
Příliš často vidím lidi, kteří si stěžují na to, jak jejich protokol transakcí zabral jejich pevný disk. Mnohokrát se ukázalo, že prováděli velkou operaci odstranění, jako je čištění nebo archivace dat, v jedné velké transakci.
Chtěl jsem provést několik testů, abych ukázal dopad provádění stejné operace s daty v blocích oproti jedné transakci na dobu trvání i protokol transakcí. Vytvořil jsem databázi a naplnil ji velkou tabulkou SalesOrderDetailEnlarged ,
Po naplnění tabulky jsem zazálohoval databázi, zazálohoval protokol a spustil DBCC SHRINKFILE (nestřílejte do mě), aby dopad na soubor protokolu mohl být stanoven od základní linie (s vědomím, že tyto operace *způsobí* nárůst protokolu transakcí).
Záměrně jsem použil mechanický disk na rozdíl od SSD. I když můžeme začít vidět populárnější trend přechodu na SSD, zatím se tak nestalo v dostatečně velkém měřítku; v mnoha případech je to stále příliš nákladné, aby to bylo možné ve velkých úložných zařízeních.
Testy
Dále jsem si musel určit, co chci otestovat pro největší dopad. Vzhledem k tomu, že jsem se právě včera účastnil diskuse se spolupracovníkem o mazání dat po částech, zvolil jsem mazání. A protože seskupený index v této tabulce je na SalesOrderID , to jsem použít nechtěl – to by bylo příliš snadné (a velmi zřídka by se to shodovalo se způsobem, jakým se s mazáním pracuje v reálném životě). Tak jsem se rozhodl místo toho jít po sérii ProductID hodnoty, což by zajistilo, že bych zasáhl velké množství stránek a vyžadoval by to hodně protokolování. Podle následujícího dotazu jsem určil, které produkty smazat:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
To přineslo následující výsledky:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Tím by se smazalo 456 960 řádků (asi 10 % tabulky), rozmístěných v mnoha objednávkách. Toto není v tomto kontextu realistická úprava, protože to bude mít problémy s předem vypočítanými součty objednávek a nemůžete skutečně odebrat produkt z objednávky, která již byla odeslána. Ale pomocí databáze, kterou všichni známe a milujeme, je to analogické řekněme smazání uživatele z webu fóra a také smazání všech jeho zpráv – skutečný scénář, který jsem viděl v divočině.
Jedním testem by tedy bylo provést následující, jednorázové odstranění:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Vím, že to bude vyžadovat masivní skenování a vyžádá si obrovskou daň v protokolu transakcí. To je tak trochu pointa. :-)
Zatímco to běželo, dal jsem dohromady jiný skript, který toto odstranění provede po částech:25 000, 50 000, 75 000 a 100 000 řádků najednou. Každý blok bude potvrzen ve své vlastní transakci (takže pokud potřebujete zastavit skript, můžete, a všechny předchozí bloky již budou potvrzeny, místo toho, abyste museli začínat znovu), a v závislosti na modelu obnovy budou následovány buď pomocí CHECKPOINT nebo BACKUP LOG minimalizovat průběžný dopad na protokol transakcí. (Budu také testovat bez těchto operací.) Bude to vypadat nějak takto (Nebudu se v tomto testu obtěžovat se zpracováním chyb a dalšími vychytávkami, ale neměli byste být přehnaní):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Samozřejmě po každém testu bych obnovil původní zálohu databáze WITH REPLACE, RECOVERY , nastavte odpovídajícím způsobem model obnovy a spusťte další test.
Výsledky
Výsledek prvního testu nebyl vůbec překvapivý. Provedení odstranění v jediném příkazu trvalo 42 sekund v plném rozsahu a 43 sekund v jednoduchém. V obou případech se záznam zvětšil na 579 MB.
