Tento článek je třetí ze série o prahových hodnotách optimalizace pro seskupování a agregaci dat. V části 1 jsem pokryl předobjednaný algoritmus Stream Aggregate. V části 2 jsem pokryl nepředobjednaný algoritmus Sort + Stream Aggregate. V této části se zabývám algoritmem Hash Match (Aggregate), který budu označovat jednoduše jako Hash Aggregate. Poskytuji také shrnutí a srovnání mezi algoritmy, kterými se zabývám v části 1, části 2 a části 3.
Použiji stejnou ukázkovou databázi s názvem PerformanceV3, kterou jsem použil v předchozích článcích série. Jen se ujistěte, že před spuštěním příkladů v článku nejprve spustíte následující kód, abyste odstranili několik nepotřebných indexů:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Jediné dva indexy, které by v této tabulce měly zůstat, jsou idx_cl_od (seskupený s datem objednávky jako klíčem) a PK_Orders (nesdružený s orderid jako klíčem).
Hash Aggregate
Algoritmus Hash Aggregate organizuje skupiny do hashovací tabulky na základě nějaké interně zvolené hashovací funkce. Na rozdíl od algoritmu Stream Aggregate nemusí spotřebovávat řádky ve skupinovém pořadí. Zvažte následující dotaz (budeme ho nazývat Dotaz 1) jako příklad (vynucení agregace hash a sériového plánu):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Obrázek 1 ukazuje plán pro Dotaz 1.
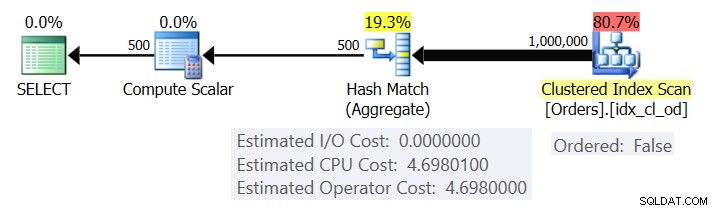
Obrázek 1:Plán pro dotaz 1
Plán skenuje řádky z seskupeného indexu pomocí vlastnosti Ordered:False (skenování není nutné k dodání řádků uspořádaných podle klíče indexu). Optimalizátor obvykle upřednostňuje skenování nejužšího krycího indexu, což je v našem případě seskupený index. Plán vytvoří hašovací tabulku se seskupenými sloupci a agregacemi. Náš dotaz vyžaduje agregaci COUNT typu INT. Plán to ve skutečnosti vypočítá jako hodnotu typu BIGINT, tedy operátor Compute Scalar, který aplikuje implicitní převod na INT.
Microsoft veřejně nesdílí hashovací algoritmy, které používá. Jedná se o velmi proprietární technologii. Abychom tento koncept ilustrovali, předpokládejme, že SQL Server používá pro náš dotaz výše hashovací funkci % 250 (modulo 250). Před zpracováním jakýchkoli řádků má naše hašovací tabulka 250 segmentů představujících 250 možných výsledků hašovací funkce (0 až 249). Jak SQL Server zpracovává každý řádek, aplikuje hashovací funkci
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
Obrázek 2 ukazuje tři stavy hašovací tabulky:před zpracováním jakýchkoli řádků, po zpracování prvních 5 řádků a po zpracování prvních 10 řádků. Každá položka v propojeném seznamu obsahuje n-tici (empid, COUNT(*)).
