Úvod
Od jejich zavedení v SQL Server 2005 funguje okno jako ROW_NUMBER a RANK se ukázaly jako extrémně užitečné při řešení široké škály běžných problémů T-SQL. Ve snaze zobecnit taková řešení se návrháři databází často snaží začlenit je do pohledů, aby podpořili zapouzdření a opětovné použití kódu. Bohužel omezení v optimalizátoru dotazů SQL Server často znamená, že pohledy obsahující funkce okna nefungují tak dobře, jak se očekávalo. Tento příspěvek pracuje s názorným příkladem problému, podrobně popisuje důvody a poskytuje řadu řešení.
Tento problém se také může vyskytnout v odvozených tabulkách, běžných tabulkových výrazech a in-line funkcích, ale nejčastěji to vidím u pohledů, protože jsou záměrně psány tak, aby byly obecnější.
Funkce okna
Funkce okna se vyznačují přítomností OVER() klauzule a existují ve třech variantách:
- Funkce okna hodnocení
ROW_NUMBERRANKDENSE_RANKNTILE
- Agregovat funkce okna
MIN,MAX,AVG,SUMCOUNT,COUNT_BIGCHECKSUM_AGGSTDEV,STDEVP,VAR,VARP
- Funkce analytického okna
LAG,LEADFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
Funkce hodnocení a agregace oken byly zavedeny v SQL Server 2005 a značně rozšířeny v SQL Server 2012. Funkce analytických oken jsou pro SQL Server 2012 novinkou.
Všechny funkce okna uvedené výše podléhají omezením optimalizátoru podrobně popsaným v tomto článku.
Příklad
Pomocí vzorové databáze AdventureWorks je úkolem napsat dotaz, který vrátí všechny transakce produktu #878, ke kterým došlo k poslednímu dostupnému datu. Existuje mnoho způsobů, jak vyjádřit tento požadavek v T-SQL, ale my se rozhodneme napsat dotaz, který používá funkci okna. Prvním krokem je najít záznamy transakcí pro produkt #878 a seřadit je sestupně podle data:
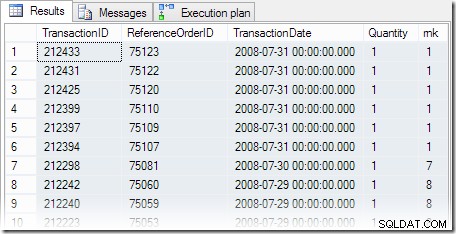
SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC)FROM Production.TransactionHistory AS thWHERE th.78ProductIDORDER =8 před>
Výsledky dotazu jsou podle očekávání, přičemž k poslednímu dostupnému datu došlo k šesti transakcím. Prováděcí plán obsahuje výstražný trojúhelník, který nás upozorňuje na chybějící index:
Jako obvykle u chybějících návrhů indexů si musíme pamatovat, že doporučení není výsledkem důkladné analýzy dotazu – je to spíše náznak toho, že musíme trochu přemýšlet o tom, jak tento dotaz přistupuje k potřebným datům.
