O vlastnosti Skutečné čtení řádků jsem psal dříve. Říká vám, kolik řádků je skutečně přečteno hledáním indexu, takže můžete vidět, jak selektivní je predikát hledání ve srovnání se selektivitou predikátu hledání plus reziduální predikát dohromady.
Pojďme se ale podívat na to, co se vlastně děje uvnitř operátora Seek. Protože nejsem přesvědčen, že „Aktuální řádky přečteny“ je nutně přesný popis toho, co se děje.
Chci se podívat na příklad, který se dotazuje na adresy konkrétních typů adres pro zákazníka, ale zde uvedený princip by se snadno použil v mnoha jiných situacích, pokud by tvar vašeho dotazu vyhovoval, jako je vyhledávání atributů v tabulce párů klíč-hodnota, například.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Vím, že jsem vám neukázal nic o metadatech – vrátím se k tomu za chvíli. Pojďme se zamyslet nad tímto dotazem a nad tím, jaký druh indexu bychom pro něj chtěli mít.
Za prvé, přesně známe CustomerID. Shoda rovnosti, jako je tato, z něj obecně dělá vynikajícího kandidáta na první sloupec v indexu. Pokud bychom měli v tomto sloupci index, mohli bychom se ponořit přímo do adres tohoto zákazníka – takže bych řekl, že je to bezpečný předpoklad.
Další věcí, kterou je třeba zvážit, je filtr na AddressTypeID. Přidání druhého sloupce do klíčů našeho indexu je naprosto rozumné, tak to udělejme. Náš index je nyní zapnutý (CustomerID, AddressTypeID). A zahrňme také FullAddress, takže k dokončení obrázku nemusíme provádět žádné vyhledávání.
A myslím, že máme hotovo. Měli bychom být schopni bezpečně předpokládat, že ideální index pro tento dotaz je:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Potenciálně bychom jej mohli prohlásit za jedinečný index – na jeho dopad se podíváme později.
Vytvořme si tedy tabulku (používám tempdb, protože nepotřebuji, aby přetrvávala i mimo tento blogový příspěvek) a otestujeme to.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Nezajímají mě omezení cizích klíčů nebo jaké další sloupce tam mohou být. Zajímá mě pouze můj ideální index. Vytvořte si ho také, pokud jste to ještě neudělali.
Můj plán se zdá docela dokonalý.
Mám index search a je to.
Je pravda, že nejsou žádná data, takže se nečte, žádný procesor a běží to také docela rychle. Kéž by všechny dotazy mohly být vyladěny tak dobře jako toto.
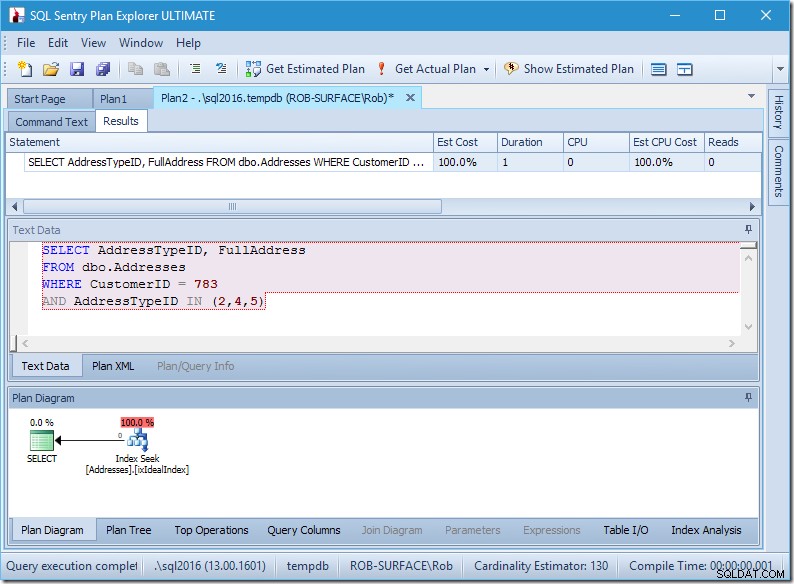
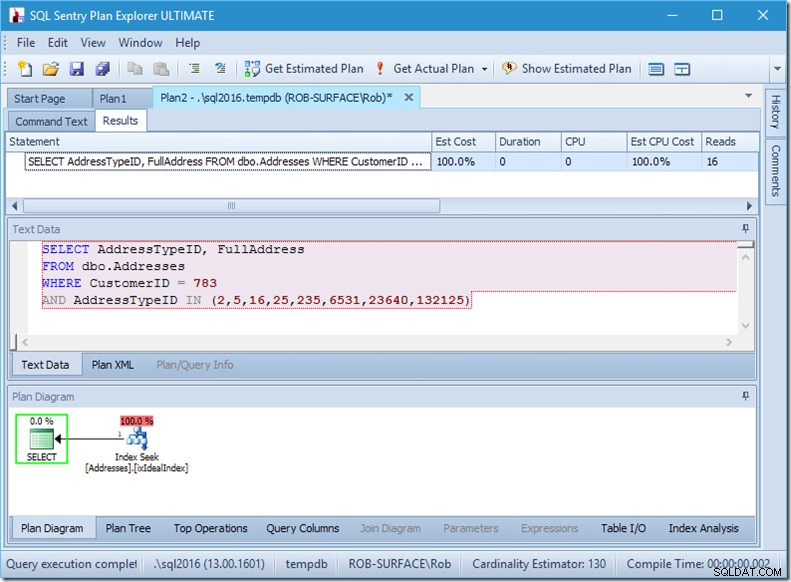
Pojďme se podívat, co se děje, trochu blíže, když se podíváme na vlastnosti Seek.