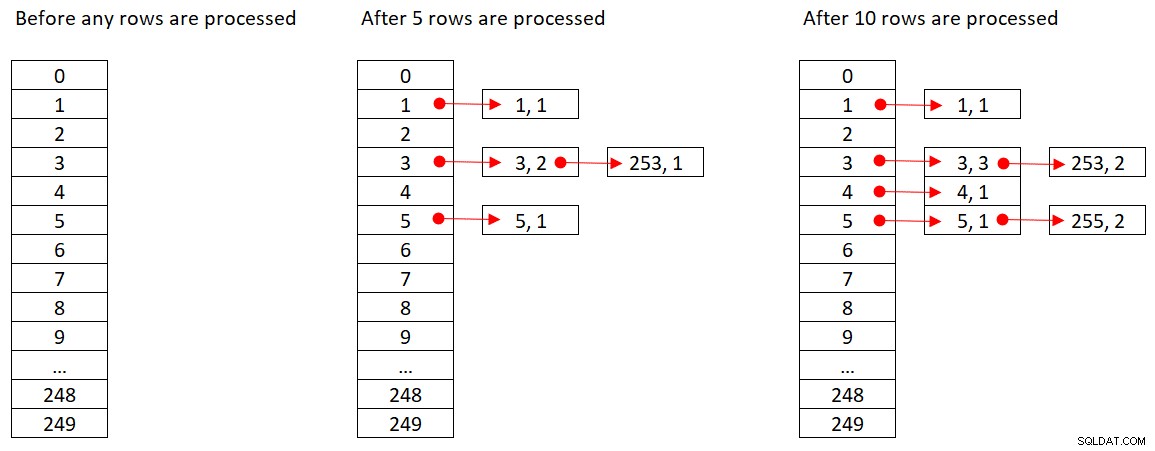
Obrázek 2:Stavy hashovací tabulky
Jakmile operátor hash Aggregate dokončí spotřebu všech vstupních řádků, hash tabulka bude mít všechny skupiny s konečným stavem agregace.
Stejně jako operátor Sort vyžaduje operátor Hash Aggregate přidělení paměti, a pokud mu dojde paměť, musí se přelít do tempdb; zatímco řazení vyžaduje přidělení paměti, které je úměrné počtu řádků, které mají být seřazeny, hašování vyžaduje přidělení paměti, které je úměrné počtu skupin. Takže zvláště když má seskupovací sada vysokou hustotu (malý počet skupin), tento algoritmus vyžaduje podstatně méně paměti, než když je vyžadováno explicitní třídění.
Zvažte následující dva dotazy (nazývejte je Dotaz 1 a Dotaz 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Obrázek 3 porovnává přidělení paměti pro tyto dotazy.

Obrázek 3:Plány pro Dotaz 1 a Dotaz 2
Všimněte si velkého rozdílu mezi přidělením paměti v těchto dvou případech.
Pokud jde o náklady operátora Hash Aggregate, vraťme se k obrázku 1, všimněte si, že neexistují žádné I/O náklady, ale pouze náklady na CPU. Dále se pokuste zpětně analyzovat vzorec výpočtu nákladů na CPU pomocí podobných technik, jaké jsem popsal v předchozích dílech série. Faktory, které mohou potenciálně ovlivnit náklady operátora, jsou počet vstupních řádků, počet výstupních skupin, použitá agregační funkce a to, podle čeho seskupujete (kardinalita seskupovací sady, použité datové typy).
Očekávali byste, že tento operátor bude mít počáteční náklady na přípravu na vytvoření hashovací tabulky. Také byste očekávali, že se bude škálovat lineárně s ohledem na počet řádků a skupin. To je skutečně to, co jsem našel. I když však náklady operátorů Stream Aggregate a Sort nejsou ovlivněny tím, podle čeho seskupujete, zdá se, že náklady operátora Hash Aggregate jsou – jak z hlediska mohutnosti sady seskupení, tak použitých datových typů.
Chcete-li pozorovat, že mohutnost skupiny seskupení ovlivňuje náklady operátora, zkontrolujte náklady na CPU operátorů Hash Aggregate v plánech pro následující dotazy (nazývejte je Dotaz 3 a Dotaz 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Samozřejmě se chcete ujistit, že odhadovaný počet vstupních řádků a výstupních skupin je v obou případech stejný. Odhadované plány pro tyto dotazy jsou zobrazeny na obrázku 4.
Obrázek 4:Plány pro Dotaz 3 a Dotaz 4
Jak vidíte, náklady na CPU operátoru Hash Aggregate jsou 0,16903 při seskupování podle jednoho celočíselného sloupce a 0,174016 při seskupování podle dvou celých sloupců, přičemž všechny ostatní jsou stejné. To znamená, že mohutnost seskupení skutečně ovlivňuje náklady.
Pokud jde o to, zda datový typ seskupeného prvku ovlivňuje cenu, použil jsem ke kontrole následující dotazy (nazývejte je Dotaz 5, Dotaz 6 a Dotaz 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Plány pro všechny tři dotazy mají stejný odhadovaný počet vstupních řádků a výstupních skupin, přesto mají všechny různé odhadované náklady na CPU (0,121766, 0,16903 a 0,171716), a proto použitý datový typ ovlivňuje náklady.