Navrhovaný index by byl jistě efektivnější než úplné skenování tabulky, protože by umožnil indexové vyhledávání konkrétního produktu, o který se zajímáme. Index by také pokryl všechny potřebné sloupce, ale nevyhnul by se řazení (podle
TransactionDateklesající). Ideální index pro tento dotaz by umožňoval hledáníProductID, vrátí vybrané záznamy obráceněTransactionDatepořadí a pokrýt ostatní vrácené sloupce:VYTVOŘTE NENCLUSTEROVANÝ INDEX ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, Quantity);S tímto indexem je plán provádění mnohem efektivnější. Prohledávání clusteru indexu bylo nahrazeno hledáním rozsahu a explicitní řazení již není nutné:
Posledním krokem pro tento dotaz je omezit výsledky pouze na ty řádky, které jsou na prvním místě. Nemůžeme filtrovat přímo v
WHEREklauzule našeho dotazu, protože funkce okna se mohou objevit pouze vSELECTaORDER BYklauzule.Toto omezení můžeme obejít pomocí odvozené tabulky, běžného tabulkového výrazu, funkce nebo pohledu. Při této příležitosti použijeme běžný tabulkový výraz (alias in-line view):
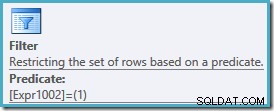
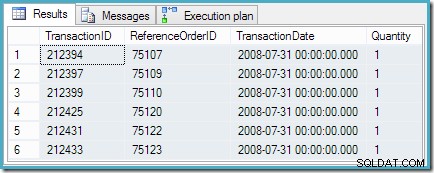
WITH RankedTransactions AS( SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Qantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC) FROM Production.TransactionWHistory AS THISTORY )SELECT TransactionID, ReferenceOrderID, TransactionDate, QuantityFROM RankedTransactionsWHERE rnk =1;Plán provádění je stejný jako dříve, s dalším filtrem, který vrátí pouze řádky s hodnocením #1:
Dotaz vrátí šest stejně hodnocených řádků, které očekáváme:
Zobecnění dotazu
Ukazuje se, že náš dotaz je velmi užitečný, takže se rozhodneme jej zobecnit a uložit definici do pohledu. Aby to fungovalo pro jakýkoli produkt, musíme udělat dvě věci:vrátit
ProductIDz pohledu a rozdělit funkci hodnocení podle produktu:CREATE VIEW dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( SELECT th.QTransactionID,ID,ID,ID rnk =RANK() OVER ( ROZDĚLENÍ PODLE TH.ProductID ORDER BY th.TransactionDate DESC) Z Production.TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;Výběr všech řádků z pohledu má za následek následující plán provádění a správné výsledky:
Nyní můžeme najít nejnovější transakce pro produkt 878 pomocí mnohem jednoduššího dotazu na zobrazení:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;Očekáváme, že plán provádění tohoto nového dotazu bude přesně stejný jako před vytvořením pohledu. Optimalizátor dotazů by měl být schopen vložit filtr určený v
WHEREklauzule dolů do pohledu, což vede k hledání indexu.V tuto chvíli se však musíme zastavit a trochu se zamyslet. Optimalizátor dotazů může vytvářet pouze plány provádění, které zaručují stejné výsledky jako specifikace logického dotazu – je bezpečné poslat naše
WHEREklauzule do zobrazení?PARTITION BY klauzule funkce okna v pohledu. Důvodem je, že odstranění úplných skupin (oddílů) z funkce okna neovlivní pořadí řádků vrácených dotazem. Otázkou je, ví to optimalizátor dotazů SQL Server? Odpověď závisí na tom, jakou verzi SQL Server používáme. Plán provádění SQL Server 2005
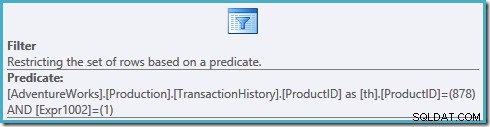
Pohled na vlastnosti filtru v tomto plánu ukazuje, že používá dva predikáty:
ProductID = 878predikát nebyl posunut dolů do zobrazení, což má za následek plán, který prohledá náš index a seřadí každý řádek v tabulce před filtrováním podle produktu #878 a řádků s hodnocením #1.Optimalizátor dotazů SQL Server 2005 nemůže vložit vhodné predikáty za funkci okna v nižším rozsahu dotazu (zobrazení, běžný tabulkový výraz, vložená funkce nebo odvozená tabulka). Toto omezení platí pro všechna sestavení SQL Server 2005.