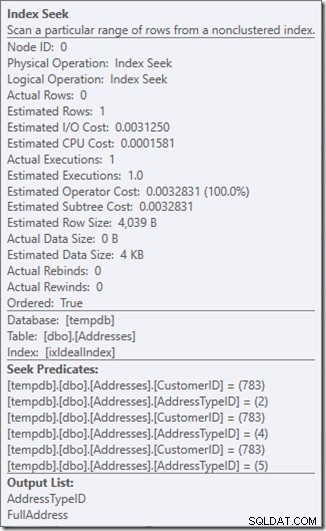
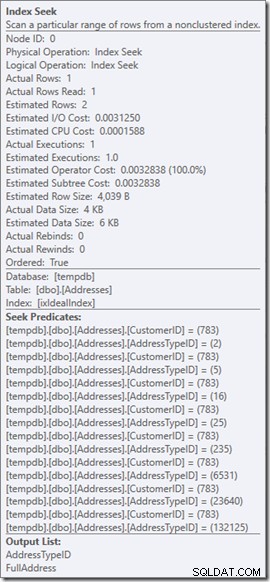
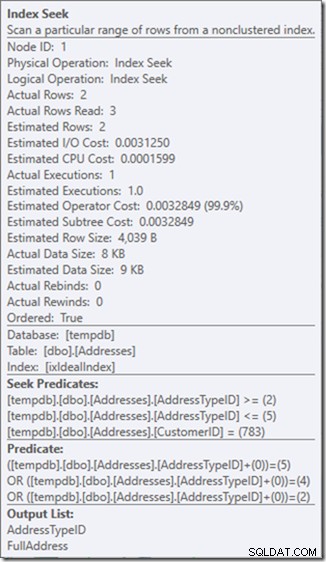
Můžeme vidět predikáty Seek. Je jich šest. Tři o CustomerID a tři o AddressTypeID. Ve skutečnosti zde máme tři sady predikátů hledání, které označují tři operace hledání v rámci jediného operátoru hledání. První hledání hledá zákazníka 783 a AddressType 2. Druhé hledá 783 a 4 a poslední 783 a 5. Náš operátor hledání se objevil jednou, ale v něm probíhaly tři hledání.
Nemáme ani data, ale můžeme vidět, jak bude náš index používán.
Vložme sem nějaká fiktivní data, abychom se mohli podívat na některé dopady tohoto. Vložím adresy pro typy 1 až 6. Každý zákazník (více než 2000, na základě velikosti master..spt_values ) bude mít adresu typu 1. Možná je to primární adresa. Nechám 80 % adres typu 2, 60 % typu 3 a tak dále, až 20 % pro typ 5. Řádek 783 získá adresy typu 1, 2, 3 a 4, ale ne 5. Raději bych šel s náhodnými hodnotami, ale chci se ujistit, že v příkladech jsme na stejné stránce.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Nyní se podívejme na náš dotaz s daty. Vycházejí dvě řady. Je to jako předtím, ale nyní vidíme dva řádky vycházející z operátoru Seek a vidíme šest čtení (vpravo nahoře).
