Tento článek je šestou částí série o tabulkových výrazech. Minulý měsíc v části 5 jsem se zabýval logickým zpracováním nerekurzivních CTE. Tento měsíc se zabývám logickým zpracováním rekurzivních CTE. Popisuji podporu T-SQL pro rekurzivní CTE a také standardní prvky, které zatím T-SQL nepodporuje. Poskytuji logicky ekvivalentní řešení T-SQL pro nepodporované prvky.
Ukázková data
Pro ukázková data použiji tabulku nazvanou Zaměstnanci, která obsahuje hierarchii zaměstnanců. Sloupec empid představuje ID zaměstnance podřízeného (podřízený uzel) a sloupec mgrid představuje ID zaměstnance vedoucího (nadřazený uzel). K vytvoření a naplnění tabulky Zaměstnanci v databázi tempdb použijte následující kód:
SET NOCOUNT ON; USE tempdb;DROP TABLE IF EXISTS dbo.Employees;GO CREATE TABLE dbo.Employees( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees5,REPLEYD CHECK (empid <> mgrid)); INSERT INTO dbo.Employees(empid, mgrid, empname, plat) VALUES(1, NULL, 'David' , 10000,00 USD), (2, 1, 'Eitan' , 7000,00 USD), (3, 1, 'Ina' 0.0 000,00 USD) , (4, 2, 'Seraph' , 5000,00 USD), (5, 2, 'Jiru' , 5500,00 USD), (6, 2, 'Steve' , 4500,00 USD), (7, 3, 'Aaron' , 5000,00 USD), ( 8, 5, 'Lilach' , 3500,00 USD), (9, 7, 'Rita' , 3000,00 USD), (10, 5, 'Sean' , 3000,00 USD), (11, 7, 'Gabriel', 3000,00 USD), (12, 9, 'Emilia' , 2 000,00 USD), (13, 9, 'Michael', 2 000,00 USD), (14, 9, 'Didi' , 1 500,00 USD); VYTVOŘIT UNIKÁTNÍ INDEX idx_unc_mgrid_empid NA dbo.Employees(mgrid, empid) INCLUDE(zaměstnanecké jméno, plat);
Všimněte si, že kořen hierarchie zaměstnanců – CEO – má ve sloupci mgrid hodnotu NULL. Všichni ostatní zaměstnanci mají manažera, takže jejich sloupec mgrid je nastaven na ID zaměstnance jejich manažera.
Na obrázku 1 je graficky znázorněna hierarchie zaměstnanců se jménem zaměstnance, ID a jeho umístěním v hierarchii.
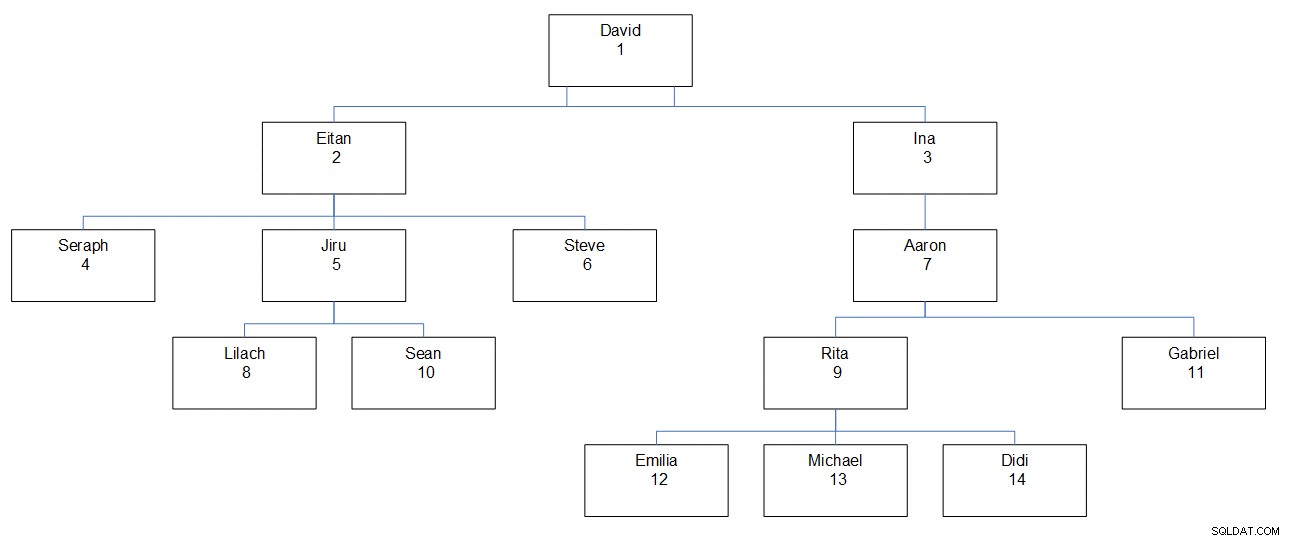 Obrázek 1:Hierarchie zaměstnanců
Obrázek 1:Hierarchie zaměstnanců
Rekurzivní CTE
Rekurzivní CTE mají mnoho případů použití. Klasická kategorie použití má co do činění s manipulací s grafovými strukturami, jako je naše hierarchie zaměstnanců. Úlohy zahrnující grafy často vyžadují procházení drah libovolné délky. Například s ohledem na ID zaměstnance nějakého vedoucího vraťte vstupního zaměstnance, stejně jako všechny podřízené vstupního zaměstnance na všech úrovních; tedy přímí a nepřímí podřízení. Pokud jste měli známý