Zdá se, že typ agregační funkce má také vliv na náklady. Zvažte například následující dva dotazy (nazývejte je Dotaz 8 a Dotaz 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Odhadovaná cena CPU pro Hash Aggregate v plánu pro Query 8 je 0,166344 a v Query 9 je 0,16903.
Mohlo by to být zajímavé cvičení pokusit se přesně zjistit, jakým způsobem mohutnost skupiny seskupení, datové typy a použitá agregační funkce ovlivňují náklady; Jen jsem nesledoval tento aspekt nákladů. Po výběru sady seskupení a agregační funkce pro váš dotaz tedy můžete provést zpětnou analýzu kalkulačního vzorce. Pojďme například zpětně analyzovat vzorec výpočtu nákladů na CPU pro operátor Hash Aggregate při seskupování podle jednoho sloupce celého čísla a vrácení agregace MAX (datum objednávky). Vzorec by měl být:
Náklady na procesor operátora =Pomocí technik, které jsem demonstroval v předchozích článcích série, jsem získal následující reverzní inženýrství:
Náklady na procesor operátora =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Přesnost vzorce můžete zkontrolovat pomocí následujících dotazů:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Mám následující výsledky:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412Pre> PRES
Zdá se, že vzorec je na místě.
Přehled a srovnání nákladů
Nyní máme kalkulační vzorce pro tři dostupné strategie:předobjednaný Stream Aggregate, Sort + Stream Aggregate a Hash Aggregate. Následující tabulka shrnuje a porovnává nákladové charakteristiky těchto tří algoritmů:
| Předobjednaný agregát streamu | Řadit + Agregát streamování | Hash Aggregate | |
| Vzorec | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Malý počet řádků: 9,99127891201865E-05 + @číslo * LOG(@číslo) * 2,25061348918698E-06 Velký počet řádků: 1,35166186417734E-04 + @číslo * LOG(@číslo) * 6,62193536908588E-06 + @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Seskupení podle jednoho celočíselného sloupce s návratem MAX ( |
| Škálování | lineární | n log n | lineární |
| Počáteční I/O náklady | žádné | 0,0112613 | žádné |
| Počáteční náklady na CPU | žádné | ~ 0,0001 | 0,017749 |
Podle těchto vzorců ukazuje obrázek 5 způsob, jakým se každá ze strategií škáluje pro různé počty vstupních řádků, jako příklad používá pevný počet skupin 500.
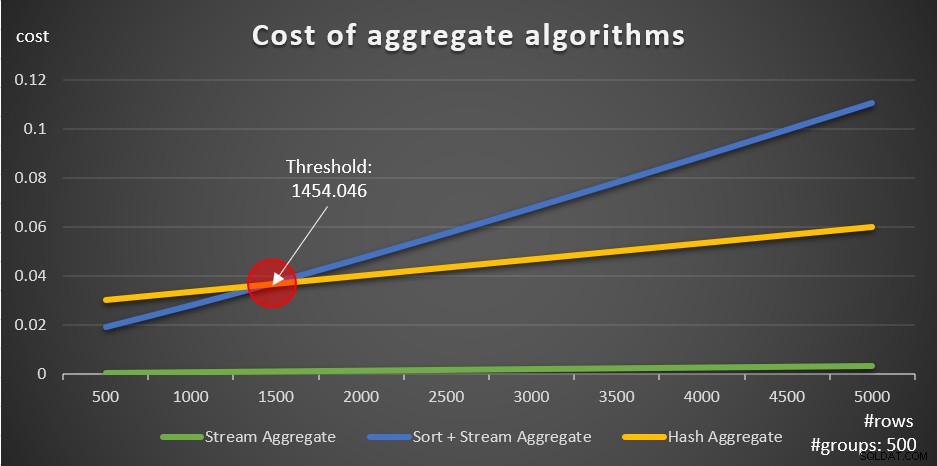
Obrázek 5:Náklady na agregované algoritmy
Jasně vidíte, že pokud jsou data předobjednána, např. v krycím indexu, je předobjednaná strategie Stream Aggregate tou nejlepší volbou, bez ohledu na to, kolik řádků se jedná. Předpokládejme například, že potřebujete dotaz na tabulku Objednávky a vypočítat maximální datum objednávky pro každého zaměstnance. Vytvoříte následující index pokrytí:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Zde je pět dotazů, které emulují tabulku Objednávky s různým počtem řádků (10 000, 20 000, 30 000, 40 000 a 50 000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Obrázek 6 ukazuje plány pro tyto dotazy.