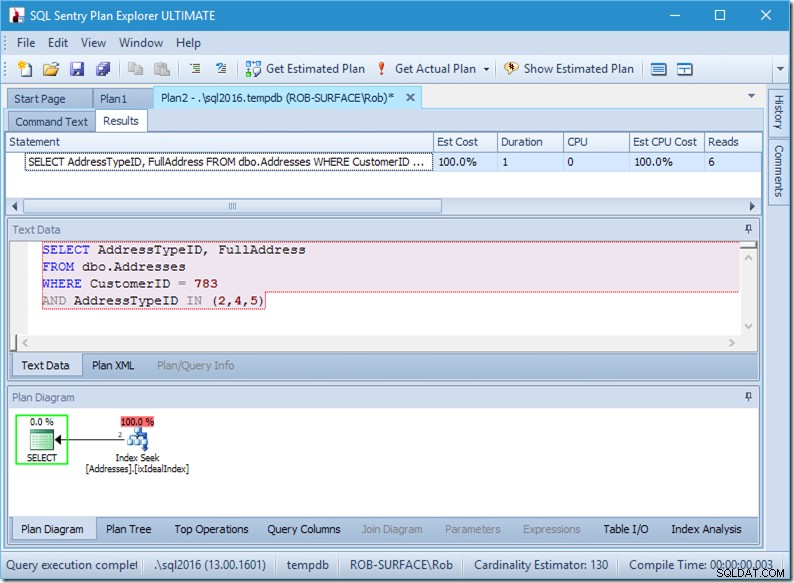
Šest přečtení mi dává smysl. Máme malý stůl a index se vejde jen na dvě úrovně. Provádíme tři hledání (v rámci našeho jednoho operátora), takže engine čte kořenovou stránku, zjišťuje, na kterou stránku jít dolů a čte ji, a to třikrát.
Pokud bychom hledali pouze dvě AddressTypeID, viděli bychom pouze 4 čtení (a v tomto případě výstup jednoho řádku). Výborně.
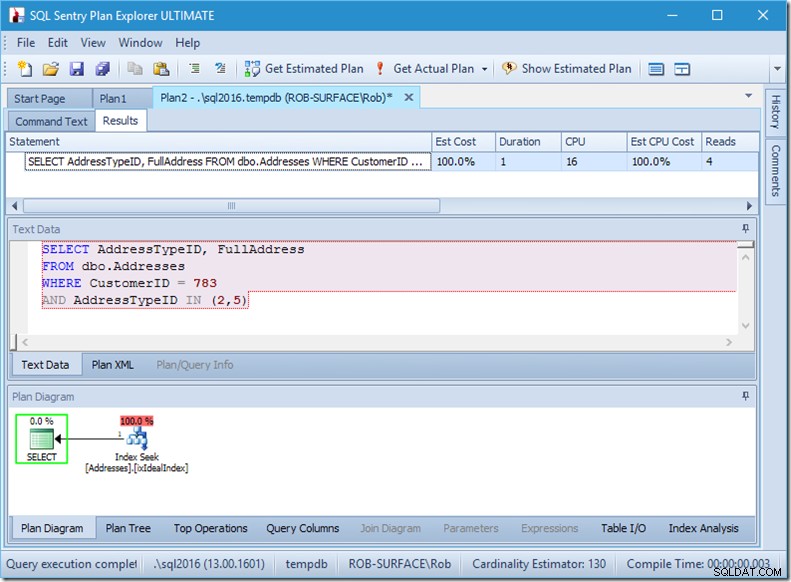
A pokud bychom hledali 8 typů adres, viděli bychom 16.
Přesto každý z nich ukazuje, že přečtené skutečné řádky přesně odpovídají skutečným řádkům. Žádná neefektivita!
Vraťme se k našemu původnímu dotazu, hledáme typy adres 2, 4 a 5 (které vrací 2 řádky) a zamysleme se nad tím, co se děje uvnitř hledání.
Budu předpokládat, že Query Engine již udělal práci, aby zjistil, že hledání indexu je správná operace a že má po ruce číslo stránky kořenového adresáře indexu.
V tomto okamžiku načte stránku do paměti, pokud tam ještě není. To je první čtení, které se započítává při provádění hledání. Potom najde číslo stránky pro řádek, který hledá, a přečte tuto stránku. To je druhé čtení.
Ale často zapomínáme na to, že „vyhledá číslo stránky“.