malý limit na počet úrovní, které možná budete muset sledovat (stupeň grafu), můžete použít dotaz se spojením na úroveň podřízených. Pokud je však stupeň grafu potenciálně vysoký, v určitém okamžiku se stává nepraktickým psát dotaz s mnoha spojeními. Další možností je použít imperativní iterativní kód, ale taková řešení bývají zdlouhavá. To je místo, kde rekurzivní CTE skutečně září – umožňují vám používat deklarativní, stručná a intuitivní řešení.
Začnu se základy rekurzivních CTE, než se dostanu k zajímavějším věcem, kde se budu věnovat vyhledávání a cyklování.
Pamatujte, že syntaxe dotazu na CTE je následující:
WITHAS
(
)
Zde ukazuji jeden CTE definovaný pomocí klauzule WITH, ale jak víte, můžete definovat více CTE oddělených čárkami.
V běžných, nerekurzivních CTE je výraz vnitřní tabulky založen na dotazu, který je vyhodnocen pouze jednou. V rekurzivních CTE je výraz vnitřní tabulky založen na typicky dvou dotazech známých jako členové , i když můžete mít více než dva, abyste zvládli některé specializované potřeby. Členové jsou obvykle odděleni operátorem UNION ALL, což znamená, že jejich výsledky jsou jednotné.
Člen může být členem kotvy —to znamená, že se hodnotí pouze jednou; nebo to může být rekurzivní člen —to znamená, že je vyhodnocován opakovaně, dokud nevrátí prázdnou sadu výsledků. Zde je syntaxe dotazu na rekurzivní CTE, který je založen na jednom kotevním členu a jednom rekurzivním členu:
SAS
(
<člen kotvy>
UNION ALL
)
To, co dělá člena rekurzivním, je odkaz na název CTE. Tato reference představuje sadu výsledků posledního spuštění. Při prvním spuštění rekurzivního členu představuje odkaz na název CTE výslednou sadu členu kotvy. V N-tém provedení, kde N> 1, představuje odkaz na jméno CTE sadu výsledků (N – 1) provedení rekurzivního člena. Jak bylo zmíněno, jakmile rekurzivní člen vrátí prázdnou množinu, znovu se nespustí. Odkaz na název CTE ve vnějším dotazu představuje sjednocené sady výsledků jediného provedení členu kotvy a všech provedení rekurzivního člena.
Následující kód implementuje výše uvedenou úlohu vrácení podstromu zaměstnanců pro daného správce vstupu a v tomto příkladu předá ID zaměstnance 3 jako kořenového zaměstnance:
DECLARE @root AS INT =3; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;
Kotevní dotaz se provede pouze jednou a vrátí řádek pro vstupního kořenového zaměstnance (v našem případě zaměstnance 3).