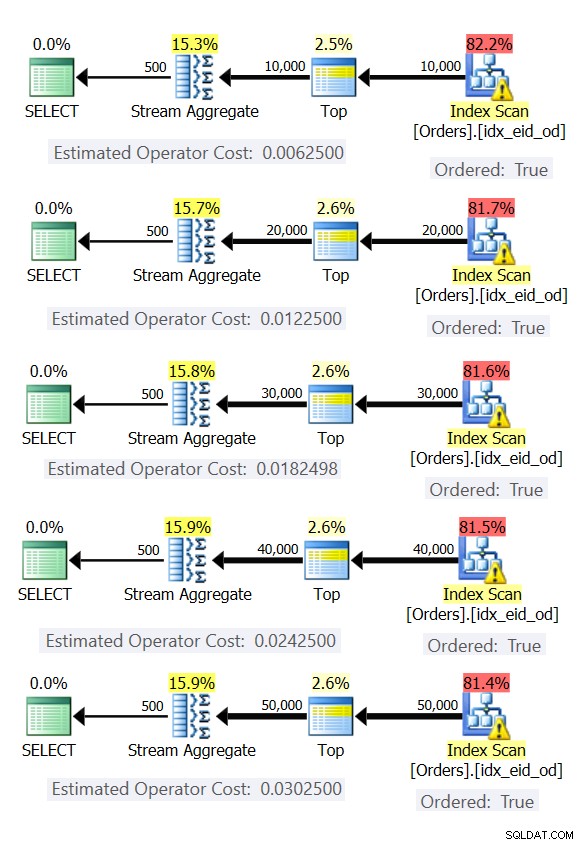
Obrázek 6:Plány s předobjednanou strategií Stream Aggregate
Ve všech případech plány provedou uspořádané skenování krycího indexu a použijí operátor Stream Aggregate bez nutnosti explicitního řazení.
Pomocí následujícího kódu zrušte index, který jste pro tento příklad vytvořili:
DROP INDEX idx_eid_od ON dbo.Orders;
Další důležitá věc, kterou je třeba poznamenat u grafů na obrázku 5, je to, co se stane, když data nejsou předobjednána. K tomu dochází, když není na místě žádný krycí index, a také když seskupujete podle manipulovaných výrazů na rozdíl od základních sloupců. Existuje práh optimalizace – v našem případě 1454 046 řádků – pod nímž má strategie Sort + Stream Aggregate nižší náklady a nad nímž má strategie Hash Aggregate nižší náklady. To souvisí se skutečností, že první má nižší spouštěcí náklady, ale škáluje se způsobem n log n, zatímco druhý má vyšší spouštěcí náklady, ale škáluje se lineárně. To činí první preferovaný s malým počtem vstupních řádků. Pokud jsou naše vzorce zpětného inženýrství přesné, měly by následující dva dotazy (nazývejte je Dotaz 10 a Dotaz 11) získat různé plány:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Plány pro tyto dotazy jsou znázorněny na obrázku 7.
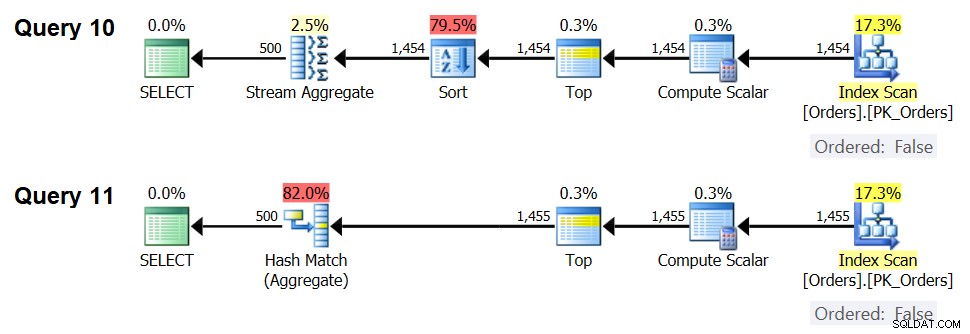
Obrázek 7:Plány pro Dotaz 10 a Dotaz 11
S 1 454 vstupními řádky (pod prahem optimalizace) optimalizátor přirozeně preferuje algoritmus Sort + Stream Aggregate pro Dotaz 10 a s 1 455 vstupními řádky (nad prahovou hodnotou optimalizace) optimalizátor přirozeně preferuje algoritmus Hash Aggregate pro Dotaz 11. .
