V části 5 mé série o tabulkových výrazech jsem poskytl následující řešení pro generování řady čísel pomocí CTE, konstruktoru hodnot tabulky a křížových spojení:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Existuje mnoho praktických případů použití takového nástroje, včetně generování řady hodnot data a času, vytváření vzorových dat a dalších. Některé platformy uznávají společnou potřebu a poskytují vestavěný nástroj, jako je funkce create_series PostgreSQL. V době psaní tohoto článku T-SQL nenabízí takový vestavěný nástroj, ale vždy lze doufat a hlasovat pro to, aby takový nástroj v budoucnu byl přidán.
V komentáři k mému článku Marcos Kirchner zmínil, že testoval mé řešení s různými kardinalitami konstruktoru hodnot tabulky a získal různé doby provedení pro různé kardinality.
 Vždy jsem používal své řešení s mohutností konstruktoru hodnot základní tabulky 2, ale Marcosův komentář mě donutil přemýšlet. Tento nástroj je tak užitečný, že bychom jako komunita měli spojit síly a pokusit se vytvořit nejrychlejší verzi, jakou můžeme. Testování různých kardinalit základních tabulek je jen jedna dimenze, kterou je třeba vyzkoušet. Mohlo by být mnoho dalších. Uvedu výkonnostní testy, které jsem se svým řešením provedl. Experimentoval jsem hlavně s různými kardinalitami konstruktoru hodnot tabulky, se sériovým versus paralelním zpracováním a se zpracováním v režimu řádků versus v dávkovém režimu. Může se však stát, že úplně jiné řešení je ještě rychlejší než moje nejlepší verze. Takže výzva je na světě! Volám všechny jedi, padawany, čaroděje i učedníky. Jaké je nejvýkonnější řešení, které můžete vykouzlit? Máte na to, abyste porazili dosud zveřejněné nejrychlejší řešení? Pokud ano, sdílejte svůj komentář jako komentář k tomuto článku a neváhejte vylepšit jakékoli řešení zveřejněné ostatními.
Vždy jsem používal své řešení s mohutností konstruktoru hodnot základní tabulky 2, ale Marcosův komentář mě donutil přemýšlet. Tento nástroj je tak užitečný, že bychom jako komunita měli spojit síly a pokusit se vytvořit nejrychlejší verzi, jakou můžeme. Testování různých kardinalit základních tabulek je jen jedna dimenze, kterou je třeba vyzkoušet. Mohlo by být mnoho dalších. Uvedu výkonnostní testy, které jsem se svým řešením provedl. Experimentoval jsem hlavně s různými kardinalitami konstruktoru hodnot tabulky, se sériovým versus paralelním zpracováním a se zpracováním v režimu řádků versus v dávkovém režimu. Může se však stát, že úplně jiné řešení je ještě rychlejší než moje nejlepší verze. Takže výzva je na světě! Volám všechny jedi, padawany, čaroděje i učedníky. Jaké je nejvýkonnější řešení, které můžete vykouzlit? Máte na to, abyste porazili dosud zveřejněné nejrychlejší řešení? Pokud ano, sdílejte svůj komentář jako komentář k tomuto článku a neváhejte vylepšit jakékoli řešení zveřejněné ostatními.
Požadavky:
- Implementujte své řešení jako inline funkci s hodnotou tabulky (iTVF) s názvem dbo.GetNumsYourName s parametry @low AS BIGINT a @high AS BIGINT. Jako příklad se podívejte na ty, které uvádím na konci tohoto článku.
- V případě potřeby můžete v databázi uživatelů vytvořit podpůrné tabulky.
- Podle potřeby můžete přidat rady.
- Jak již bylo zmíněno, řešení by mělo podporovat oddělovače typu BIGINT, ale můžete předpokládat maximální mohutnost série 4 294 967 296.
- Aby bylo možné vyhodnotit výkon vašeho řešení a porovnat jej s ostatními, otestuji jej v rozsahu 1 až 100 000 000, přičemž v SSMS je povoleno zahodit výsledky po spuštění.
Hodně štěstí nám všem! Ať vyhraje nejlepší komunita.;)
Různé mohutnosti konstruktoru hodnot základní tabulky
Experimentoval jsem s různými mohutnostmi základního CTE, počínaje 2 a postupujícími v logaritmické škále, s druhou mocninou předchozí mohutnosti v každém kroku:2, 4, 16 a 256.
