V několika svých příspěvcích za poslední rok jsem použil téma lidí, kteří vidí určitý typ čekání a pak reagují „trhnutím kolena“ na to čekání. Obvykle to znamená řídit se špatnou internetovou radou a podniknout drastické, nevhodné kroky nebo udělat ukvapený závěr o tom, co je hlavní příčinou problému, a pak plýtvat časem a úsilím na honičku za divokou husou.
Jedním z typů čekání, kde jsou prudká reakce nejsilnější a kde existují některé z nejhorších rad, je čekání CXPACKET. Je to také typ čekání, který je nejčastějším typem čekání na serverech lidí (podle mých dvou velkých průzkumů typů čekání z let 2010 a 2014 – podrobnosti viz zde), takže se tomu budu věnovat v tomto příspěvku.
Co znamená typ čekání CXPACKET?
Nejjednodušším vysvětlením je, že CXPACKET znamená, že máte dotazy spuštěné paralelně a *vždy* uvidíte, že CXPACKET čeká na paralelní dotaz. Čekání CXPACKET NEZNAMENÁ, že máte problematický paralelismus – to musíte zjistit hlouběji.
Jako příklad paralelního operátoru zvažte operátor Repartition Streams, který má v grafických plánech dotazů následující ikonu:

A zde je obrázek, který ukazuje, co se děje z hlediska paralelních vláken pro tento operátor se stupněm paralelnosti (DOP) rovným 4:
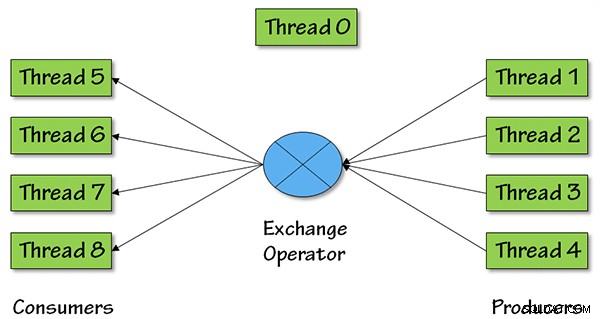
Pro DOP =4 budou existovat čtyři výrobní vlákna, která stahují data z dřívějšího plánu dotazů, data se poté vrátí do zbytku plánu dotazů prostřednictvím čtyř spotřebitelských vláken.
Různá vlákna v paralelním operátoru, která čekají na zdroj, můžete vidět pomocí sys.dm_os_waiting_tasks DMV, v exec_context_id sloupec (tento příspěvek obsahuje můj skript, jak to udělat).
Vždy existuje 'kontrolní' vlákno pro jakýkoli paralelní plán, které má historickou náhodou vždy ID vlákna 0. Řídicí vlákno vždy zaregistruje čekání CXPACKET s dobou trvání rovnající se délce doby, kterou trvá provedení plánu. Paul White má skvělé vysvětlení vláken v paralelních plánech zde.
Jediný čas, kdy nekontrolní vlákna zaregistrují čekání CXPACKET, je, pokud se dokončí dříve, než ostatní vlákna v operátoru. To se může stát, pokud se jedno z vláken zasekne při čekání na zdroj po dlouhou dobu, takže se podívejte, jaký je typ čekání u vlákna, které nezobrazuje CXPACKET (pomocí mého skriptu výše) a odpovídajícím způsobem odstraňte problém. To se také může stát kvůli zkreslené distribuci práce mezi vlákny a tomuto případu půjdu více do hloubky v mém dalším příspěvku zde (je to způsobeno zastaralými statistikami a dalšími problémy s odhadem mohutnosti).
Všimněte si, že v SQL Server 2016 SP2 a SQL Server 2017 RTM CU3 již spotřebitelská vlákna neregistrují čekání CXPACKET. Registrují čekání CXCONSUMER, které jsou neškodné a lze je ignorovat. Tím se sníží počet generovaných čekání na CXPACKET a u zbývajících je pravděpodobnější, že budou použitelné.
Neočekávaný paralelismus?
Vzhledem k tomu, že CXPACKET jednoduše znamená, že dochází k paralelismu, je první věcí, na kterou je třeba se podívat, zda očekáváte paralelismus pro dotaz, který jej používá. Můj dotaz vám poskytne ID uzlu plánu dotazů, kde dochází k paralelismu (vytáhne ID uzlu z plánu dotazů XML, pokud je typ čekání vlákna CXPACKET), takže vyhledejte toto ID uzlu a zjistěte, zda má paralelismus smysl .