Rekurzivní dotaz spojuje množinu zaměstnanců z předchozí úrovně – reprezentovanou odkazem na jméno CTE s aliasem M pro manažery – s jejich přímými podřízenými z tabulky Zaměstnanci s aliasem S pro podřízené. Predikát spojení je S.mgrid =M.empid, což znamená, že hodnota mgrid podřízeného se rovná hodnotě empid manažera. Rekurzivní dotaz se provede čtyřikrát následovně:
- Vraťte podřízené zaměstnance 3; výstup:zaměstnanec 7
- Vraťte podřízené zaměstnance 7; výkon:zaměstnanci 9 a 11
- Návrat podřízení zaměstnanců 9 a 11; výstup:12, 13 a 14
- Vraťte podřízené zaměstnance 12, 13 a 14; výstup:prázdná sada; rekurze se zastaví
Odkaz na jméno CTE ve vnějším dotazu představuje sjednocené výsledky jediného provedení kotevního dotazu (zaměstnanec 3) s výsledky všech provedení rekurzivního dotazu (zaměstnanci 7, 9, 11, 12, 13 a 14). Tento kód generuje následující výstup:
empid mgrid empname------ ------ --------3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi
Běžným problémem v programovacích řešeních je nekontrolovaný kód, jako jsou nekonečné smyčky, které jsou obvykle způsobeny chybou. U rekurzivních CTE by chyba mohla vést ke spuštění dráhy rekurzivního člena. Předpokládejme například, že v našem řešení pro vracení podřízených vstupního zaměstnance jste měli chybu v predikátu spojení rekurzivního člena. Místo použití ON S.mgrid =M.empid jste použili ON S.mgrid =S.mgrid, například takto:
DECLARE @root AS INT =3; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =S .mgrid)SELECT empid, mgrid, empnameFROM C;
Pokud je v tabulce přítomen alespoň jeden zaměstnanec s nenulovým ID manažera, provádění rekurzivního člena bude vracet neprázdný výsledek. Pamatujte, že implicitní podmínkou ukončení pro rekurzivní člen je, když jeho provedení vrátí prázdnou sadu výsledků. Pokud vrátí neprázdnou sadu výsledků, SQL Server ji provede znovu. Uvědomujete si, že kdyby SQL Server neměl mechanismus pro omezení rekurzivních spouštění, jen by neustále spouštěl rekurzivního člena opakovaně. Jako bezpečnostní opatření T-SQL podporuje volbu dotazu MAXRECURSION, která omezuje maximální povolený počet spuštění rekurzivního člena. Ve výchozím nastavení je tento limit nastaven na 100, ale můžete jej změnit na libovolnou nezápornou hodnotu SMALLINT, přičemž 0 představuje žádný limit. Nastavení maximálního limitu rekurze na kladnou hodnotu N znamená, že N + 1 pokus o provedení rekurzivního členu je přerušen s chybou. Například spuštění výše uvedeného chybového kódu tak, jak je, znamená, že se spoléháte na výchozí maximální limit rekurze 100, takže provedení 101 rekurzivního člena selže:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Zpráva 530, úroveň 16, stav 1, řádek 121
Výpis byl ukončen. Maximální rekurze 100 byla vyčerpána před dokončením příkazu.
Řekněme, že ve vaší organizaci je bezpečné předpokládat, že hierarchie zaměstnanců nepřesáhne 6 úrovní řízení. Maximální limit rekurze můžete pro jistotu snížit ze 100 na mnohem menší číslo, například 10, například takto:
DECLARE @root AS INT =3; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =S .mgrid)SELECT empid, mgrid, empnameFROM COPTION (MAXRECURSION 10);
Pokud se nyní vyskytne chyba, která má za následek nekontrolované spuštění rekurzivního člena, bude odhalena při 11 pokusech o provedení rekurzivního členu namísto při spuštění 101:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Zpráva 530, úroveň 16, stav 1, řádek 149
Výpis byl ukončen. Maximální rekurze 10 byla vyčerpána před dokončením příkazu.
Je důležité poznamenat, že maximální limit rekurze by měl být používán hlavně jako bezpečnostní opatření k přerušení provádění chybového runaway kódu. Pamatujte, že při překročení limitu je provádění kódu přerušeno s chybou. Tuto možnost byste neměli používat k omezení počtu úrovní, které lze navštívit pro účely filtrování. Nechcete, aby se generovala chyba, když s kódem není žádný problém.