Plán provádění SQL Server 2008+
Toto je plán provádění pro stejný dotaz na serveru SQL Server 2008 nebo novějším:
ProductIDpredikát byl úspěšně protlačen přes operátory hodnocení a nahradil skenování indexu efektivním hledáním indexu.Optimalizátor dotazů z roku 2008 obsahuje nové pravidlo zjednodušení
SelOnSeqPrj(vyberte na sekvenčním projektu), který je schopen posouvat bezpečné predikáty vnějšího rozsahu minulé funkce okna. Abychom vytvořili méně efektivní plán pro tento dotaz v SQL Server 2008 nebo novějším, musíme dočasně zakázat tuto funkci optimalizace dotazů:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878OPTIONj
Bohužel
SelOnSeqPrjpravidlo zjednodušení funguje pouze když predikát provede srovnání s konstantou . Z tohoto důvodu následující dotaz vytváří suboptimální plán na SQL Server 2008 a novějších:DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;
Problém může nastat i tam, kde predikát používá konstantní hodnotu. SQL Server se může rozhodnout automaticky parametrizovat triviální dotazy (takové, pro které existuje zjevně nejlepší plán). Pokud je automatická parametrizace úspěšná, optimalizátor uvidí parametr namísto konstanty a
SelOnSeqPrjpravidlo se nepoužije.U dotazů, u kterých nedochází k pokusu o automatickou parametrizaci (nebo kde je zjištěno, že není bezpečná), může optimalizace přesto selhat, pokud je zvolena možnost databáze pro
FORCED PARAMETERIZATIONje zapnuto. Náš testovací dotaz (s konstantní hodnotou 878) není bezpečný pro automatickou parametrizaci, ale nastavení vynucené parametrizace to přepíše, což má za následek neefektivní plán:ALTER DATABASE AdventureWorksSET PARAMETERIZATION FORCED;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.Most.MostRecentTransactionsPer WATABHEPARASED Adventures.>
Řešení SQL Server 2008+
Aby mohl optimalizátor ‚vidět‘ konstantní hodnotu pro dotaz, který odkazuje na lokální proměnnou nebo parametr, můžeme přidat
OPTION (RECOMPILE)nápověda k dotazu:DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductIDOPTION (RECOMPILE);RECOMPILE);Poznámka: Plán provádění před spuštěním („odhadovaný“) stále zobrazuje skenování indexu, protože hodnota proměnné ještě není ve skutečnosti nastavena. Když je dotaz proveden plán provádění však ukazuje požadovaný plán hledání indexu:
SelOnSeqPrjpravidlo v SQL Server 2005 neexistuje, takžeOPTION (RECOMPILE)tam pomoci nelze. V případě, že vás to zajímá,OPTION (RECOMPILE)Toto řešení vede k hledání, i když je zapnutá možnost databáze pro vynucenou parametrizaci.Všechny verze řešení č. 1
V některých případech je možné nahradit problematické zobrazení, běžný tabulkový výraz nebo odvozenou tabulku parametrizovanou funkcí s hodnotou tabulky v řádcích:
CREATE FUNCTION dbo.MostRecentTransactionsForProduct( @ProductID integer) RETURN TABLEWITH SCHEMABINDING ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.Transaction.QuctionDate, sq.IDth FTransactionDate, sq. ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() NAD ( ROZDĚLENÍ PODLE TH.ProductID ORDER BY th.TransactionDate DESC) Z Production.TransactionHistory AS th KDE th.ProductID =@ProductID =@ProductID WHErn.k.k sq 1;Tato funkce explicitně umístí
ProductIDpredikát ve stejném rozsahu jako funkce okna, čímž se vyhnete omezení optimalizátoru. Náš příklad dotazu, který byl napsán pro použití funkce in-line, zní:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;To vytvoří požadovaný plán hledání indexu ve všech verzích SQL Server, které podporují funkce okna. Toto zástupné řešení vytváří hledání, i když predikát odkazuje na parametr nebo místní proměnnou –
OPTION (RECOMPILE)není vyžadováno.PARTITION BY klauzule a již nebude vracet ProductIDsloupec. Ponechal jsem definici stejnou jako pohled, který nahradila, abych jasněji ilustroval příčinu rozdílů v prováděcím plánu.Všechny verze řešení č. 2
Druhé řešení se vztahuje pouze na funkce okna hodnocení, které jsou filtrovány tak, aby vracely řádky očíslované nebo označené jako #1 (pomocí
ROW_NUMBER,RANKneboDENSE_RANK). Toto je však velmi běžné použití, takže stojí za zmínku.Další výhodou je, že toto řešení může vytvářet plány, které jsou ještě efektivnější než dříve zobrazené plány indexového vyhledávání. Pro připomenutí, předchozí nejlepší plán vypadal takto:
Tento plán provádění má hodnotu 1 918 řádků, i když nakonec vrátí pouze 6 . Tento plán provádění můžeme zlepšit použitím funkce okna v
ORDER BYklauzule namísto klasifikace řádků a následné filtrování podle pořadí #1:VYBERTE VRCHOL (1) S VAZBAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY RANK() OVER ( ORDERSCaDaDth.TransCaction BYTH. /před>
Tento dotaz pěkně ilustruje použití funkce okna v
ORDER BYklauzule, ale můžeme to udělat ještě lépe, úplně odstranit funkci okna:VYBERTE NEJLEPŠÍ (1) S VAZBAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY th.TransactionDate DESC;
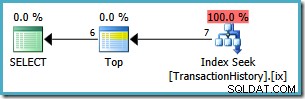
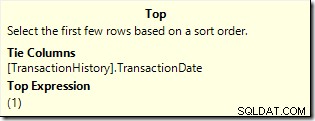
Tento plán čte pouze 7 řádků z tabulky, aby vrátil stejnou 6řádkovou sadu výsledků. Proč 7 řádků? Operátor Top běží v
WITH TIESrežim:
Pokračuje v požadavku na jeden řádek ze svého podstromu, dokud se nezmění TransactionDate. Sedmý řádek je nutný, aby měl Top jistotu, že se již nebudou kvalifikovat žádné další řádky se shodnou hodnotou.