Jedním z běžných případů neočekávaného paralelismu je situace, kdy ke skenování tabulky dojde tam, kde očekáváte menší index hledání nebo skenování. Buď to uvidíte v plánu dotazů, nebo uvidíte spoustu čekání PAGEIOLATCH_SH (podrobně probráno zde) spolu s čekáním CXPACKET (klasický vzor statistiky čekání, na který je třeba dávat pozor). Existuje celá řada příčin neočekávaných prohledávání tabulek, včetně:
- Chybí neklastrovaný index, takže jedinou alternativou je prohledání tabulky
- Zastaralé statistiky, takže Optimalizátor dotazů považuje skenování tabulky za nejlepší metodu přístupu k datům.
- Implicitní převod z důvodu neshody datového typu mezi sloupcem tabulky a proměnnou nebo parametrem, což znamená, že nelze použít neshlukovaný index.
- Aritmetika se provádí ve sloupci tabulky namísto proměnné nebo parametru, což znamená, že nelze použít neshlukovaný index
Ve všech těchto případech je řešení diktováno tím, co považujete za hlavní příčinu.
Ale co když neexistuje žádný zřejmý kořenový případ a dotaz je prostě považován za dostatečně drahý, aby zaručoval paralelní plán?
Zabránění paralelismu
Mimo jiné se nástroj Query Optimizer rozhodne vytvořit plán paralelních dotazů, pokud má sériový plán vyšší cenu, než je cost threshold for parallelism , nastavení sp_configure pro instanci. Prahová hodnota nákladů pro paralelismus (neboli CTFP) je ve výchozím nastavení nastavena na pět, což znamená, že plán nemusí být příliš drahý, aby spustil vytvoření paralelního plánu.
Jedním z nejjednodušších způsobů, jak zabránit nežádoucímu paralelismu, je zvýšit CTFP na mnohem vyšší číslo, přičemž čím vyšší hodnotu nastavíte, tím menší je pravděpodobnost vytvoření paralelních plánů. Někteří lidé obhajují nastavení CTFP někde mezi 25 a 50, ale stejně jako u všech vyladitelných nastavení je nejlepší otestovat různé hodnoty a zjistit, co nejlépe vyhovuje vašemu prostředí. Pokud byste chtěli trochu více programové metody, která by vám pomohla vybrat dobrou hodnotu CTFP, Jonathan napsal blogový příspěvek s dotazem na analýzu mezipaměti plánu a vytvoření navrhované hodnoty pro CTFP. Jako příklad máme jednoho klienta s CTFP nastaveným na 200 a dalšího nastaveného na maximum – 32767 – jako způsob, jak násilně zabránit jakémukoli paralelismu.
Možná se divíte, proč druhý klient musel použít CTFP jako metodu zabraňující paralelismu, když si myslíte, že mohl jednoduše nastavit server „maximální stupeň paralelismu“ (nebo MAXDOP) na 1. Každý s jakoukoli úrovní oprávnění může zadejte nápovědu MAXDOP dotazu a přepište nastavení MAXDOP serveru, ale CTFP nelze přepsat.
A to je další metoda omezení paralelismu – nastavení nápovědy MAXDOP na dotaz, který nechcete používat paralelně.
Můžete také snížit nastavení MAXDOP serveru, ale to je drastické řešení, protože může všemu zabránit v používání paralelismu. V dnešní době je běžné, že servery mají smíšenou pracovní zátěž, například s některými dotazy OLTP a některými dotazy na vytváření sestav. Pokud snížíte MAXDOP serveru, snížíte výkon dotazů na vytváření sestav.
Lepším řešením při smíšené zátěži by bylo použít CTFP, jak jsem popsal výše, nebo použít Resource Governor (obávám se, že je to pouze Enterprise). Pomocí nástroje Resource Governor můžete rozdělit pracovní zátěže do skupin úloh a poté pro každou skupinu zátěže nastavit MAX_DOP (podtržítko není překlep). A dobrá věc na použití Resource Governor je, že MAX_DOP nelze přepsat nápovědou k dotazu MAXDOP.
Shrnutí
Nenechte se chytit do pasti myšlenek, že CXPACKET automaticky čeká, znamená to, že máte špatný paralelismus, a rozhodně se neřiďte některými internetovými radami, které jsem viděl, jak uhodit server nastavením MAXDOP na 1. Udělejte si čas abyste prozkoumali, proč se vám zobrazuje čekání CXPACKET a zda je to něco, co je třeba řešit, nebo jen artefakt pracovní zátěže, která běží správně.
Pokud jde o obecné statistiky čekání, více informací o jejich použití pro odstraňování problémů s výkonem naleznete v:
- Moje série příspěvků na blogu SQLskills, počínaje statistikou čekání, nebo mi prosím řekněte, kde to bolí
- Moje knihovna typů čekání a tříd Latch zde
- Online školicí kurz My Pluralsight SQL Server:Odstraňování problémů s výkonem pomocí statistiky čekání
- Poradce pro výkon SQL Sentry
V dalším článku série proberu zkosený paralelismus a dám vám jednoduchý způsob, jak to vidět. Do té doby přejeme hodně štěstí při odstraňování problémů!