slov na uváznutí;
- Buďte opatrní s prohlášením o sloučení – kde ověřil své nadšení z
MERGE; a - Čeho se vyvarovat, pokud chcete použít MERGE – kde znovu potvrdil, že stále existuje spousta platných důvodů, proč se
MERGEi nadále vyhýbat .
Nezapomeňte si také přečíst všechny komentáře u všech tří příspěvků.
Řešení
Ve své kariéře jsem opravil mnoho patových situací jednoduchým přizpůsobením se následujícímu vzoru (vynechám nadbytečnou kontrolu, zabalím sekvenci do transakce a ochráním přístup k prvnímu stolu vhodným uzamčením):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Proč potřebujeme dvě rady? Není UPDLOCK dost?
UPDLOCKse používá k ochraně před zablokováním konverze v příkazu úroveň (nechte další sezení čekat místo vybízení oběti k opakování).SERIALIZABLEse používá k ochraně před změnami podkladových dat během transakce (zajistěte, aby řádek, který neexistuje, nadále neexistoval).
Je to trochu více kódu, ale je to o 1000 % bezpečnější a dokonce v nejhorším případ (řádek již neexistuje), chová se stejně jako anti-vzor. V nejlepším případě, pokud aktualizujete řádek, který již existuje, bude efektivnější najít tento řádek pouze jednou. Kombinací této logiky s operacemi na vysoké úrovni, které by se musely dít v databázi, je to o něco jednodušší:
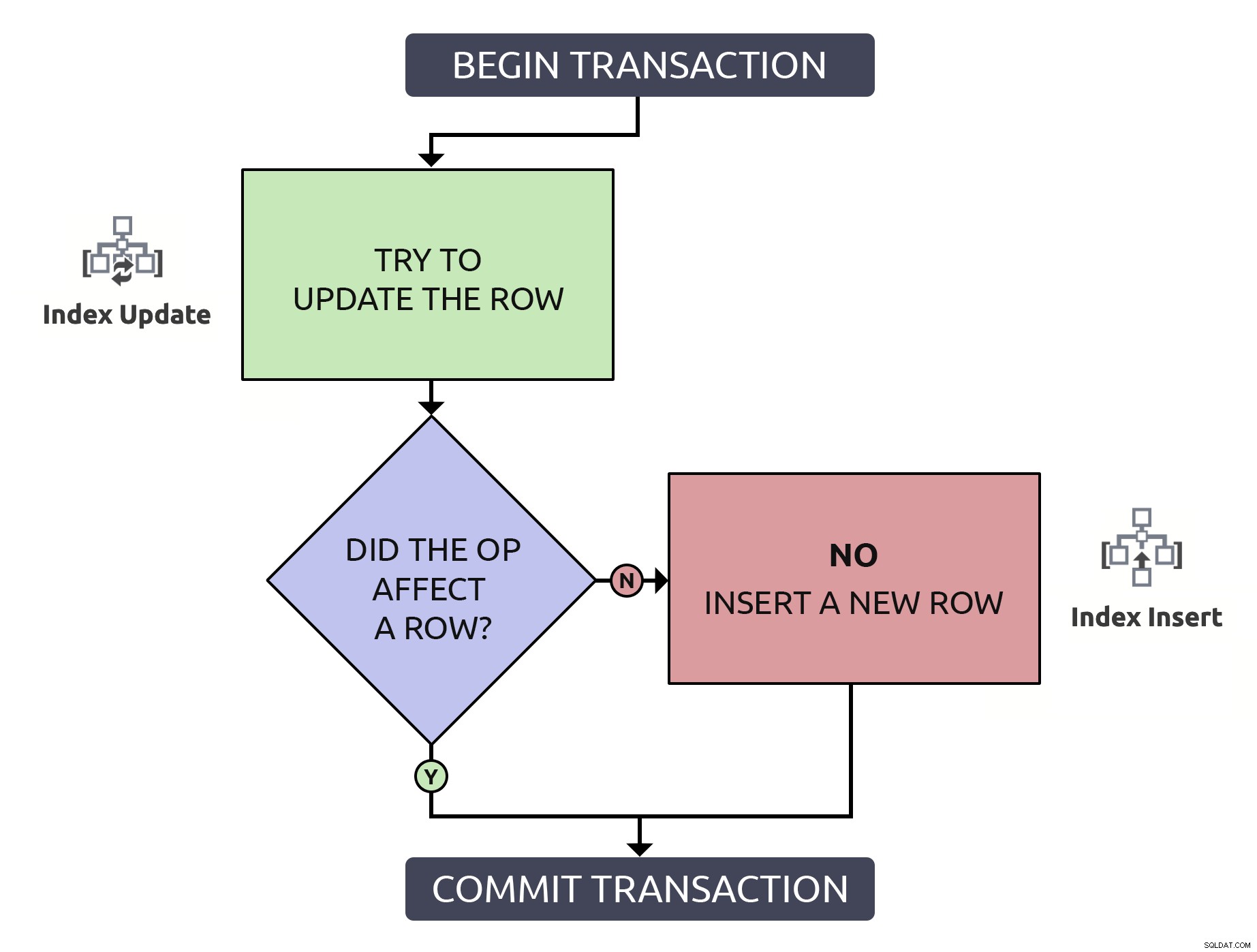 V tomto případě jedna cesta znamená pouze jednu operaci indexování.