Pro účely filtrování můžete omezit počet úrovní, které chcete programově navštívit. Definujete sloupec nazvaný lvl, který sleduje číslo úrovně aktuálního zaměstnance ve srovnání se vstupním kořenovým zaměstnancem. V kotevním dotazu nastavíte sloupec lvl na konstantu 0. V rekurzivním dotazu jej nastavíte na manažerovu hodnotu lvl plus 1. Chcete-li filtrovat tolik úrovní pod kořenem vstupu jako @maxlevel, přidejte predikát M.lvl <@ maxlevel na klauzuli ON rekurzivního dotazu. Například následující kód vrátí zaměstnance 3 a dvě úrovně podřízených zaměstnance 3:
DECLARE @root AS INT =3, @maxlevel AS INT =2; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER PŘIPOJTE SE k dbo.Zaměstnanci JAKO S ON S.mgrid =M.empid AND M.lvl <@maxlevel)SELECT empid, mgrid, empname, lvlFROM C;
Tento dotaz generuje následující výstup:
empid mgrid empname lvl------ ------ -------- ----3 1 Ina 07 3 Aaron 19 7 Rita 211 7 Gabriel 2
Standardní klauzule SEARCH a CYCLE
Standard ISO/IEC SQL definuje dvě velmi výkonné možnosti pro rekurzivní CTE. Jedním z nich je klauzule nazvaná SEARCH, která řídí pořadí rekurzivního vyhledávání, a další klauzule zvaná CYCLE, která identifikuje cykly v projetých cestách. Zde je standardní syntaxe pro dvě klauzule:
7.18Funkce
Zadejte generování informací o řazení a detekci cyklu ve výsledku výrazů rekurzivního dotazu.
Formátovat
::=
AS
HLEDAT
DEPTH FIRST BY
CYCLE
VÝCHOZÍ
V době psaní tohoto článku T-SQL tyto možnosti nepodporuje, ale na následujících odkazech můžete najít požadavky na vylepšení funkcí, které žádají o jejich zahrnutí do T-SQL v budoucnu, a hlasovat pro ně:
- Přidat podporu pro klauzuli ISO/IEC SQL SEARCH do rekurzivních CTE v T-SQL
- Přidat podporu pro klauzuli ISO/IEC SQL CYCLE do rekurzivních CTE v T-SQL
V následujících částech popíši dvě standardní možnosti a také poskytnu logicky ekvivalentní alternativní řešení, která jsou aktuálně dostupná v T-SQL.
Klauzule SEARCH
Standardní klauzule SEARCH definuje pořadí rekurzivního vyhledávání jako BREADTH FIRST nebo DEPTH FIRST podle některých specifikovaných sloupců řazení a vytváří nový sloupec sekvence s pořadovými pozicemi navštívených uzlů. Nejprve zadáte BREADTH FIRST pro vyhledávání nejprve napříč každou úrovní (šířka) a poté dolů po úrovních (hloubka). Zadáte DEPTH FIRST pro vyhledávání nejprve dolů (hloubka) a poté napříč (šířka).
Přímo před vnějším dotazem zadáte klauzuli SEARCH.
Začnu příkladem prvního rekurzivního vyhledávání v šířce. Pamatujte, že tato funkce není k dispozici v T-SQL, takže nebudete moci skutečně spouštět příklady, které používají standardní klauzule v SQL Server nebo Azure SQL Database. Následující kód vrátí podstrom zaměstnance 1 a požádá o pořadí prvního vyhledávání podle šířky podle empid, čímž vytvoří sloupec sekvence nazvaný seqbreadth s pořadovými pozicemi navštívených uzlů:
DECLARE @root AS INT =1; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid) HLEDAT ŠÍŘKU PRVNÍ POMOCÍ empid SET seqbreadth----------------------------------------- ---- SELECT empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Zde je požadovaný výstup tohoto kódu:
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Seraph 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
Nenechte se zmást tím, že hodnoty seqbreadth se zdají být totožné s hodnotami empid. To je jen náhoda v důsledku způsobu, jakým jsem ručně přiřadil hodnoty empid ve vzorových datech, která jsem vytvořil.
Obrázek 2 obsahuje grafické znázornění hierarchie zaměstnanců s tečkovanou čarou znázorňující šířku prvního řádu, ve kterém byly uzly prohledávány. Hodnoty empid se zobrazují přímo pod jmény zaměstnanců a přiřazené hodnoty seqbreadth se zobrazují v levém dolním rohu každého pole.