Než začnete experimentovat s různými základními kardinalitami, mohlo by být užitečné mít vzorec, který by vám daný základní kardinalitou a maximální kardinalitou rozsahu řekl, kolik úrovní CTE potřebujete. Jako předběžný krok je snazší nejprve přijít se vzorcem, který na základě základní kardinality a počtu úrovní CTE vypočítá maximální výslednou kardinalitu rozsahu. Zde je takový vzorec vyjádřený v T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
S výše uvedenými vzorovými vstupními hodnotami tento výraz poskytuje maximální kardinalitu rozsahu 4 294 967 296.
Potom inverzní vzorec pro výpočet počtu potřebných úrovní CTE zahrnuje vnoření dvou funkcí protokolu, například takto:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
S výše uvedenými vzorovými vstupními hodnotami tento výraz dává 5. Všimněte si, že toto číslo je dodatkem k základnímu CTE, který má konstruktor hodnot tabulky, který jsem ve svém řešení pojmenoval L0 (pro úroveň 0).
Neptejte se mě, jak jsem se k těmto vzorcům dostal. Příběh, kterého se držím, je ten, že mi je Gandalf pronesl v elfštině v mých snech.
Pojďme k testování výkonu. Ujistěte se, že jste povolili Zahodit výsledky po spuštění v dialogovém okně Možnosti dotazu SSMS v části Mřížka, Výsledky. Pomocí následujícího kódu spusťte test se základní mohutností CTE 2 (vyžaduje 5 dalších úrovní CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Získal jsem plán znázorněný na obrázku 1 pro toto provedení.
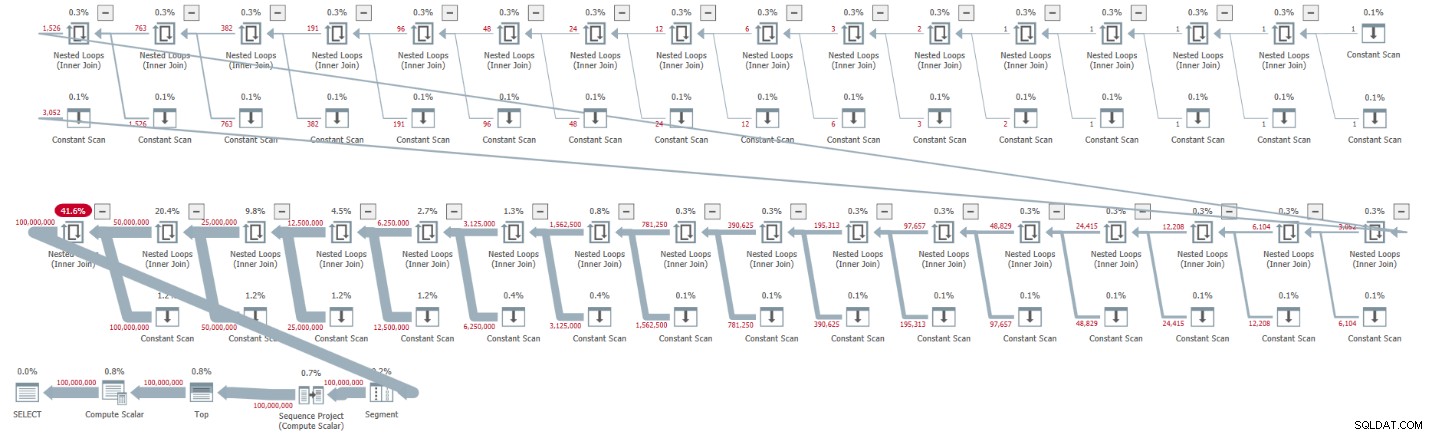 Obrázek 1:Plán základní kardinality CTE 2
Obrázek 1:Plán základní kardinality CTE 2
Plán je sériový a všichni operátoři v plánu standardně používají zpracování v režimu řádků. Pokud ve výchozím nastavení získáváte paralelní plán, např. při zapouzdření řešení do iTVF a použití velkého rozsahu, prozatím si vynucte sériový plán s nápovědou MAXDOP 1.
Podívejte se, jak rozbalení CTE vedlo ke 32 instancím operátoru Constant Scan, z nichž každá představuje tabulku se dvěma řádky.
Získal jsem následující statistiky výkonu pro toto provedení:
CPU time = 30188 ms, elapsed time = 32844 ms.
