Primární a cizí klíče jsou základními charakteristikami relačních databází, jak bylo původně uvedeno v článku E.F. Codda „A Relational Model of Data for Large Shared Data Banks“, publikovaném v roce 1970. Často opakovaný citát zní:„Klíč, celý klíč, a nic než klíč, tak mi pomoz Codde."
Pozadí:Primární klíče
Primární klíč je omezení v SQL Server, které slouží k jedinečné identifikaci každého řádku v tabulce. Klíč může být definován jako jeden sloupec bez NULL nebo jako kombinace sloupců bez NULL, která generuje jedinečnou hodnotu a používá se k vynucení integrity entity pro tabulku. Tabulka může mít pouze jeden primární klíč, a když je pro tabulku definováno omezení primárního klíče, vytvoří se jedinečný index. Tento index bude ve výchozím nastavení klastrovaný index, pokud není specifikován jako neclusterovaný index, když je definováno omezení primárního klíče.
Zvažte Sales.SalesOrderHeader tabulky v AdventureWorks2012 databáze. Tato tabulka obsahuje základní informace o prodejní objednávce, včetně data objednávky a ID zákazníka, a každý prodej je jednoznačně identifikován SalesOrderID , což je primární klíč pro tabulku. Pokaždé, když je do tabulky přidán nový řádek, omezení primárního klíče (s názvem PK_SalesOrderHeader_SalesOrderID ) je zaškrtnuto, aby bylo zajištěno, že již neexistuje žádný řádek se stejnou hodnotou pro SalesOrderID .
Zahraniční klíče
Oddělené od primárních klíčů, ale velmi související, jsou cizí klíče. Cizí klíč je sloupec nebo kombinace sloupců, která je stejná jako primární klíč, ale v jiné tabulce. Cizí klíče se používají k definování vztahu a vynucení integrity mezi dvěma tabulkami.
Chcete-li pokračovat v používání výše uvedeného příkladu, SalesOrderID existuje jako cizí klíč v Sales.SalesOrderDetail tabulka, kde jsou uloženy další informace o prodeji, jako je ID produktu a cena. Když je do SalesOrderHeader přidán nový prodej tabulky, není nutné přidávat řádek pro daný prodej do SalesOrderDetail tabulka Při přidávání řádku do SalesOrderDetail tabulka, odpovídající řádek pro SalesOrderID musí existují v SalesOrderHeader tabulka.
Naopak při mazání dat řádek pro konkrétní SalesOrderID lze kdykoli smazat z SalesOrderDetail tabulky, ale aby byl řádek odstraněn z SalesOrderHeader tabulka, související řádky z SalesOrderDetail bude nutné nejprve smazat.
Na rozdíl od omezení primárního klíče, když je pro tabulku definováno omezení cizího klíče, SQL Server ve výchozím nastavení nevytváří index. Není však neobvyklé, že je vývojáři a správci databází přidávají ručně. Cizí klíč může být součástí složeného primárního klíče pro tabulku, v takovém případě by existoval klastrovaný index s cizím klíčem jako součástí klastrovacího klíče. Alternativně mohou dotazy vyžadovat index, který zahrnuje cizí klíč a jeden nebo více dalších sloupců v tabulce, takže bude vytvořen neshlukovaný index pro podporu těchto dotazů. Indexy cizích klíčů mohou dále poskytovat výhody z hlediska výkonu pro spojení tabulek zahrnující primární a cizí klíč a mohou ovlivnit výkon, když je aktualizována hodnota primárního klíče nebo je-li odstraněn řádek.