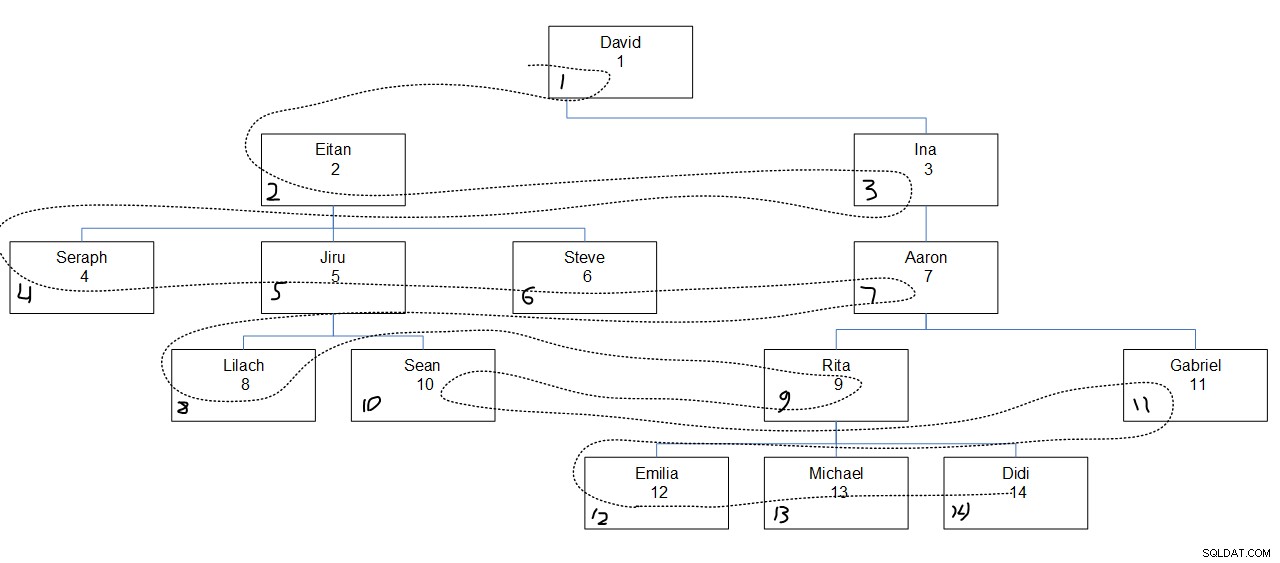 Obrázek 2:Nejprve na šířku vyhledávání
Obrázek 2:Nejprve na šířku vyhledávání
Zde je zajímavé poznamenat, že v rámci každé úrovně jsou uzly prohledávány na základě zadaného pořadí sloupců (v našem případě prázdné) bez ohledu na nadřazené přidružení uzlu. Všimněte si například, že ve čtvrté úrovni je Lilach zpřístupněn jako první, Rita jako druhá, Sean jako třetí a Gabriel jako poslední. Je to proto, že mezi všemi zaměstnanci ve čtvrté úrovni je jejich pořadí založené na jejich prázdných hodnotách. Není to tak, že by Lilach a Sean měli hledat postupně, protože jsou přímými podřízenými stejného manažera, Jiru.