Pomocí DBCC IND(2, N'dbo.Address', 2); (první 2 je id databáze, protože používám tempdb; druhý 2 je id indexu ixIdealIndex ), mohu zjistit, že 712 v souboru 1 je stránka s nejvyšší IndexLevel. Na níže uvedeném snímku obrazovky vidím, že stránka 668 je IndexLevel 0, což je kořenová stránka.

Nyní tedy mohu použít DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); zobrazit obsah stránky 712. Na mém počítači se mi vrací 84 řádků a mohu říci, že CustomerID 783 bude na straně 1004 souboru 5.
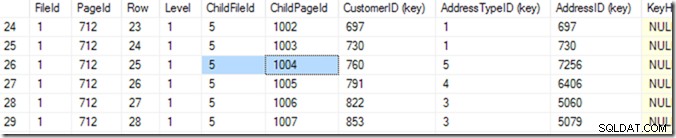
Ale poznám to tak, že listuji v seznamu, dokud neuvidím ten, který chci. Začal jsem tím, že jsem trochu posouval dolů a pak jsem se vrátil nahoru, dokud jsem nenašel řádek, který jsem chtěl. Počítač tomu říká binární vyhledávání a je o něco přesnější než já. Hledá řádek, kde je kombinace (CustomerID, AddressTypeID) menší než ten, který hledám, přičemž další stránka je větší nebo stejná jako ona. Říkám „stejně“, protože by se mohly shodovat dvě, rozložené na dvou stránkách. Ví, že na této stránce je 84 řádků (0 až 83) dat (přečte to v záhlaví stránky), takže začne kontrolou řádku 41. Odtud ví, ve které polovině má hledat, a (v v tomto příkladu), přečte řádek 20. Několik dalších čtení (celkem tedy 6 nebo 7)* a ví, že řádek 25 (pro tuto hodnotu se podívejte do sloupce s názvem 'Řádek', nikoli do čísla řádku poskytnutého SSMS ) je příliš malý, ale řádek 26 je příliš velký – takže řešením je 25!
*Při binárním vyhledávání může být vyhledávání o něco rychlejší, pokud má štěstí, když rozdělí blok na dva, pokud neexistuje prostřední slot, a v závislosti na tom, zda lze prostřední slot odstranit nebo ne.
Nyní může přejít na stránku 1004 v souboru 5. Použijme na ní DBCC PAGE.
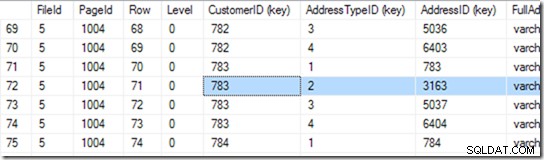
Tohle mi dává 94 řádků. Provede další binární vyhledávání, aby našel začátek rozsahu, který hledá. Aby to našel, musí se podívat přes 6 nebo 7 řádků.
"Začátek řady?" Slyším, že se ptáš. Ale hledáme adresu typu 2 zákazníka 783.
Správně, ale tento index jsme nedeklarovali jako jedinečný. Takže mohou být dva. Pokud je jedinečný, může hledání provést jednotónové vyhledávání a mohlo by na něj během binárního hledání narazit, ale v tomto případě musí dokončit binární hledání, aby našel první řádek v rozsahu. V tomto případě je to řádek 71.
Zde ale nekončíme. Nyní musíme zjistit, zda skutečně existuje druhý! Přečte tedy i řádek 72 a zjistí, že pár CustomerID+AddressTypeiD je skutečně příliš velký a jeho hledání je hotovo.
A to se stane třikrát. Potřetí nenajde řádek pro zákazníka 783 a typ adresy 5, ale neví to předem a stále potřebuje dokončit hledání.
Takže řádků, které jsou ve skutečnosti čteny v těchto třech hledáních (k nalezení dvou řádků k výstupu), je mnohem více než vrácený počet. Je jich asi 7 na úrovni indexu 1 a dalších asi 7 na úrovni listu, abychom našli začátek rozsahu. Potom přečte řádek, na kterém nám záleží, a poté řádek po něm. To mi zní spíš jako 16 a dělá to třikrát, takže asi 48 řádků.
Skutečné čtení řádků však není o počtu skutečně přečtených řádků, ale o počtu řádků vrácených predikátem hledání, které jsou testovány proti zbytkovému predikátu. A v tom jsou to pouze 2 řádky, které najdou 3 hledání.
Možná si v tuto chvíli myslíte, že je zde určitá míra neúčinnosti. Druhé hledání by také přečetlo stránku 712, zkontrolovalo tam stejných 6 nebo 7 řádků a pak by přečetlo stránku 1004 a prohledalo ji… stejně jako třetí hledání.