V AdventureWorks2012 databáze, existuje jedna tabulka, SalesOrderDetail s SalesOrderID jako cizí klíč. Pro SalesOrderDetail tabulka SalesOrderID a SalesOrderDetailID zkombinovat a vytvořit primární klíč podporovaný seskupeným indexem. Pokud SalesOrderDetail tabulka neměla index na SalesOrderID a poté, když je odstraněn řádek z SalesOrderHeader , SQL Server by musel ověřit, že žádné řádky pro stejné SalesOrderID hodnota existuje. Bez jakýchkoli indexů, které obsahují SalesOrderID SQL Server bude muset provést úplnou kontrolu tabulky SalesOrderDetail . Jak si dokážete představit, čím větší je odkazovaná tabulka, tím déle bude odstranění trvat.
Příklad
Můžeme to vidět v následujícím příkladu, který používá kopie výše uvedených tabulek z AdventureWorks2012 databáze, které byly rozšířeny pomocí skriptu, který naleznete zde. Skript byl vyvinut Jonathanem Kehayiasem (blog | @SQLPoolBoy) a vytváří SalesOrderHeaderEnlarged tabulka s 1 258 600 řádky a SalesOrderDetailEnlarged tabulka s 4 852 680 řádky. Po spuštění skriptu bylo pomocí níže uvedených příkazů přidáno omezení cizího klíče. Všimněte si, že omezení je vytvořeno pomocí ON DELETE CASCADE volba. S touto možností, když je vydána aktualizace nebo odstranění pro SalesOrderHeaderEnlarged tabulka, řádky v odpovídající tabulce (tabulkách) – v tomto případě pouze SalesOrderDetailEnlarged – jsou aktualizovány nebo odstraněny.
Navíc výchozí seskupený index pro SalesOrderDetailEnglarged byl zrušen a znovu vytvořen, aby měl pouze SalesOrderDetailID jako primární klíč, protože představuje typický design.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
S omezením cizího klíče a bez podpůrného indexu bylo vydáno jediné odstranění pro SalesOrderHeaderEnlarged tabulky, což vedlo k odstranění jednoho řádku z SalesOrderHeaderEnlarged a 72 řádků z SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Statistika IO a informace o časování ukazovaly následující:
Čas analýzy a kompilace serveru SQL Server:CPU čas =8 ms, uplynulý čas =8 ms.
Tabulka 'SalesOrderDetailEnlarged'. Počet skenů 1, logické čtení 50647, fyzické čtení 8, čtení napřed 50667, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Worktable'. Počet skenů 2, logické čtení 7, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'SalesOrderHeaderEnlarged'. Počet skenů 0, logické čtení 15, fyzické čtení 14, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Časy spouštění serveru SQL:
Čas CPU =1045 ms, uplynulý čas =1898 ms.
Pomocí SQL Sentry Plan Explorer zobrazuje plán provádění skenování clusterového indexu proti SalesOrderDetailEnlarged protože na SalesOrderID není žádný index :
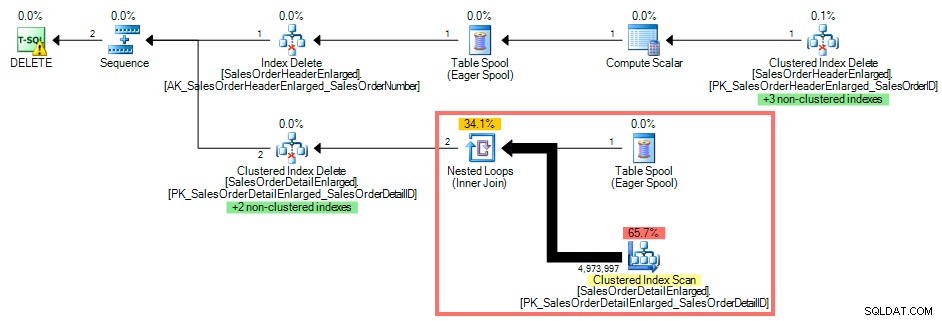
Plán dotazů bez indexu na cizím klíči
Neklastrovaný index pro podporu SalesOrderDetailEnlarged byl poté vytvořen pomocí následujícího příkazu:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Bylo provedeno další odstranění pro SalesOrderID které ovlivnily jeden řádek v SalesOrderHeaderEnlarged a 72 řádků v SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Statistiky IO a informace o načasování ukázaly dramatické zlepšení:
Čas analýzy a kompilace serveru SQL Server:CPU čas =0 ms, uplynulý čas =7 ms.