Je poměrně jednoduché přijít s řešením T-SQL, které poskytuje logický ekvivalent standardní možnosti SAERCH DEPTH FIRST. Vytvoříte sloupec nazvaný lvl, jak jsem ukázal dříve, abyste mohli sledovat úroveň uzlu s ohledem na kořen (0 pro první úroveň, 1 pro druhou atd.). Potom pomocí funkce ROW_NUMBER vypočítáte požadovaný sloupec sekvence výsledků ve vnějším dotazu. Jako pořadí okna zadáte nejprve lvl a poté požadovaný sloupec řazení (v našem případě prázdný). Zde je úplný kód řešení:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER PŘIPOJTE SE k dbo.Zaměstnanci JAKO S NA S.mgrid =M.empid)VYBERTE empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM CORDER BY seqbreadth;
Dále se podívejme na pořadí vyhledávání DEPTH FIRST. Podle standardu by měl následující kód vracet podstrom zaměstnance 1 s dotazem na hloubku prvního pořadí hledání podle empid, čímž by se vytvořil sekvenční sloupec nazvaný seqdepth s pořadovými pozicemi prohledávaných uzlů:
DECLARE @root AS INT =1; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid) HLOUBKA HLEDÁNÍ PRVNÍ POMOCÍ empid SET seqdepth---------------------------------------- SELECT empid, mgrid, empname, seqdepthFROM CORDER BY seqdepth;
Následuje požadovaný výstup tohoto kódu:
empid mgrid empname seqdepth------ ------ -------- ---------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
Při pohledu na požadovaný výstup dotazu je pravděpodobně těžké zjistit, proč byly sekvenční hodnoty přiřazeny tak, jak byly. Obrázek 3 by měl pomoci. Má grafické znázornění hierarchie zaměstnanců s tečkovanou čarou odrážející hloubku prvního pořadí hledání, s přiřazenými sekvenčními hodnotami v levém dolním rohu každého pole.
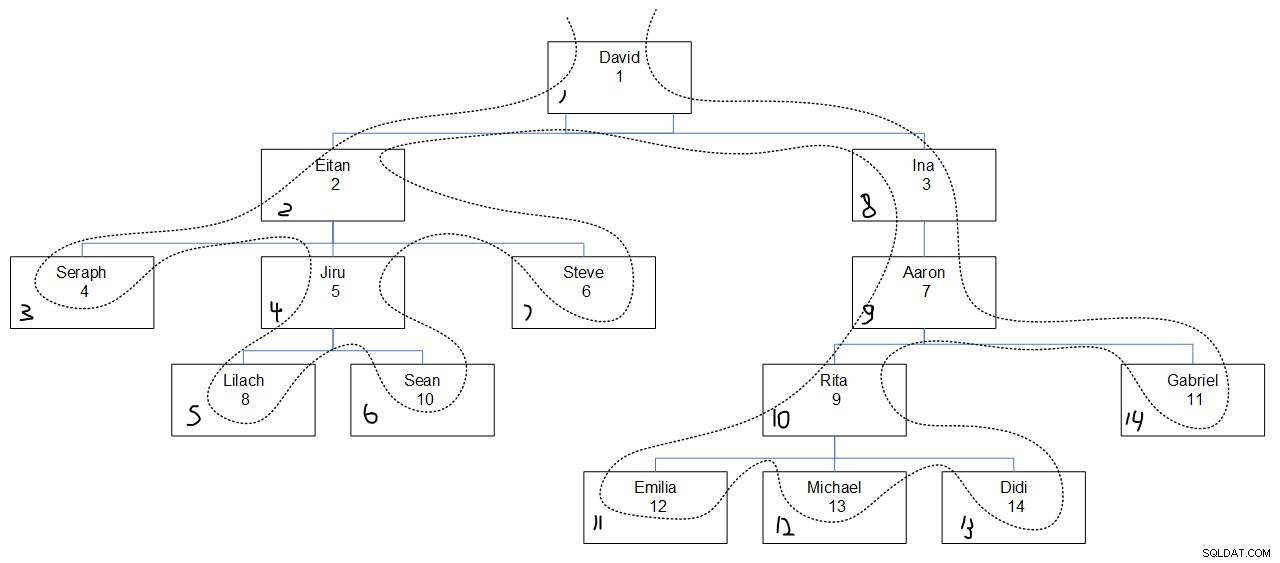 Obrázek 3:Nejprve hloubka vyhledávání
Obrázek 3:Nejprve hloubka vyhledávání
Přijít s řešením T-SQL, které poskytuje logický ekvivalent ke standardní volbě SEARCH DEPTH FIRST, je trochu složité, ale proveditelné. Řešení popíšu ve dvou krocích.