Pomocí následujícího kódu otestujte řešení se základní mohutností CTE 4, která podle našeho vzorce vyžaduje čtyři úrovně CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Získal jsem plán znázorněný na obrázku 2 pro toto provedení.
 Obrázek 2:Plán základní kardinality CTE 4
Obrázek 2:Plán základní kardinality CTE 4
Rozbalení CTE vedlo k 16 operátorům konstantního skenování, z nichž každý představuje tabulku se 4 řádky.
Získal jsem následující statistiky výkonu pro toto provedení:
CPU time = 23781 ms, elapsed time = 25435 ms.
To je slušné zlepšení o 22,5 procenta oproti předchozímu řešení.
Při zkoumání statistik čekání hlášených pro dotaz je dominantním typem čekání SOS_SCHEDULER_YIELD. Ve skutečnosti počet čekání překvapivě klesl o 22,8 procenta ve srovnání s prvním řešením (počet čekání 15 280 oproti 19 800).
Pomocí následujícího kódu otestujte řešení se základní mohutností CTE 16, která podle našeho vzorce vyžaduje tři úrovně CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Získal jsem plán znázorněný na obrázku 3 pro toto provedení.
 Obrázek 3:Plán pro základní kardinalitu CTE 16
Obrázek 3:Plán pro základní kardinalitu CTE 16
Tentokrát rozbalení CTE vedlo k 8 operátorům konstantního skenování, z nichž každý představuje tabulku se 16 řádky.
Získal jsem následující statistiky výkonu pro toto provedení:
CPU time = 22968 ms, elapsed time = 24409 ms.
Toto řešení dále zkracuje uplynulý čas, i když jen o několik dalších procent, což představuje snížení o 25,7 procenta ve srovnání s prvním řešením. Opět platí, že počet čekání typu čekání SOS_SCHEDULER_YIELD stále klesá (12 938).
Další test, který pokračuje v naší logaritmické škále, zahrnuje základní kardinalitu CTE 256. Je to dlouhé a ošklivé, ale zkuste to:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Získal jsem plán znázorněný na obrázku 4 pro toto provedení.
 Obrázek 4:Plán pro základní kardinalitu CTE 256
Obrázek 4:Plán pro základní kardinalitu CTE 256
Tentokrát mělo rozbalení CTE za následek pouze čtyři operátory konstantního skenování, každý s 256 řádky.
Získal jsem následující čísla výkonu pro toto provedení:
CPU time = 23516 ms, elapsed time = 25529 ms.
Tentokrát se zdá, že výkon se ve srovnání s předchozím řešením se základní kardinalitou CTE 16 trochu zhoršil. Čekací počet typu čekání SOS_SCHEDULER_YIELD se skutečně trochu zvýšil na 13 176. Zdá se tedy, že jsme našli naše zlaté číslo – 16!
Paralelní versus sériové plány
Experimentoval jsem s vynucením paralelního plánu pomocí nápovědy ENABLE_PARALLEL_PLAN_PREFERENCE, ale nakonec to poškodilo výkon. Ve skutečnosti, když jsem implementoval řešení jako iTVF, měl jsem na svém počítači standardně paralelní plán pro velké rozsahy a musel jsem vynutit sériový plán s MAXDOP 1 nápovědou, abych dosáhl optimálního výkonu.
Dávkové zpracování
Hlavním zdrojem používaným v plánech pro moje řešení je CPU. Vzhledem k tomu, že dávkové zpracování je především o zlepšení efektivity CPU, zejména při práci s velkým počtem řádků, vyplatí se tuto možnost vyzkoušet. Hlavní činností, která může těžit z dávkového zpracování, je výpočet počtu řádků. Svá řešení jsem testoval v SQL Server 2019 Enterprise edition. SQL Server ve výchozím nastavení zvolil zpracování v režimu řádků pro všechna dříve zobrazená řešení. Toto řešení zjevně neprošlo heuristikou potřebnou k povolení dávkového režimu na rowstore. Existuje několik způsobů, jak přimět SQL Server, aby zde používal dávkové zpracování.
Možnost 1 je zahrnout do řešení tabulku s indexem columnstore. Můžete toho dosáhnout vytvořením fiktivní tabulky s indexem columnstore a zavedením fiktivního levého spojení v nejvzdálenějším dotazu mezi naším Nums CTE a touto tabulkou. Zde je definice fiktivní tabulky:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Poté upravte vnější dotaz proti Nums tak, aby používal FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Zde je příklad se základní kardinalitou CTE 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Mám plán znázorněný na obrázku 5 pro toto provedení.