Tabulka 'SalesOrderDetailEnlarged'. Počet skenů 1, logické čtení 48, fyzické čtení 13, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed čte 0.
Tabulka 'Worktable'. Počet skenů 2, logické čtení 7, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'SalesOrderHeaderEnlarged'. Počet skenů 0, logické čtení 15, fyzické čtení 15, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Časy spouštění serveru SQL:
Čas CPU =0 ms, uplynulý čas =27 ms.
A plán dotazů ukázal hledání indexu neklastrovaného indexu na SalesOrderID , podle očekávání:
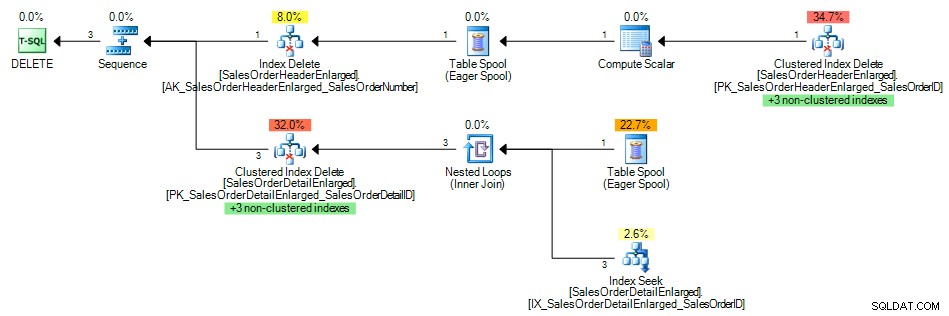
Plán dotazu s indexem na cizím klíči
Doba provádění dotazu klesla z 1898 ms na 27 ms – snížení o 98,58 % a čtení pro SalesOrderDetailEnlarged tabulka klesla z 50 647 na 48 – zlepšení o 99,9 %. Procenta stranou, zvažte pouze I/O generované odstraněním. SalesOrderDetailEnlarged tabulka má v tomto příkladu pouze 500 MB a pro systém s 256 GB dostupné paměti se tabulka zabírající 500 MB ve vyrovnávací paměti nezdá jako hrozná situace. Ale tabulka s 5 miliony řádků je relativně malá; většina velkých systémů OLTP má tabulky se stovkami milionů řádků. Kromě toho není neobvyklé, že pro primární klíč existuje více odkazů na cizí klíč, kde odstranění primárního klíče vyžaduje odstranění z více souvisejících tabulek. V takovém případě je možné vidět prodloužené doby smazání, což není pouze problém s výkonem, ale také problém s blokováním, v závislosti na úrovni izolace.
Závěr
Obecně se doporučuje vytvořit index, který vede na sloupec(e) cizího klíče, aby podporoval nejen spojení primárního a cizího klíče, ale také aktualizace a mazání. Všimněte si, že se jedná o obecné doporučení, protože existují scénáře okrajových případů, kdy další index na cizím klíči nebyl použit kvůli extrémně malé velikosti tabulky a dodatečné aktualizace indexu ve skutečnosti negativně ovlivnily výkon. Stejně jako u všech úprav schématu by se přidání indexu mělo po implementaci testovat a monitorovat. Je důležité zajistit, aby další indexy produkovaly požadované účinky a neovlivňovaly negativně výkon řešení. Za zmínku také stojí, kolik dalšího místa vyžadují indexy pro cizí klíče. To je nezbytné zvážit před vytvořením indexů, a pokud přinesou přínos, je třeba to vzít v úvahu při budoucím plánování kapacity.