V kroku 1 pro každý uzel vypočítáte binární třídicí cestu, která se skládá ze segmentu na předchůdce uzlu, přičemž každý segment odráží pořadí řazení předka mezi jeho sourozenci. Tuto cestu vytvoříte podobně jako vypočítáte sloupec lvl. To znamená, že začněte s prázdným binárním řetězcem pro kořenový uzel v kotevním dotazu. Poté v rekurzivním dotazu zřetězíte cestu rodiče s pozicí řazení uzlu mezi sourozenci poté, co jej převedete na binární segment. Pomocí funkce ROW_NUMBER vypočítáte pozici, rozdělenou podle rodiče (v našem případě mgrid) a seřazenou podle příslušného sloupce řazení (v našem případě empid). Číslo řádku převedete na binární hodnotu dostatečné velikosti v závislosti na maximálním počtu přímých potomků, které může mít rodič ve vašem grafu. BINARY(1) podporuje až 255 dětí na rodiče, BINARY(2) podporuje 65 535, BINARY(3):16 777 215, BINARY(4):4 294 967 295. V rekurzivním CTE musí být odpovídající sloupce v kotevním a rekurzivním dotazu stejného typu a velikosti , takže se ujistěte, že jste v obou převedli cestu řazení na binární hodnotu stejné velikosti.
Zde je kód implementující krok 1 v našem řešení (za předpokladu, že BINARY(1) je dostatečné na segment, což znamená, že nemáte více než 255 přímých podřízených na jednoho manažera):
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL VYBERTE S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Zaměstnanci JAKO S NA S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Tento kód generuje následující výstup:
empid mgrid empname cesta řazení------ ------ -------- -----------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 RITA 0x02010111 7 Gabriel 0x02010212 9 Emilia 0x0201010113 9 Michael 0x0201010214 9 Didi 0x020101034 2 Seraph 0x01015 2 Jiru 0x01026 2 SEANVšimněte si, že jsem jako třídicí cestu pro kořenový uzel jediného podstromu, který zde dotazujeme, použil prázdný binární řetězec. V případě, že člen kotvy může potenciálně vracet více kořenů podstromu, jednoduše začněte segmentem, který je založen na výpočtu ROW_NUMBER v dotazu kotvy, podobně jako to počítáte v rekurzivním dotazu. V takovém případě bude vaše cesta řazení o jeden segment delší.
Co zbývá udělat v kroku 2, je vytvořit požadovaný sloupec seqdepth pomocí výpočtu čísel řádků, které jsou seřazeny podle cesty řazení ve vnějším dotazu, podobně
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL VYBERTE S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Zaměstnanci JAKO S NA S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepthFROM CORDER BY seqdepth;Toto řešení je logickým ekvivalentem použití standardní možnosti SEARCH DEPTH FIRST zobrazené výše spolu s požadovaným výstupem.
Jakmile budete mít sloupec sekvence odrážející hloubku prvního pořadí hledání (v našem případě seqdepth), s trochou většího úsilí můžete vytvořit velmi pěkné vizuální zobrazení hierarchie. Dále budete potřebovat zmíněný sloupec lvl. Vnější dotaz seřadíte podle sloupce sekvence. Vrátíte nějaký atribut, který chcete použít k reprezentaci uzlu (řekněme, empname v našem případě), předponou nějaký řetězec (řekněme ' | ') replikovaný lvl krát. Zde je úplný kód pro dosažení takového vizuálního zobrazení:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath OD C AS M INNER JOIN dbo.Zaměstnanci JAKO S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seqdepth;Tento kód generuje následující výstup:
empid seqdepth emp------ --------- --------------------1 1 David2 2 | Eitan4 3 | | Seraph5 4 | | Jiru8 5 | | | Lilach10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aaron9 10 | | | Rita12 11 | | | | Emilia13 12 | | | | Michael14 13 | | | | Didi11 14 | | | GabrielTo je skvělé!
Klauzule CYCLE
Struktury grafu mohou mít cykly. Tyto cykly mohou být platné nebo neplatné. Příkladem platných cyklů je graf představující dálnice a silnice spojující města a obce. Tomu se říká cyklický graf . Naopak graf představující hierarchii zaměstnanců jako v našem případě nemá mít cykly. Tomu se říká acyklický graf. Předpokládejme však, že kvůli nějaké chybné aktualizaci neúmyslně skončíte s cyklem. Předpokládejme například, že omylem aktualizujete ID manažera generálního ředitele (zaměstnance 1) na zaměstnance 14 spuštěním následujícího kódu:
AKTUALIZOVAT SET mgrid zaměstnanců =14WHERE empid =1;Nyní máte v hierarchii zaměstnanců neplatný cyklus.