Další sada testů pro mě měla několik překvapení. Jedním z nich je, že i když tyto metody rozdělování výrazně snížily dopad na soubor protokolu, pouze několik kombinací se přiblížilo trváním a žádná nebyla ve skutečnosti rychlejší. Další je, že obecně se chunkování při plné obnově (bez provedení zálohy protokolu mezi kroky) projevilo lépe než ekvivalentní operace při jednoduché obnově. Zde jsou výsledky pro trvání a dopad protokolu:
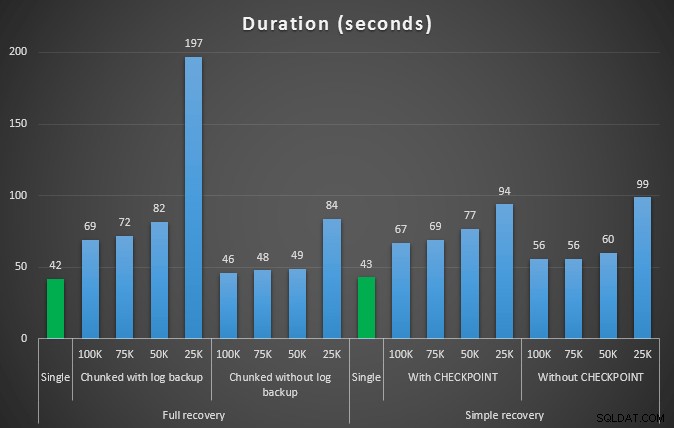
Trvání v sekundách různých operací odstranění, které odstraní 457 tisíc řádků
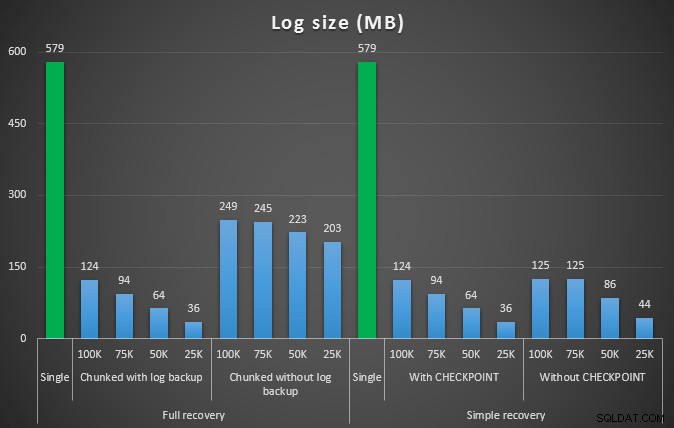
Velikost protokolu v MB, po různých operacích odstranění bylo odebráno 457 tisíc řádků
Obecně platí, že zatímco se velikost protokolu výrazně sníží, doba trvání se prodlouží. Tento typ měřítka můžete použít k určení, zda je důležitější snížit dopad na místo na disku nebo minimalizovat množství stráveného času. Při malém zásahu v trvání (a koneckonců většina těchto procesů běží na pozadí) můžete výrazně ušetřit (v těchto testech až 94 %) na využití prostoru pro protokoly.
Všimněte si, že jsem žádný z těchto testů nezkoušel s povolenou kompresí (možná budoucí test!) a nechal jsem nastavení automatického růstu logu na hrozných výchozích hodnotách (10 %) – částečně z lenosti a částečně proto, že mnoho prostředí venku si zachovalo tohle hrozné nastavení.
Co když mám více dat?
Dále mě napadlo, že bych to měl otestovat na trochu větší databázi. Vytvořil jsem tedy další databázi a vytvořil novou, větší kopii dbo.SalesOrderDetailEnlarged . Ve skutečnosti asi desetkrát větší. Tentokrát místo primárního klíče na SalesOrderID, SalesorderDetailID , právě jsem z něj udělal seskupený index (aby bylo možné vytvářet duplikáty) a naplnil jsem jej tímto způsobem:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Kvůli omezením místa na disku jsem pro tento test musel odejít z virtuálního počítače svého notebooku (a zvolil jsem 40jádrový box se 128 GB RAM, který náhodou seděl téměř nečinně :-)), a přesto v žádném případě to nebyl rychlý proces. Naplnění tabulky a vytvoření indexů trvalo ~24 minut.
Tabulka má 48,5 milionu řádků a zabírá 7,9 GB na disku (4,9 GB na data a 2,9 GB na index).