Možná by tedy bylo lepší to získat při jediném hledání a přečíst si stránku 712 a stránku 1004 pouze jednou. Koneckonců, kdybych to dělal s papírovým systémem, snažil bych se najít zákazníka 783 a pak bych prohledal všechny jejich typy adres. Protože vím, že zákazník nemívá mnoho adres. To je výhoda, kterou mám oproti databázovému stroji. Databázový stroj prostřednictvím svých statistik ví, že hledání bude nejlepší, ale neví, že hledání by mělo klesnout pouze o jednu úroveň, když může říct, že má něco, co vypadá jako ideální index.
Pokud změním svůj dotaz tak, aby získal řadu typů adres, od 2 do 5, dostanu téměř takové chování, jaké chci:
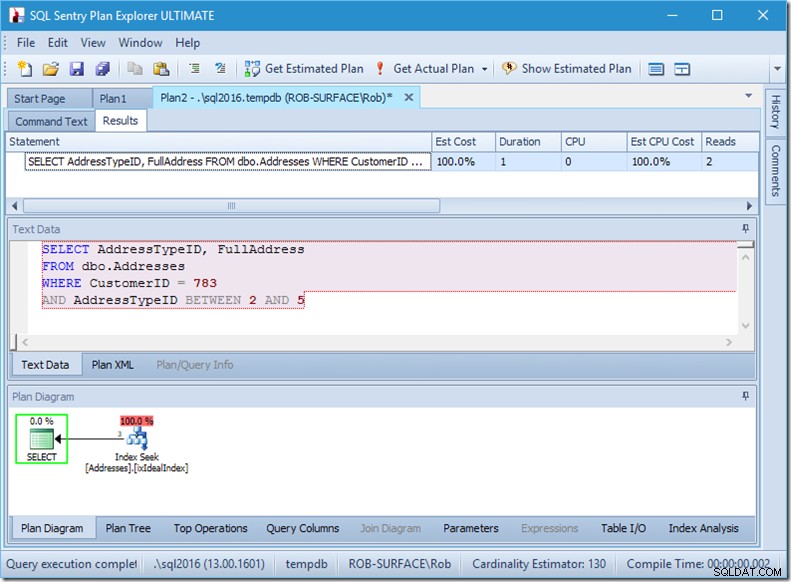
Podívejte se – čtení je na 2 a já vím, které stránky to jsou…
…ale mé výsledky jsou špatné. Protože chci pouze adresy typu 2, 4 a 5, ne 3. Musím mu říct, aby neměl 3, ale musím si dávat pozor, jak to udělám. Podívejte se na následující dva příklady.
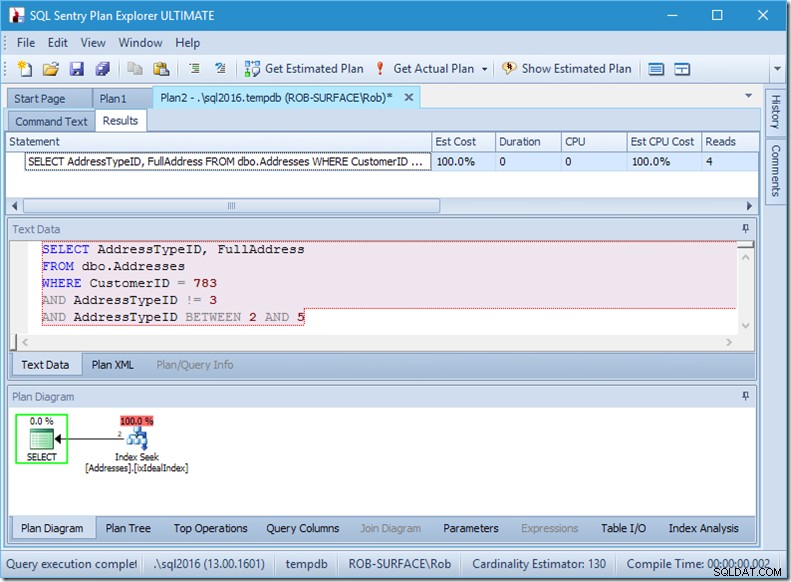
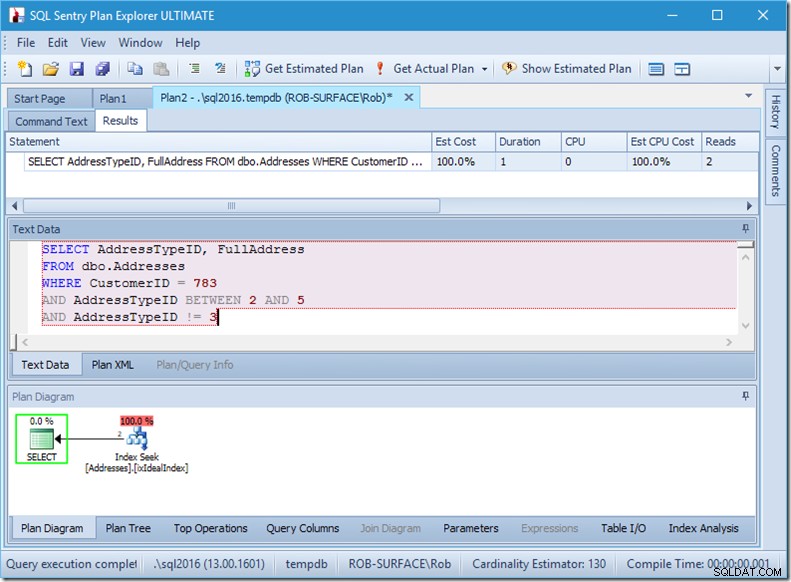
Mohu vás ujistit, že na predikátovém pořadí nezáleží, ale zde jednoznačně ano. Pokud dáme „ne 3“ jako první, provede dvě vyhledávání (4 čtení), ale pokud dáme „ne 3“ jako druhé, provede jedno vyhledávání (2 čtení).