Můžeme rozšířit logiku výše uvedeného dotazu a nahradit definici problematického pohledu:
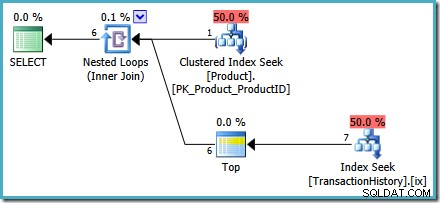
ALTER VIEW dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT p.ProductID, Ranked1.TransactionID, Ranked1.ReferenceOrderID, Ranked1.TransactionDate, Ranked1.QuantityFROM -- Seznam ID produktů FROMAPPLY PRODUKT (SELECT. ProductID) Návrat Výsledky č. 1 pro každé ID produktu VYBERTE TOP (1) S VAZBAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity FROM Production.TransactionHistory AS th WHERE th.ProductID =p.ProductID ORDER BY TH.DESC)TransactionDate AS Ranked1;Zobrazení nyní používá
CROSS APPLYzkombinovat výsledky našeho optimalizovanéhoORDER BYdotaz na každý produkt. Náš testovací dotaz se nezměnil:DECLARE @ProductID integer;SET @ProductID =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;Plány před spuštěním i po spuštění zobrazují hledání indexu bez potřeby
OPTION (RECOMPILE)nápověda k dotazu. Následuje plán po provedení (‚skutečný‘):
Pokud by zobrazení použilo
ROW_NUMBERmístoRANK, nahrazující pohled by jednoduše vynechalWITH TIESklauzule naTOP (1). Nový pohled lze samozřejmě také zapsat jako parametrizovanou funkci s hodnotou v řádkové tabulce.Dalo by se namítnout, že původní plán hledání indexu s
rnk = 1predikát lze také optimalizovat tak, aby testoval pouze 7 řádků. Koneckonců, optimalizátor by měl vědět, že hodnocení vytváří operátor Sequence Project v přísném vzestupném pořadí, takže provádění může skončit, jakmile je vidět řádek s hodnocením vyšším než jedna. Optimalizátor však dnes tuto logiku neobsahuje.Poslední myšlenky
Lidé jsou často zklamáni výkonem pohledů, které obsahují funkce oken. Důvod lze často vysledovat zpět k omezení optimalizátoru popsanému v tomto příspěvku (nebo možná proto, že návrhář pohledu si neuvědomil, že predikáty použité na pohled se musí objevit v
PARTITION BYklauzule bezpečně stlačena dolů).Chci zdůraznit, že toto omezení se nevztahuje pouze na zobrazení a není omezeno ani na
ROW_NUMBER,RANKaDENSE_RANK. Při použití jakékoli funkce sOVERbyste si měli být vědomi tohoto omezení klauzuli v pohledu, běžném tabulkovém výrazu, odvozené tabulce nebo funkci s hodnotou v řádkové tabulce.Uživatelé SQL Server 2005, kteří se setkají s tímto problémem, stojí před volbou přepsat zobrazení jako parametrizovanou funkci s hodnotou v řádkové tabulce nebo pomocí
APPLYtechnika (pokud je to možné).Uživatelé SQL Server 2008 mají další možnost použití
OPTION (RECOMPILE)dotaz nápověda, zda lze problém vyřešit tím, že optimalizátoru umožníte vidět konstantu namísto odkazu na proměnnou nebo parametr. Při použití této rady však nezapomeňte zkontrolovat plány po provedení:plán před provedením obecně nemůže ukázat optimální plán.