Tentokrát můj dotaz na určení vhodné sady kandidátů ProductID hodnoty k odstranění:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Přinesly následující výsledky:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Takže smažeme 4 455 360 řádků, něco málo pod 10 % tabulky. Podle podobného vzoru jako ve výše uvedeném testu vymažeme vše najednou, poté po částech po 500 000, 250 000 a 100 000 řádcích.
Výsledky:
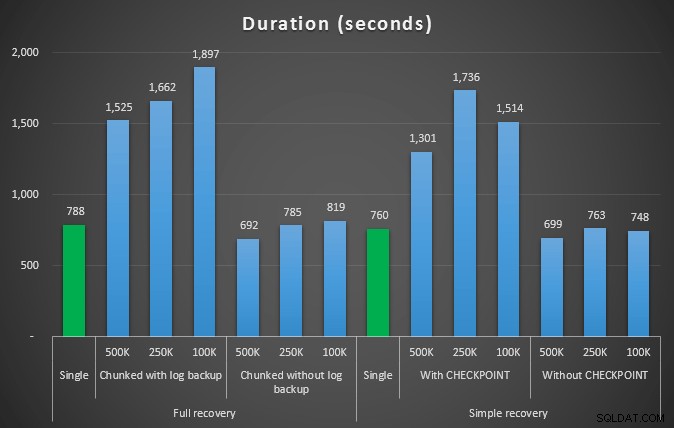 Doba trvání různých operací odstranění, které odstraní 4,5 MM řádky, v sekundách
Doba trvání různých operací odstranění, které odstraní 4,5 MM řádky, v sekundách
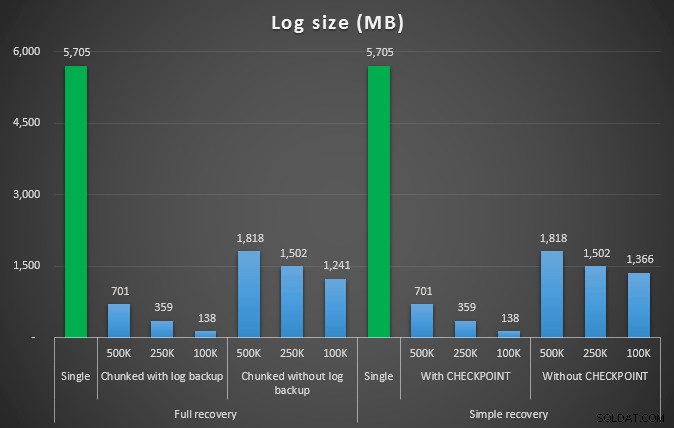 Velikost protokolu v MB, po různých operacích odstranění se odstraní 4,5MM řádky
Velikost protokolu v MB, po různých operacích odstranění se odstraní 4,5MM řádky
Znovu tedy vidíme výrazné snížení velikosti souboru protokolu (přes 97 % v případech s nejmenší velikostí bloku 100 kB); v tomto měřítku však vidíme několik případů, kdy také provedeme odstranění v kratším čase, dokonce i se všemi událostmi autogrow, které musely nastat. To mi zní strašně jako win-win!
