Pracujete s vývojářem, který hlásí pomalý výkon pro následující volání uložené procedury:
EXEC [dbo].[charge_by_date] '2/28/2013';
Ptáte se, jaký problém vývojář vidí, ale jediná další informace, kterou uslyšíte, je, že „běží pomalu“. Takže skočíte na instanci SQL Server a podíváte se na aktuální exekuční plán. Děláte to, protože vás zajímá nejen to, jak vypadá plán provádění, ale také jaký je odhadovaný a skutečný počet řádků plánu:
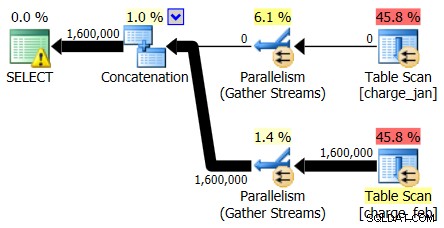
Nejprve se podíváte na operátory plánu a uvidíte několik pozoruhodných detailů:
- V kořenovém operátoru je varování
- Existuje prohledání tabulek pro obě tabulky, na které se odkazuje na úrovni listu (charge_jan a charge_feb) a vy se divíte, proč jsou obě stále hromady a nemají seskupené indexy
- Vidíte, že tabulkou charge_feb procházejí pouze řádky, nikoli tabulkou charge_jan
- V plánu vidíte paralelní zóny
Pokud jde o varování v kořenovém iterátoru, najedete na něj a uvidíte, že chybí varování indexu s doporučením pro následující indexy:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Zeptáte se původního vývojáře databáze, proč neexistuje seskupený index, a odpověď je „Nevím.“
Pokračujte ve vyšetřování před provedením jakýchkoli změn a podíváte se na kartu Plan Tree v SQL Sentry Plan Explorer a skutečně uvidíte, že mezi odhadovanými a skutečnými řádky jedné z tabulek jsou značné odchylky:

Zdá se, že existují dva problémy:
- Podhodnocený odhad pro řádky v prohledání tabulky charge_jan
- Nadhodnocení pro řádky v prohledání tabulky charge_feb
Takže odhady mohutnostijsou zkosený a přemýšlíte, jestli to souvisí s čicháním parametrů. Rozhodnete se zkontrolovat zkompilovanou hodnotu parametru a porovnat ji s hodnotou parametru za běhu, kterou můžete vidět na kartě Parametry:

Skutečně existují rozdíly mezi hodnotou za běhu a zkompilovanou hodnotou. Zkopírujete databázi do testovacího prostředí podobného produktu a poté otestujete provedení uložené procedury s hodnotou runtime 2/28/2013 a poté 31/1/2013.
Plány z 28. 2. 2013 a 31. 1. 2013 mají identické tvary, ale odlišné skutečné datové toky. Plán a odhady mohutnosti k 28. 2. 2013 byly následující:
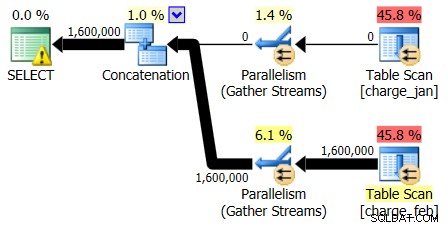

A zatímco plán 28. 2. 2013 nevykazuje žádný problém s odhadem mohutnosti, plán 31. 1. 2013 ano:
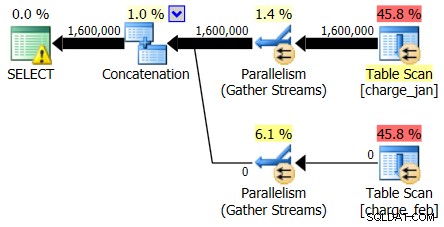

Takže druhý plán ukazuje totéž nad a podhodnocením, jen obráceně oproti původnímu plánu, na který jste se dívali.
Rozhodnete se přidat navrhované indexy do testovacího prostředí podobného prod pro tabulky charge_jan i charge_feb a uvidíte, zda to vůbec pomůže. Po provedení uložených procedur v pořadí leden/únor uvidíte následující nové tvary plánu a související odhady mohutnosti:
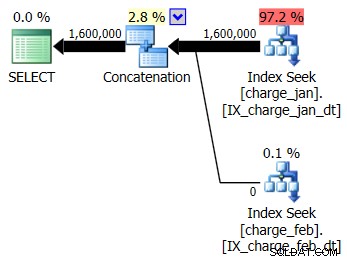