Potenciál pro operátor Adaptive Aggregate
Jedním ze záludných aspektů optimalizačních prahů jsou problémy se sniffováním parametrů při použití dotazů citlivých na parametry v uložených procedurách. Zvažte následující uloženou proceduru jako příklad:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Pro podporu dotazu uložené procedury vytvoříte následující optimální index:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Vytvořili jste index s orderid jako klíčem pro podporu filtru rozsahu dotazu a zahrnuli jste empid pro pokrytí. Toto je situace, kdy ve skutečnosti nemůžete vytvořit index, který bude podporovat filtr rozsahu a bude mít filtrované řádky předřazené podle sady seskupení. To znamená, že optimalizátor si bude muset vybrat mezi algoritmy Sort + stream Aggregate a Hash Aggregate. Na základě našich kalkulačních vzorců je prahová hodnota optimalizace mezi 937 a 938 vstupními řádky (řekněme 937,5 řádků).
Předpokládejme, že provedete uloženou proceduru poprvé se vstupním ID počátečního příkazu, které vám poskytne malý počet shod (pod prahovou hodnotou):
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Server vytvoří plán, který používá algoritmus Sort + Stream Aggregate, a uloží plán do mezipaměti. Následná spuštění znovu použijí plán uložený v mezipaměti, bez ohledu na to, kolik řádků se týká. Například následující provedení má počet shod nad prahem optimalizace:
EXEC dbo.EmpOrders @initialorderid = 990001;
Přesto znovu používá plán uložený v mezipaměti, přestože pro toto provedení není optimální. To je klasický problém s čicháním parametrů.
SQL Server 2017 zavádí schopnosti adaptivního zpracování dotazů, které jsou navrženy tak, aby se vyrovnaly s takovými situacemi tím, že během provádění dotazu určí, jakou strategii použít. Mezi tato vylepšení patří operátor Adaptive Join, který během provádění určuje, zda se má aktivovat Loop nebo Hash algoritmus na základě vypočítaného prahu optimalizace. Náš souhrnný příběh žádá podobného operátora Adaptive Aggregate, který by si během provádění mohl vybrat mezi strategií Sort + Stream Aggregate a strategií Hash Aggregate na základě vypočítaného prahu optimalizace. Obrázek 8 znázorňuje pseudo plán založený na této myšlence.
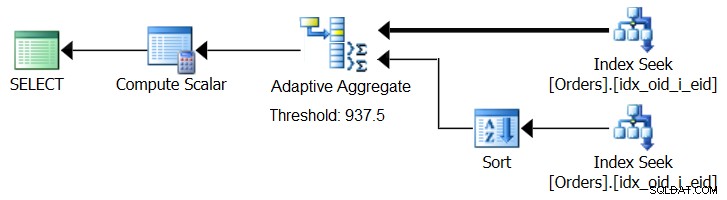
Obrázek 8:Pseudoplán s operátorem Adaptive Aggregate
Prozatím, abyste získali takový plán, musíte použít Microsoft Paint. Ale protože koncept adaptivního zpracování dotazů je tak chytrý a funguje tak dobře, je rozumné očekávat v budoucnu další vylepšení v této oblasti.
Spuštěním následujícího kódu zrušte index, který jste pro tento příklad vytvořili:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Závěr
V tomto článku jsem se zabýval kalkulací a škálováním algoritmu Hash Aggregate a porovnal jej se strategiemi Stream Aggregate a Sort + Stream Aggregate. Popsal jsem práh optimalizace, který existuje mezi strategiemi Sort + Stream Aggregate a Hash Aggregate. Při malém počtu vstupních řádků je preferován první a při velkém počtu druhý. Popsal jsem také potenciál pro přidání operátoru Adaptive Aggregate, podobného již implementovanému operátoru Adaptive Join, který pomůže řešit problémy s čicháním parametrů při použití dotazů citlivých na parametry. Příští měsíc budu v diskuzi pokračovat tím, že se budu věnovat úvahám o paralelismu a případům, které vyžadují přepsání dotazů.