V tomto případě jedna cesta znamená pouze jednu operaci indexování.
Ale opět výkon stranou:
- Pokud klíč existuje a dvě relace se jej pokusí aktualizovat současně, oba se vystřídají a řádek úspěšně aktualizují , jako předtím.
- Pokud klíč neexistuje, jedna relace „vyhraje“ a vloží řádek . Druhý bude muset počkat dokud se zámky neuvolní, aby zkontrolovaly existenci a nebyly nuceny aktualizovat.
V obou případech pisatel, který vyhrál závod, ztratí svá data kvůli čemukoli, co po něm "poražený" aktualizoval.
Všimněte si, že celková propustnost na vysoce souběžném systému může trpět, ale to je kompromis, který byste měli být ochotni udělat. To, že máte mnoho obětí uváznutí nebo chyb narušení klíče, ale stávají se rychle, není dobrá metrika výkonu. Někteří lidé by byli rádi, kdyby bylo veškeré blokování odstraněno ze všech scénářů, ale některé z nich blokují, co si absolutně přejete pro integritu dat.
Co když je ale aktualizace méně pravděpodobná?
Je jasné, že výše uvedené řešení je optimalizováno pro aktualizace a předpokládá, že klíč, do kterého se pokoušíte zapisovat, již bude v tabulce existovat nejméně tak často, jako tomu tak není. Pokud byste raději optimalizovali pro vložky, protože víte nebo tušíte, že vložky budou pravděpodobnější než aktualizace, můžete obrátit logiku a přesto mít bezpečnou operaci upsert:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Existuje také přístup „jen to udělej“, kdy slepě vkládáte a necháte kolize vyvolávat výjimky pro volajícího:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Náklady na tyto výjimky často převáží náklady na první kontrolu; budete to muset zkusit se zhruba přesným odhadem míry zásahu/chyby. Psal jsem o tom zde a zde.
A co upserting více řádků?
Výše uvedené pojednává o rozhodnutích o vložení/aktualizaci jednotlivých položek, ale Justin Pealing se zeptal, co dělat, když zpracováváte více řádků, aniž byste věděli, které z nich již existují?
Za předpokladu, že odesíláte sadu řádků pomocí něčeho jako parametr s hodnotou tabulky, aktualizujete pomocí spojení a poté vložíte pomocí NEEXISTUJE, ale vzor by byl stále ekvivalentní prvnímu přístupu výše:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Pokud dáváte dohromady více řádků nějakým jiným způsobem než TVP (XML, čárkami oddělený seznam, voodoo), vložte je nejprve do formuláře tabulky a připojte se k čemukoli. Dávejte pozor, abyste v tomto scénáři nejprve neoptimalizovali pro vložky, jinak byste potenciálně aktualizovali některé řádky dvakrát.
Závěr
Tyto upsert vzory jsou lepší než ty, které vidím až příliš často, a doufám, že je začnete používat. Ukážu na tento příspěvek pokaždé, když objevím IF EXISTS vzor ve volné přírodě. A, hej, další pokřik pro Paula Whitea (sql.kiwi | @SQK_Kiwi), protože je tak skvělý v tom, jak usnadnit pochopení a vysvětlování složitých pojmů.
A pokud máte pocit, že musíte použijte MERGE , prosím, ne @ mě; buď k tomu máte dobrý důvod (možná potřebujete nějaký obskurní MERGE -pouze funkčnost), nebo jste výše uvedené odkazy nebrali vážně.