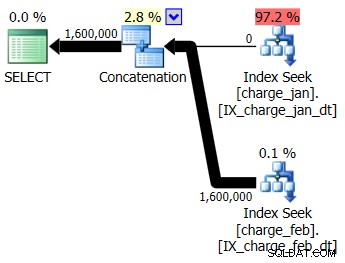

Nový plán používá operaci Index Seek z každé tabulky, ale stále vidíte, že z jedné tabulky plyne nula řádků a z druhé ne, a stále vidíte zkreslení odhadu mohutnosti na základě sniffování parametrů, když je hodnota za běhu v jiném měsíci od kompilace. časová hodnota.
Váš tým má zásadu nepřidávat indexy bez prokázání dostatečného přínosu a souvisejícího regresního testování. Rozhodnete se prozatím odstranit neklastrované indexy, které jste právě vytvořili. Zatímco chybějící seskupené hned neřešíte index, rozhodnete se, že se o to postaráte později.
V tomto okamžiku si uvědomíte, že se musíte dále podívat na definici uložené procedury, která je následující:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Dále se podíváte na definici objektu charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Zobrazení odkazuje na údaje o poplatcích, které jsou rozděleny do různých tabulek podle data. A pak se ptáte, zda lze zabránit zkreslení plánu provádění druhého dotazu změnou definice uložené procedury.
Pokud bude optimalizátor za běhu vědět, jaká je hodnota, problém s odhadem mohutnosti zmizí a zlepší se celkový výkon?
Pokračujte a předefinujte volání uložené procedury následovně a přidejte nápovědu RECOMPILE (s vědomím, že jste také slyšeli, že to může zvýšit využití CPU, ale protože se jedná o testovací prostředí, můžete to zkusit):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Poté znovu spustíte uloženou proceduru pomocí hodnoty 31. 1. 2013 a poté hodnoty 28. 2. 2013.
Tvar plánu zůstává stejný, ale problém s odhadem mohutnosti je nyní odstraněn.
Údaje odhadu mohutnosti k 31. 1. 2013 ukazují:

A údaje o odhadu mohutnosti z 28. 2. 2013 ukazují:

To vás na okamžik potěší, ale pak si uvědomíte, že trvání celkového provádění dotazu se zdá relativně stejné jako předtím. Začnete pochybovat, že vývojář bude s vašimi výsledky spokojený. Vyřešili jste zkreslení odhadu mohutnosti, ale bez očekávaného zvýšení výkonu si nejste jisti, zda jste pomohli nějakým smysluplným způsobem.
Právě v tomto okamžiku si uvědomíte, že plán provádění dotazu je pouze podmnožinou informací, které byste mohli potřebovat, a tak své prozkoumání dále rozšíříte pohledem na kartu Tabulka I/O. Zobrazí se následující výstup pro provedení 31. 1. 2013:

A pro provedení 28.2.2013 vidíte podobná data:

V tu chvíli vás zajímá, zda operace přístupu k datům pro obě tabulky jsou nezbytné v každém plánu. Pokud optimalizátor ví, že potřebujete pouze lednové řádky, proč vůbec přistupovat k únoru a naopak? Pamatujte také, že optimalizátor dotazů nemá žádné záruky, že neexistují skutečné řádky z ostatních měsíců ve „špatné“ tabulce, pokud takové záruky nebyly poskytnuty výslovně prostřednictvím omezení v tabulce samotné.
Zkontrolujete definice tabulek pomocí sp_help pro každou tabulku a nevidíte žádná omezení definovaná pro žádnou tabulku.
Takže jako test přidáte následující dvě omezení:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Znovu spustíte uložené procedury a uvidíte následující tvary plánu a odhady mohutnosti.
31.1.2013 provedení:
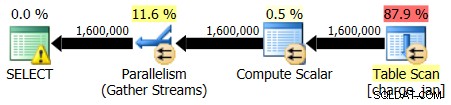

28.2.2013 provedení:


Když se znovu podíváte na tabulku I/O, uvidíte následující výstup pro provedení 31. ledna 2013:

A pro provedení 2/28/2013 vidíte podobná data, ale pro tabulku charge_feb:

Pamatujte si, že máte REKOMPILOVAT stále v definici uložené procedury, pokusíte se ji odebrat a uvidíte, zda uvidíte stejný efekt. Po provedení tohoto postupu uvidíte návrat přístupu ke dvěma tabulkám, ale bez skutečných logických čtení pro tabulku, která v ní nemá žádné řádky (ve srovnání s původním plánem bez omezení). Například provedení 31. 1. 2013 ukázalo následující I/O výstup tabulky:

Rozhodnete se pokročit v zátěžovém testování nových omezení CHECK a RECOMPILE, přičemž zcela odstraníte přístup k tabulce z plánu (a souvisejících operátorů plánu). Připravte se také na debatu o seskupeném indexovém klíči a vhodném podpůrném neklastrovaném indexu, který pojme širší sadu úloh, které aktuálně přistupují k přidruženým tabulkám.