Ať už jsou cykly platné nebo neplatné, když procházíte grafovou strukturou, určitě nechcete opakovaně procházet cyklickou cestu. V obou případech chcete přestat sledovat cestu, jakmile je nalezen neprvní výskyt stejného uzlu, a označit takovou cestu jako cyklickou.
Co se tedy stane, když se dotazujete na graf, který má cykly pomocí rekurzivního dotazu, bez mechanismu, který by je detekoval? To závisí na implementaci. V SQL Server v určitém okamžiku dosáhnete maximálního limitu rekurze a váš dotaz bude přerušen. Za předpokladu, že jste například spustili výše uvedenou aktualizaci, která zavedla cyklus, zkuste spustit následující rekurzivní dotaz k identifikaci podstromu zaměstnance 1:
DECLARE @root AS INT =1; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;Protože tento kód nestanovuje explicitní maximální limit rekurze, předpokládá se výchozí limit 100. SQL Server přeruší provádění tohoto kódu před dokončením a vygeneruje chybu:
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aaron...Zpráva 530, úroveň 16, stav 1, řádek 432
Výpis byl ukončen. Maximální rekurze 100 byla vyčerpána před dokončením příkazu.Standard SQL definuje klauzuli nazvanou CYCLE pro rekurzivní CTE, která vám umožňuje pracovat s cykly v grafu. Tuto klauzuli zadáte těsně před vnějším dotazem. Pokud je přítomna také klauzule SEARCH, zadejte ji nejprve a poté klauzuli CYCLE. Zde je syntaxe klauzule CYCLE:
CYCLE
NASTAVITTO VÝCHOZÍ
POUŽITÍDetekce cyklu je založena na zadaném seznamu sloupců cyklu . Například v naší hierarchii zaměstnanců byste pro tento účel pravděpodobně chtěli použít sloupec empid. Když se stejná hodnota empid objeví podruhé, je detekován cyklus a dotaz již takovou cestu nesleduje. Určíte nový sloupec značky cyklu to bude indikovat, zda byl cyklus nalezen nebo ne, a vaše vlastní hodnoty jako značka cyklu a značka bez cyklu hodnoty. Mohou to být například 1 a 0 nebo „Ano“ a „Ne“ nebo jakékoli jiné hodnoty podle vašeho výběru. V klauzuli USING zadáte nový název sloupce pole, který bude obsahovat cestu dosud nalezených uzlů.
Zde je návod, jak byste zpracovali požadavek na podřízené některého vstupního kořenového zaměstnance se schopností detekovat cykly na základě prázdného sloupce s uvedením 1 ve sloupci značky cyklu, když je detekován cyklus, a 0 v opačném případě:
DECLARE @root AS INT =1; WITH C AS( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid) CYCLE empid SET cycle TO 1 DEFAULT 0------------------------------------- ZVOLTE empid, mgrid, empnameFROM C;Zde je požadovaný výstup tohoto kódu:
empid mgrid empname cycle------ ------ -------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0T-SQL v současné době nepodporuje klauzuli CYCLE, ale existuje řešení, které poskytuje logický ekvivalent. Zahrnuje tři kroky. Připomeňme, že dříve jste vytvořili binární třídicí cestu pro zpracování rekurzivního pořadí vyhledávání. Podobným způsobem, jako první krok řešení, vytvoříte cestu předků založenou na řetězci znaků složenou z ID uzlů (v našem případě ID zaměstnanců) předků vedoucích k aktuálnímu uzlu, včetně aktuálního uzlu. Chcete oddělovače mezi ID uzlů, včetně jednoho na začátku a jednoho na konci.
Zde je kód pro vytvoření takové cesty předků:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM dbo.Zaměstnanci WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid) VYBERTE empid, mgrid, empname, ancpathFROM C;Tento kód generuje následující výstup, stále sleduje cyklické cesty, a proto se před dokončením přeruší, jakmile je překročen maximální limit rekurze:
empid mgrid empname ancpath------ ------ -------- -------------------1 14 David . 1,2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 97 Michael ..1 13,14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron..7 .1.. ...Zpráva 530, úroveň 16, stav 1, řádek 492
Výpis byl ukončen. Maximální rekurze 100 byla vyčerpána před dokončením příkazu.Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path
'.1.3.7.9.14.1.'.In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;Run the recursive query and you will find that there are no cycles present.
Závěr
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.