 Obrázek 5:Plán s dávkovým zpracováním
Obrázek 5:Plán s dávkovým zpracováním
Sledujte použití agregačního operátoru okna dávkového režimu k výpočtu čísel řádků. Všimněte si také, že plán nezahrnuje falešný stůl. Optimalizátor to optimalizoval.
Výhodou možnosti 1 je, že funguje ve všech edicích SQL Server a je relevantní pro SQL Server 2016 nebo novější, protože v SQL Server 2016 byl zaveden operátor Window Aggregate v dávkovém režimu. Nevýhodou je potřeba vytvořit fiktivní tabulku a zahrnout je v řešení.
Možnost 2, jak získat dávkové zpracování pro naše řešení, za předpokladu, že používáte SQL Server 2019 Enterprise edition, je použít nezdokumentovanou samovysvětlující nápovědu OVERRIDE_BATCH_MODE_HEURISTICS (podrobnosti v článku Dmitrije Pilugina), například takto:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Výhodou možnosti 2 je, že nemusíte vytvářet fiktivní tabulku a zapojovat ji do svého řešení. Nevýhodou je, že musíte používat Enterprise edition, používat minimálně SQL Server 2019, kde byl zaveden dávkový režim na rowstore, a řešení zahrnuje použití nezdokumentované nápovědy. Z těchto důvodů preferuji možnost 1.
Zde jsou čísla výkonu, která jsem získal pro různé základní kardinality CTE:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Obrázek 6 ukazuje srovnání výkonu mezi různými řešeními:
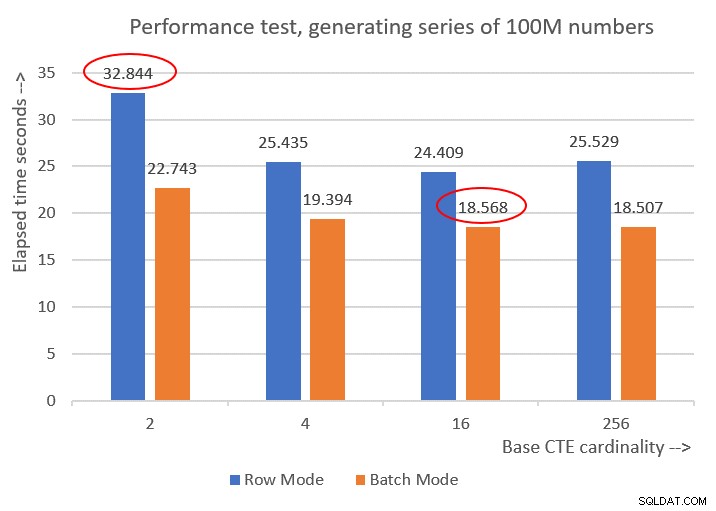 Obrázek 6:Porovnání výkonu
Obrázek 6:Porovnání výkonu
Můžete pozorovat slušné zlepšení výkonu o 20–30 procent oproti protějškům v režimu řádků.
Je zajímavé, že s dávkovým zpracováním se nejlépe dařilo řešení se základní CTE mohutností 256. Je to však jen o malý kousek rychlejší než řešení se základní CTE kardinalitou 16. Rozdíl je tak nepatrný a druhé řešení má jasnou výhodu ve stručnosti kódu, že bych se držel 16.
Moje ladění tedy skončilo tak, že přineslo zlepšení o 43,5 procenta oproti původnímu řešení se základní mohutností 2 pomocí zpracování v režimu řádků.
Výzva je spuštěna!
Jako příspěvek komunity k této výzvě předkládám dvě řešení. Pokud používáte SQL Server 2016 nebo novější a jste schopni vytvořit tabulku v uživatelské databázi, vytvořte následující fiktivní tabulku:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A použijte následující definici iTVF:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO K otestování použijte následující kód (ujistěte se, že máte zaškrtnuté políčko Zahodit výsledky po provedení):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Tento kód na mém počítači skončí za 18 sekund.
Pokud z jakéhokoli důvodu nemůžete splnit požadavky na řešení pro dávkové zpracování, předkládám jako druhé řešení následující definici funkce:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO K otestování použijte následující kód:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Tento kód na mém počítači skončí za 24 sekund.
Jste na řadě!