Tentokrát s větším logem
Teď jsem byl zvědavý, jak by se tato různá smazání mohla srovnávat se souborem protokolu, který je předem dimenzován pro tak velké operace. Zůstal jsem u naší větší databáze, předem jsem rozbalil soubor protokolu na 6 GB, zazálohoval jej a poté znovu provedl testy:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Výsledky porovnání doby trvání s pevným souborem protokolu s případem, kdy soubor musel nepřetržitě automaticky růst:
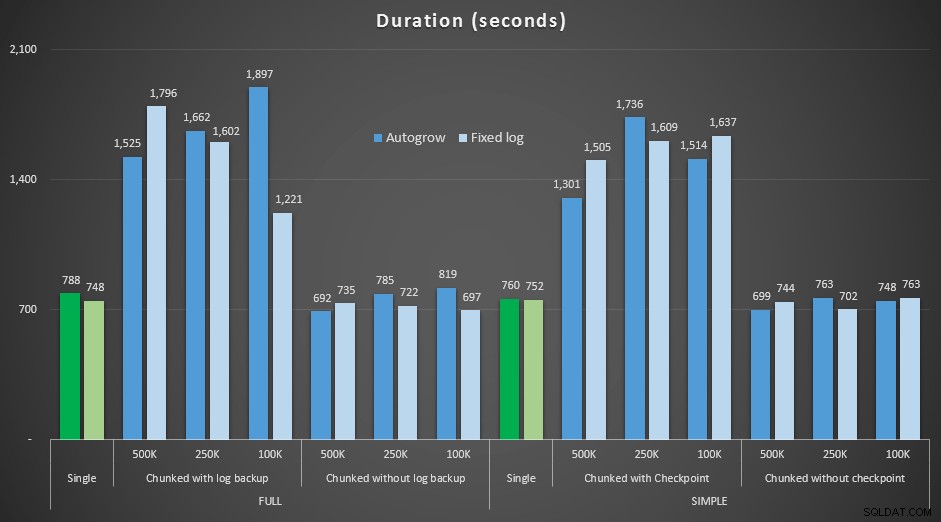
Doba trvání různých operací odstranění v sekundách a odstranění 4,5 MM řádků , porovnávající pevnou velikost logu a autogrow
Opět vidíme, že metody, které se rozdělují do dávek a *neprovádějí* zálohu protokolu nebo kontrolní bod po každém kroku, konkurují ekvivalentní jediné operaci, pokud jde o trvání. Ve skutečnosti uvidíte, že většina skutečně funguje za kratší celkový čas, s přidaným bonusem, že ostatní transakce se budou moci dostat dovnitř a ven mezi kroky. Což je dobrá věc, pokud nechcete, aby tato operace odstranění zablokovala všechny nesouvisející transakce.
Závěr
Je jasné, že na tento problém neexistuje jediná správná odpověď – existuje mnoho inherentních proměnných „záleží“. Nalezení magického čísla může vyžadovat určité experimentování, protože bude existovat rovnováha mezi režií potřebnou k zálohování protokolu a množstvím práce a času, které ušetříte při různých velikostech bloků. Pokud však plánujete smazat nebo archivovat velké množství řádků, je docela pravděpodobné, že na tom budete celkově lépe, když provedete změny po částech, spíše než v jedné masivní transakci – i když se zdá, že čísla trvání že méně atraktivní operace. Nejde jen o dobu trvání – pokud nemáte dostatečně předem alokovaný soubor protokolu a nemáte prostor pro tak masivní transakci, je pravděpodobně mnohem lepší minimalizovat nárůst souboru protokolu za cenu trvání, v takovém případě budete chtít ignorovat výše uvedené grafy trvání a věnovat pozornost grafům velikosti protokolu.
Pokud si můžete dovolit prostor, stále můžete nebo nemusíte chtít předběžně nastavit velikost protokolu transakcí. V závislosti na scénáři někdy použití výchozího nastavení automatického růstu skončilo v mých testech o něco rychleji než použití pevného souboru protokolu se spoustou místa. Navíc může být těžké přesně odhadnout, kolik budete potřebovat, abyste se mohli ubytovat u velké transakce, kterou jste ještě neprovedli. Pokud nemůžete otestovat realistický scénář, pokuste se co nejlépe představit nejhorší scénář – pak jej pro jistotu zdvojnásobte. Kimberly Tripp (blog | @KimberlyLTripp) má v tomto příspěvku několik skvělých rad:8 kroků k lepší propustnosti protokolu transakcí – v této souvislosti se konkrétně podívejte na bod #6. Bez ohledu na to, jak se rozhodnete vypočítat požadavky na prostor pro protokoly, pokud budete nakonec prostor přesto potřebovat, je lepší ho vzít kontrolovaným způsobem s dostatečným předstihem, než zastavovat své obchodní procesy, zatímco čekají na autogrow ( nevadí více!).
Dalším velmi důležitým aspektem, který jsem neměřil explicitně, je dopad na souběžnost – řada kratších transakcí bude mít teoreticky menší dopad na souběžné operace. I když jedno odstranění trvalo o něco méně času než delší dávkové operace, po celou dobu trvání drželo všechny své zámky, zatímco operace po částech by umožnily, aby se mezi každou transakci vkradly další transakce ve frontě. V budoucím příspěvku se pokusím blíže podívat na tento dopad (a mám také plány na další hlubší analýzu).