Problém je v tom, že AddressTypeID !=3 se převede na (AddressTypeID> 3 NEBO AddressTypeID <3), což je pak považováno za dva velmi užitečné predikáty vyhledávání.
A tak preferuji použití nestárnutelného predikátu, abych mu řekl, že chci pouze typy adres 2, 4 a 5. A mohu to udělat úpravou AddressTypeID nějakým způsobem, například přidáním nuly.
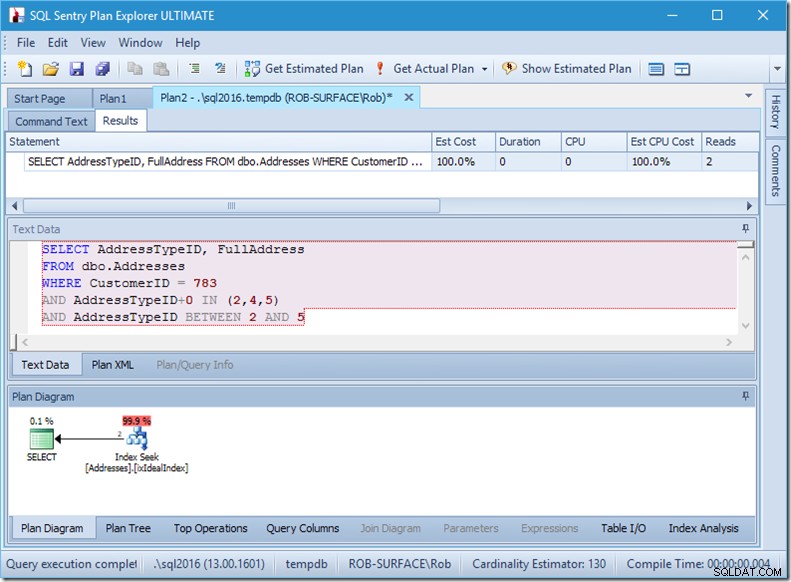
Nyní mám pěkný a úzký rozsah skenování v rámci jednoho hledání a stále se ujišťuji, že můj dotaz vrací pouze řádky, které chci.
Ale ta vlastnost Skutečné čtení řádků? To je nyní vyšší než vlastnost Actual Rows, protože predikát Seek najde adresu typu 3, kterou reziduální predikát odmítne.
Vyměnil jsem tři perfektní hledání za jeden nedokonalý, který opravuji zbytkovým predikátem.
A pro mě je to někdy cena, kterou stojí za to zaplatit, a získat tak plán dotazů, se kterým jsem mnohem šťastnější. Není výrazně levnější, i když má jen třetinu přečtení (protože fyzické přečtení by byly vždy jen dvě), ale když přemýšlím o práci, kterou dělá, mnohem víc mi vyhovuje, na co se ho ptám. udělat tímto způsobem.